 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplicit Neural Representation in Medical Imaging: A Comparative Survey
Jul 30, 2023



Implicit neural representations (INRs) have gained prominence as a powerful paradigm in scene reconstruction and computer graphics, demonstrating remarkable results. By utilizing neural networks to parameterize data through implicit continuous functions, INRs offer several benefits. Recognizing the potential of INRs beyond these domains, this survey aims to provide a comprehensive overview of INR models in the field of medical imaging. In medical settings, numerous challenging and ill-posed problems exist, making INRs an attractive solution. The survey explores the application of INRs in various medical imaging tasks, such as image reconstruction, segmentation, registration, novel view synthesis, and compression. It discusses the advantages and limitations of INRs, highlighting their resolution-agnostic nature, memory efficiency, ability to avoid locality biases, and differentiability, enabling adaptation to different tasks. Furthermore, the survey addresses the challenges and considerations specific to medical imaging data, such as data availability, computational complexity, and dynamic clinical scene analysis. It also identifies future research directions and opportunities, including integration with multi-modal imaging, real-time and interactive systems, and domain adaptation for clinical decision support. To facilitate further exploration and implementation of INRs in medical image analysis, we have provided a compilation of cited studies along with their available open-source implementations on \href{https://github.com/mindflow-institue/Awesome-Implicit-Neural-Representations-in-Medical-imaging}. Finally, we aim to consistently incorporate the most recent and relevant papers regularly.
EnTri: Ensemble Learning with Tri-level Representations for Explainable Scene Recognition
Jul 23, 2023



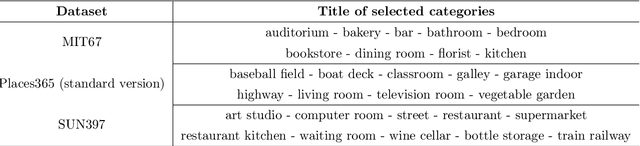
Scene recognition based on deep-learning has made significant progress, but there are still limitations in its performance due to challenges posed by inter-class similarities and intra-class dissimilarities. Furthermore, prior research has primarily focused on improving classification accuracy, yet it has given less attention to achieving interpretable, precise scene classification. Therefore, we are motivated to propose EnTri, an ensemble scene recognition framework that employs ensemble learning using a hierarchy of visual features. EnTri represents features at three distinct levels of detail: pixel-level, semantic segmentation-level, and object class and frequency level. By incorporating distinct feature encoding schemes of differing complexity and leveraging ensemble strategies, our approach aims to improve classification accuracy while enhancing transparency and interpretability via visual and textual explanations. To achieve interpretability, we devised an extension algorithm that generates both visual and textual explanations highlighting various properties of a given scene that contribute to the final prediction of its category. This includes information about objects, statistics, spatial layout, and textural details. Through experiments on benchmark scene classification datasets, EnTri has demonstrated superiority in terms of recognition accuracy, achieving competitive performance compared to state-of-the-art approaches, with an accuracy of 87.69%, 75.56%, and 99.17% on the MIT67, SUN397, and UIUC8 datasets, respectively.
TbExplain: A Text-based Explanation Method for Scene Classification Models with the Statistical Prediction Correction
Jul 19, 2023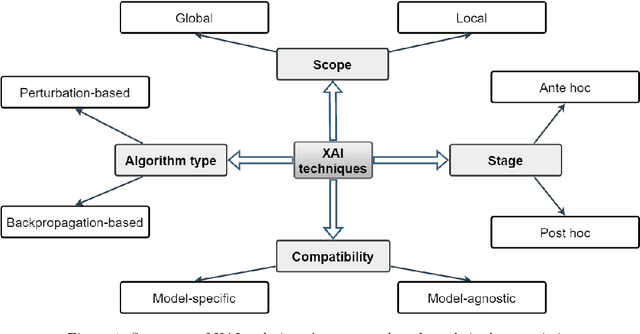

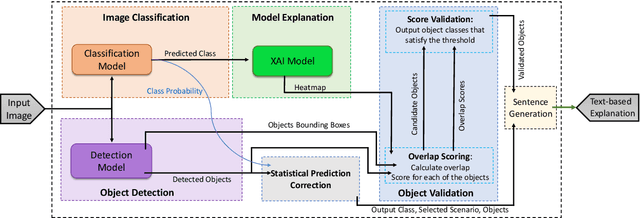
The field of Explainable Artificial Intelligence (XAI) aims to improve the interpretability of black-box machine learning models. Building a heatmap based on the importance value of input features is a popular method for explaining the underlying functions of such models in producing their predictions. Heatmaps are almost understandable to humans, yet they are not without flaws. Non-expert users, for example, may not fully understand the logic of heatmaps (the logic in which relevant pixels to the model's prediction are highlighted with different intensities or colors). Additionally, objects and regions of the input image that are relevant to the model prediction are frequently not entirely differentiated by heatmaps. In this paper, we propose a framework called TbExplain that employs XAI techniques and a pre-trained object detector to present text-based explanations of scene classification models. Moreover, TbExplain incorporates a novel method to correct predictions and textually explain them based on the statistics of objects in the input image when the initial prediction is unreliable. To assess the trustworthiness and validity of the text-based explanations, we conducted a qualitative experiment, and the findings indicated that these explanations are sufficiently reliable. Furthermore, our quantitative and qualitative experiments on TbExplain with scene classification datasets reveal an improvement in classification accuracy over ResNet variants.