Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Rotation and a Translation Suffice: Fooling CNNs with Simple Transformations
Paper and Code

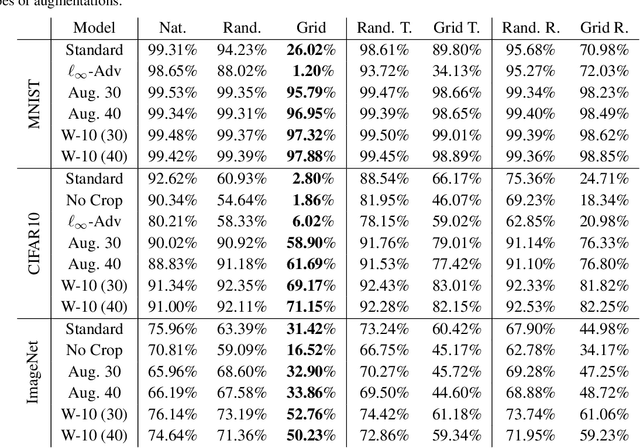
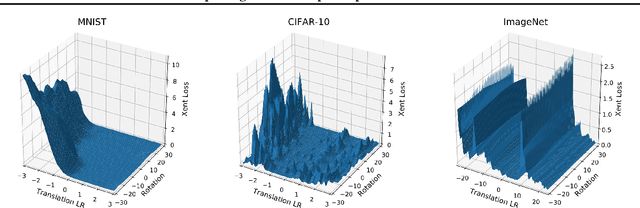
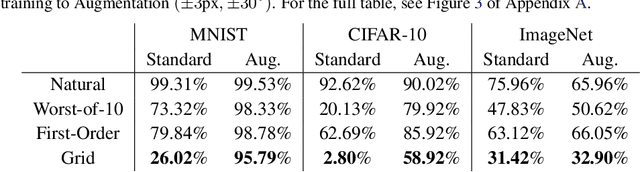
We show that simple transformations, namely translations and rotations alone, are sufficient to fool neural network-based vision models on a significant fraction of inputs. This is in sharp contrast to previous work that relied on more complicated optimization approaches that are unlikely to appear outside of a truly adversarial setting. Moreover, fooling rotations and translations are easy to find and require only a few black-box queries to the target model. Overall, our findings emphasize the need for designing robust classifiers even in natural, benign contexts.
* Preliminary version appeared in the NIPS 2017 Workshop on Machine
Learning and Computer Security
View paper on
 OpenReview
OpenReview