 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAlgorithmic warm starts for Hamiltonian Monte Carlo
Mar 24, 2026Generating samples from a continuous probability density is a central algorithmic problem across statistics, engineering, and the sciences. For high-dimensional settings, Hamiltonian Monte Carlo (HMC) is the default algorithm across mainstream software packages. However, despite the extensive line of work on HMC and its widespread empirical success, it remains unclear how many iterations of HMC are required as a function of the dimension $d$. On one hand, a variety of results show that Metropolized HMC converges in $O(d^{1/4})$ iterations from a warm start close to stationarity. On the other hand, Metropolized HMC is significantly slower without a warm start, e.g., requiring $Ω(d^{1/2})$ iterations even for simple target distributions such as isotropic Gaussians. Finding a warm start is therefore the computational bottleneck for HMC. We resolve this issue for the well-studied setting of sampling from a probability distribution satisfying strong log-concavity (or isoperimetry) and third-order derivative bounds. We prove that \emph{non-Metropolized} HMC generates a warm start in $\tilde{O}(d^{1/4})$ iterations, after which we can exploit the warm start using Metropolized HMC. Our final complexity of $\tilde{O}(d^{1/4})$ is the fastest algorithm for high-accuracy sampling under these assumptions, improving over the prior best of $\tilde{O}(d^{1/2})$. This closes the long line of work on the dimensional complexity of MHMC for such settings, and also provides a simple warm-start prescription for practical implementations.
Negative Stepsizes Make Gradient-Descent-Ascent Converge
May 02, 2025Efficient computation of min-max problems is a central question in optimization, learning, games, and controls. Arguably the most natural algorithm is gradient-descent-ascent (GDA). However, since the 1970s, conventional wisdom has argued that GDA fails to converge even on simple problems. This failure spurred an extensive literature on modifying GDA with additional building blocks such as extragradients, optimism, momentum, anchoring, etc. In contrast, we show that GDA converges in its original form by simply using a judicious choice of stepsizes. The key innovation is the proposal of unconventional stepsize schedules (dubbed slingshot stepsize schedules) that are time-varying, asymmetric, and periodically negative. We show that all three properties are necessary for convergence, and that altogether this enables GDA to converge on the classical counterexamples (e.g., unconstrained convex-concave problems). All of our results apply to the last iterate of GDA, as is typically desired in practice. The core algorithmic intuition is that although negative stepsizes make backward progress, they de-synchronize the min and max variables (overcoming the cycling issue of GDA), and lead to a slingshot phenomenon in which the forward progress in the other iterations is overwhelmingly larger. This results in fast overall convergence. Geometrically, the slingshot dynamics leverage the non-reversibility of gradient flow: positive/negative steps cancel to first order, yielding a second-order net movement in a new direction that leads to convergence and is otherwise impossible for GDA to move in. We interpret this as a second-order finite-differencing algorithm and show that, intriguingly, it approximately implements consensus optimization, an empirically popular algorithm for min-max problems involving deep neural networks (e.g., training GANs).
Shifted Composition III: Local Error Framework for KL Divergence
Dec 23, 2024Coupling arguments are a central tool for bounding the deviation between two stochastic processes, but traditionally have been limited to Wasserstein metrics. In this paper, we apply the shifted composition rule--an information-theoretic principle introduced in our earlier work--in order to adapt coupling arguments to the Kullback-Leibler (KL) divergence. Our framework combine the strengths of two previously disparate approaches: local error analysis and Girsanov's theorem. Akin to the former, it yields tight bounds by incorporating the so-called weak error, and is user-friendly in that it only requires easily verified local assumptions; and akin to the latter, it yields KL divergence guarantees and applies beyond Wasserstein contractivity. We apply this framework to the problem of sampling from a target distribution $\pi$. Here, the two stochastic processes are the Langevin diffusion and an algorithmic discretization thereof. Our framework provides a unified analysis when $\pi$ is assumed to be strongly log-concave (SLC), weakly log-concave (WLC), or to satisfy a log-Sobolev inequality (LSI). Among other results, this yields KL guarantees for the randomized midpoint discretization of the Langevin diffusion. Notably, our result: (1) yields the optimal $\tilde O(\sqrt d/\epsilon)$ rate in the SLC and LSI settings; (2) is the first result to hold beyond the 2-Wasserstein metric in the SLC setting; and (3) is the first result to hold in \emph{any} metric in the WLC and LSI settings.
