 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKernel approximation on algebraic varieties
Paper and Code
Jun 04, 2021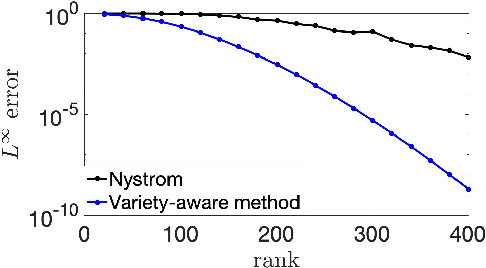

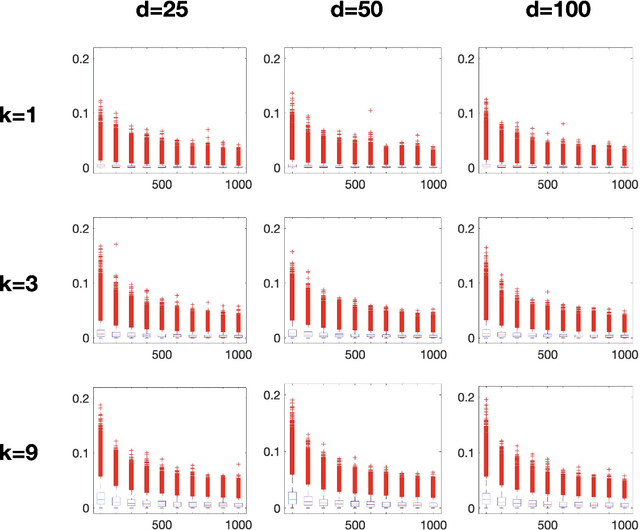
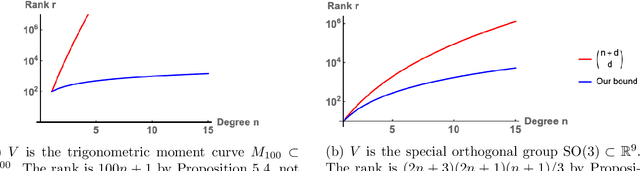
Low-rank approximation of kernels is a fundamental mathematical problem with widespread algorithmic applications. Often the kernel is restricted to an algebraic variety, e.g., in problems involving sparse or low-rank data. We show that significantly better approximations are obtainable in this setting: the rank required to achieve a given error depends on the variety's dimension rather than the ambient dimension, which is typically much larger. This is true in both high-precision and high-dimensional regimes. Our results are presented for smooth isotropic kernels, the predominant class of kernels used in applications. Our main technical insight is to approximate smooth kernels by polynomial kernels, and leverage two key properties of polynomial kernels that hold when they are restricted to a variety. First, their ranks decrease exponentially in the variety's co-dimension. Second, their maximum values are governed by their values over a small set of points. Together, our results provide a general approach for exploiting (approximate) "algebraic structure" in datasets in order to efficiently solve large-scale data science problems.