 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Hashing with Hash Center Update for Efficient Image Retrieval
Paper and Code
Jun 11, 2021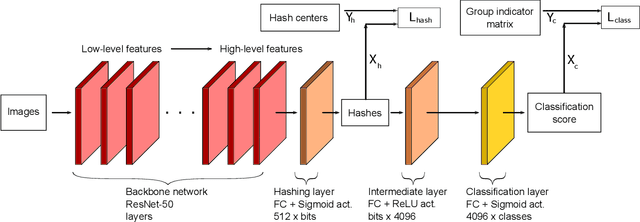
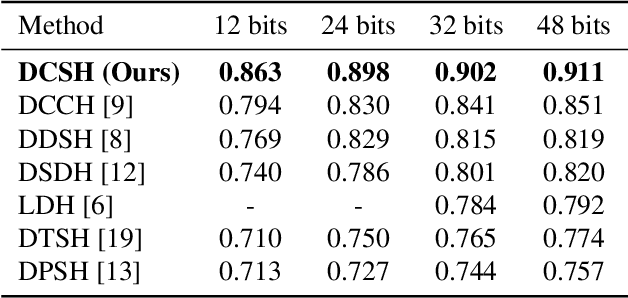
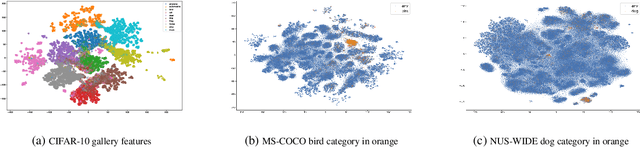
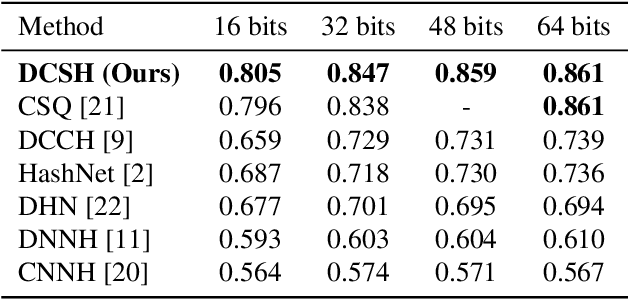
In this paper, we propose an approach for learning binary hash codes for image retrieval. Canonical Correlation Analysis (CCA) is used to design two loss functions for training a neural network such that the correlation between the two views to CCA is maximized. The first loss, maximizes the correlation between the hash centers and learned hash codes. The second loss maximizes the correlation between the class labels and classification scores. A novel weighted mean and thresholding based hash center update scheme is proposed for adapting the hash centers in each epoch. The training loss reaches the theoretical lower bound of the proposed loss functions, showing that the correlation coefficients are maximized during training and substantiating the formation of an efficient feature space for image retrieval. The measured mean average precision shows that the proposed approach outperforms other state-of-the-art approaches in both single-labeled and multi-labeled image datasets.