Shifted Interpolation for Differential Privacy
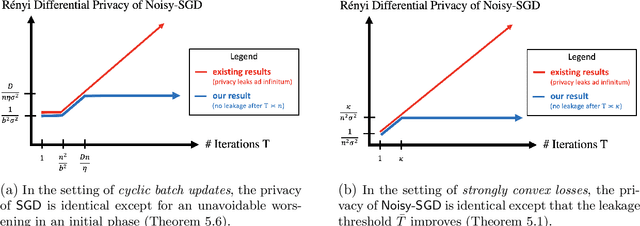
Mar 01, 2024Noisy gradient descent and its variants are the predominant algorithms for differentially private machine learning. It is a fundamental question to quantify their privacy leakage, yet tight characterizations remain open even in the foundational setting of convex losses. This paper improves over previous analyses by establishing (and refining) the "privacy amplification by iteration" phenomenon in the unifying framework of $f$-differential privacy--which tightly captures all aspects of the privacy loss and immediately implies tighter privacy accounting in other notions of differential privacy, e.g., $(\varepsilon,\delta)$-DP and Renyi DP. Our key technical insight is the construction of shifted interpolated processes that unravel the popular shifted-divergences argument, enabling generalizations beyond divergence-based relaxations of DP. Notably, this leads to the first exact privacy analysis in the foundational setting of strongly convex optimization. Our techniques extend to many settings: convex/strongly convex, constrained/unconstrained, full/cyclic/stochastic batches, and all combinations thereof. As an immediate corollary, we recover the $f$-DP characterization of the exponential mechanism for strongly convex optimization in Gopi et al. (2022), and moreover extend this result to more general settings.
Faster high-accuracy log-concave sampling via algorithmic warm starts
Feb 20, 2023
Understanding the complexity of sampling from a strongly log-concave and log-smooth distribution $\pi$ on $\mathbb{R}^d$ to high accuracy is a fundamental problem, both from a practical and theoretical standpoint. In practice, high-accuracy samplers such as the classical Metropolis-adjusted Langevin algorithm (MALA) remain the de facto gold standard; and in theory, via the proximal sampler reduction, it is understood that such samplers are key for sampling even beyond log-concavity (in particular, for distributions satisfying isoperimetric assumptions). In this work, we improve the dimension dependence of this sampling problem to $\tilde{O}(d^{1/2})$, whereas the previous best result for MALA was $\tilde{O}(d)$. This closes the long line of work on the complexity of MALA, and moreover leads to state-of-the-art guarantees for high-accuracy sampling under strong log-concavity and beyond (thanks to the aforementioned reduction). Our starting point is that the complexity of MALA improves to $\tilde{O}(d^{1/2})$, but only under a warm start (an initialization with constant R\'enyi divergence w.r.t. $\pi$). Previous algorithms took much longer to find a warm start than to use it, and closing this gap has remained an important open problem in the field. Our main technical contribution settles this problem by establishing the first $\tilde{O}(d^{1/2})$ R\'enyi mixing rates for the discretized underdamped Langevin diffusion. For this, we develop new differential-privacy-inspired techniques based on R\'enyi divergences with Orlicz--Wasserstein shifts, which allow us to sidestep longstanding challenges for proving fast convergence of hypocoercive differential equations.
Concentration of the Langevin Algorithm's Stationary Distribution
Dec 24, 2022A canonical algorithm for log-concave sampling is the Langevin Algorithm, aka the Langevin Diffusion run with some discretization stepsize $\eta > 0$. This discretization leads the Langevin Algorithm to have a stationary distribution $\pi_{\eta}$ which differs from the stationary distribution $\pi$ of the Langevin Diffusion, and it is an important challenge to understand whether the well-known properties of $\pi$ extend to $\pi_{\eta}$. In particular, while concentration properties such as isoperimetry and rapidly decaying tails are classically known for $\pi$, the analogous properties for $\pi_{\eta}$ are open questions with direct algorithmic implications. This note provides a first step in this direction by establishing concentration results for $\pi_{\eta}$ that mirror classical results for $\pi$. Specifically, we show that for any nontrivial stepsize $\eta > 0$, $\pi_{\eta}$ is sub-exponential (respectively, sub-Gaussian) when the potential is convex (respectively, strongly convex). Moreover, the concentration bounds we show are essentially tight. Key to our analysis is the use of a rotation-invariant moment generating function (aka Bessel function) to study the stationary dynamics of the Langevin Algorithm. This technique may be of independent interest because it enables directly analyzing the discrete-time stationary distribution $\pi_{\eta}$ without going through the continuous-time stationary distribution $\pi$ as an intermediary.
Resolving the Mixing Time of the Langevin Algorithm to its Stationary Distribution for Log-Concave Sampling
Oct 16, 2022
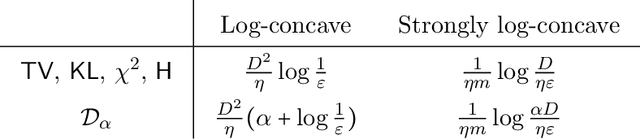
Sampling from a high-dimensional distribution is a fundamental task in statistics, engineering, and the sciences. A particularly canonical approach is the Langevin Algorithm, i.e., the Markov chain for the discretized Langevin Diffusion. This is the sampling analog of Gradient Descent. Despite being studied for several decades in multiple communities, tight mixing bounds for this algorithm remain unresolved even in the seemingly simple setting of log-concave distributions over a bounded domain. This paper completely characterizes the mixing time of the Langevin Algorithm to its stationary distribution in this setting (and others). This mixing result can be combined with any bound on the discretization bias in order to sample from the stationary distribution of the continuous Langevin Diffusion. In this way, we disentangle the study of the mixing and bias of the Langevin Algorithm. Our key insight is to introduce a technique from the differential privacy literature to the sampling literature. This technique, called Privacy Amplification by Iteration, uses as a potential a variant of R\'enyi divergence that is made geometrically aware via Optimal Transport smoothing. This gives a short, simple proof of optimal mixing bounds and has several additional appealing properties. First, our approach removes all unnecessary assumptions required by other sampling analyses. Second, our approach unifies many settings: it extends unchanged if the Langevin Algorithm uses projections, stochastic mini-batch gradients, or strongly convex potentials (whereby our mixing time improves exponentially). Third, our approach exploits convexity only through the contractivity of a gradient step -- reminiscent of how convexity is used in textbook proofs of Gradient Descent. In this way, we offer a new approach towards further unifying the analyses of optimization and sampling algorithms.
Privacy of Noisy Stochastic Gradient Descent: More Iterations without More Privacy Loss
May 27, 2022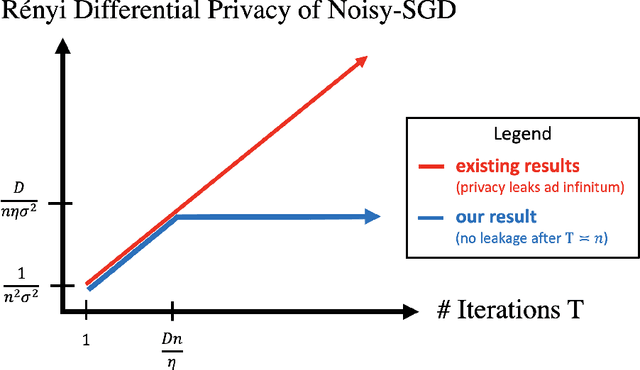
A central issue in machine learning is how to train models on sensitive user data. Industry has widely adopted a simple algorithm: Stochastic Gradient Descent with noise (a.k.a. Stochastic Gradient Langevin Dynamics). However, foundational theoretical questions about this algorithm's privacy loss remain open -- even in the seemingly simple setting of smooth convex losses over a bounded domain. Our main result resolves these questions: for a large range of parameters, we characterize the differential privacy up to a constant factor. This result reveals that all previous analyses for this setting have the wrong qualitative behavior. Specifically, while previous privacy analyses increase ad infinitum in the number of iterations, we show that after a small burn-in period, running SGD longer leaks no further privacy. Our analysis departs completely from previous approaches based on fast mixing, instead using techniques based on optimal transport (namely, Privacy Amplification by Iteration) and the Sampled Gaussian Mechanism (namely, Privacy Amplification by Sampling). Our techniques readily extend to other settings, e.g., strongly convex losses, non-uniform stepsizes, arbitrary batch sizes, and random or cyclic choice of batches.
Averaging on the Bures-Wasserstein manifold: dimension-free convergence of gradient descent
Jun 16, 2021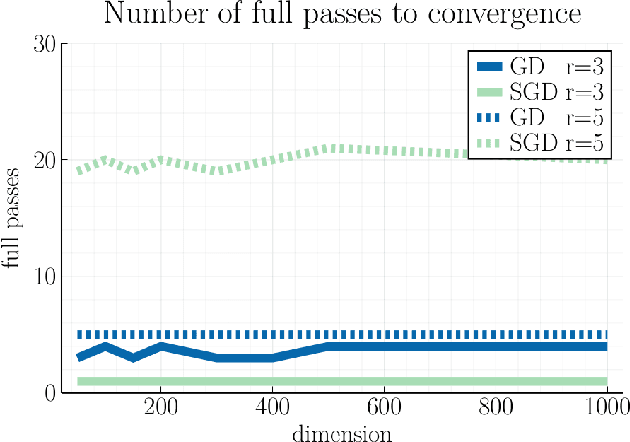
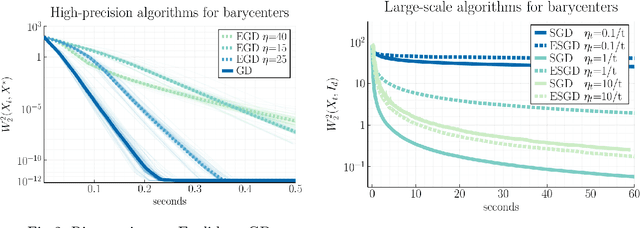
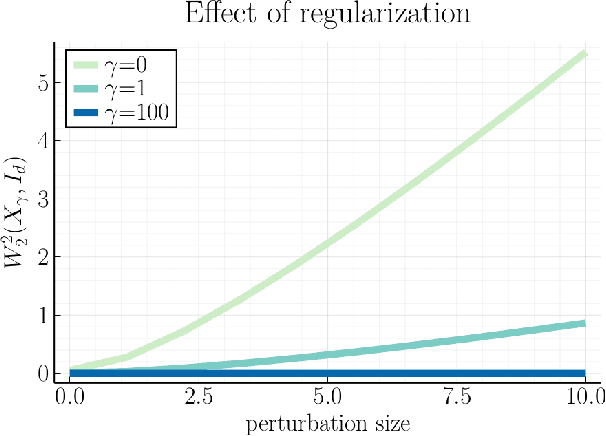
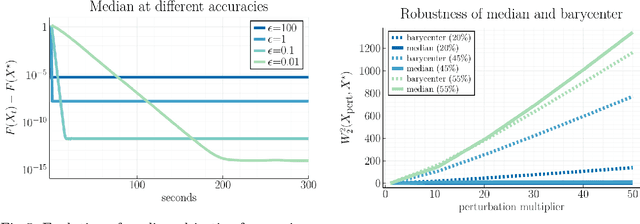
We study first-order optimization algorithms for computing the barycenter of Gaussian distributions with respect to the optimal transport metric. Although the objective is geodesically non-convex, Riemannian GD empirically converges rapidly, in fact faster than off-the-shelf methods such as Euclidean GD and SDP solvers. This stands in stark contrast to the best-known theoretical results for Riemannian GD, which depend exponentially on the dimension. In this work, we prove new geodesic convexity results which provide stronger control of the iterates, yielding a dimension-free convergence rate. Our techniques also enable the analysis of two related notions of averaging, the entropically-regularized barycenter and the geometric median, providing the first convergence guarantees for Riemannian GD for these problems.
Kernel approximation on algebraic varieties
Jun 04, 2021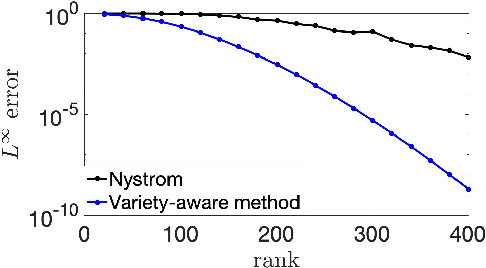

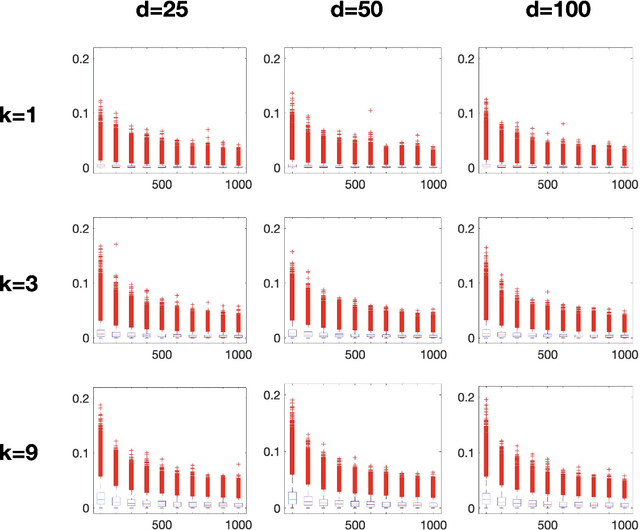
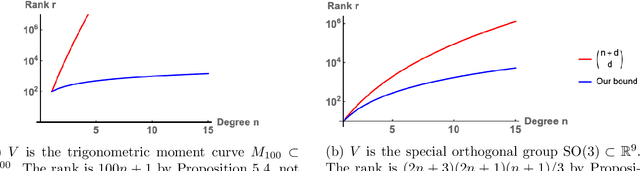
Low-rank approximation of kernels is a fundamental mathematical problem with widespread algorithmic applications. Often the kernel is restricted to an algebraic variety, e.g., in problems involving sparse or low-rank data. We show that significantly better approximations are obtainable in this setting: the rank required to achieve a given error depends on the variety's dimension rather than the ambient dimension, which is typically much larger. This is true in both high-precision and high-dimensional regimes. Our results are presented for smooth isotropic kernels, the predominant class of kernels used in applications. Our main technical insight is to approximate smooth kernels by polynomial kernels, and leverage two key properties of polynomial kernels that hold when they are restricted to a variety. First, their ranks decrease exponentially in the variety's co-dimension. Second, their maximum values are governed by their values over a small set of points. Together, our results provide a general approach for exploiting (approximate) "algebraic structure" in datasets in order to efficiently solve large-scale data science problems.