 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Effect of Counterfactuals on Reading Chest X-rays
Apr 02, 2023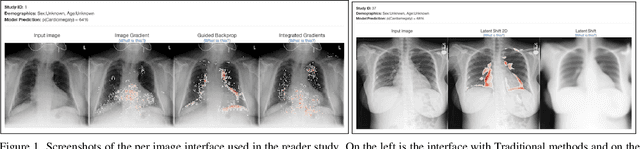
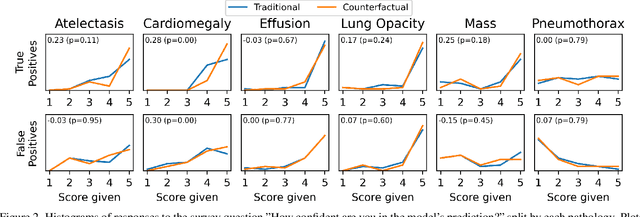
This study evaluates the effect of counterfactual explanations on the interpretation of chest X-rays. We conduct a reader study with two radiologists assessing 240 chest X-ray predictions to rate their confidence that the model's prediction is correct using a 5 point scale. Half of the predictions are false positives. Each prediction is explained twice, once using traditional attribution methods and once with a counterfactual explanation. The overall results indicate that counterfactual explanations allow a radiologist to have more confidence in true positive predictions compared to traditional approaches (0.15$\pm$0.95 with p=0.01) with only a small increase in false positive predictions (0.04$\pm$1.06 with p=0.57). We observe the specific prediction tasks of Mass and Atelectasis appear to benefit the most compared to other tasks.
TorchXRayVision: A library of chest X-ray datasets and models
Oct 31, 2021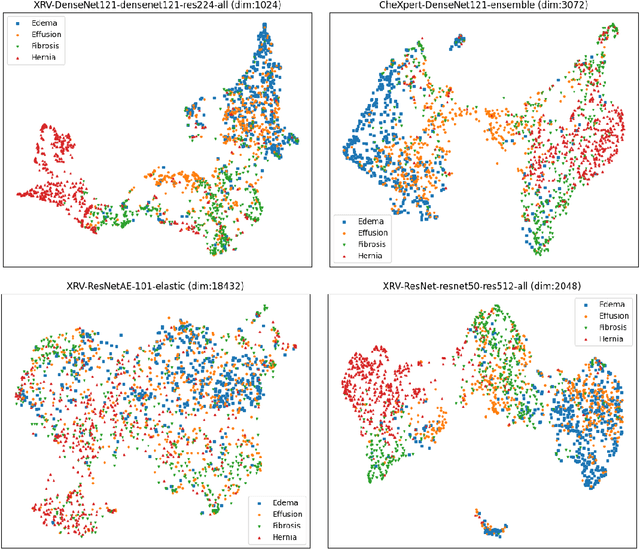
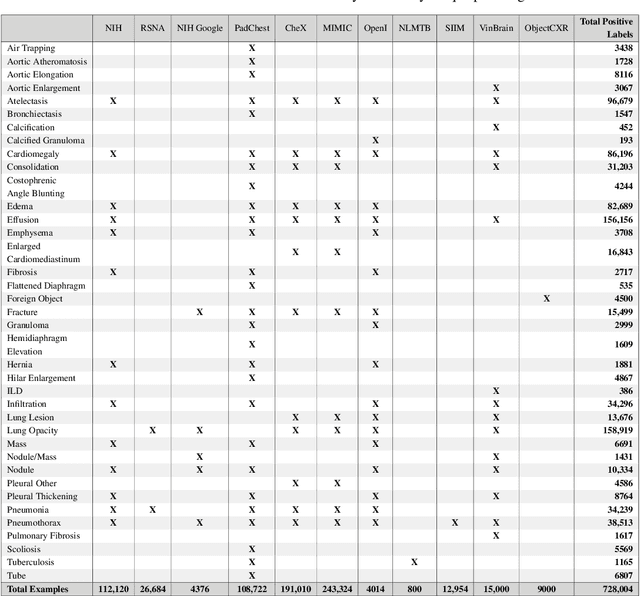
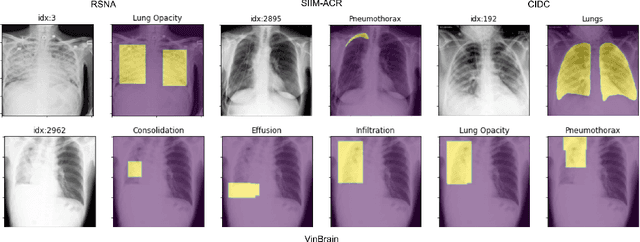
TorchXRayVision is an open source software library for working with chest X-ray datasets and deep learning models. It provides a common interface and common pre-processing chain for a wide set of publicly available chest X-ray datasets. In addition, a number of classification and representation learning models with different architectures, trained on different data combinations, are available through the library to serve as baselines or feature extractors.
Gifsplanation via Latent Shift: A Simple Autoencoder Approach to Progressive Exaggeration on Chest X-rays
Feb 18, 2021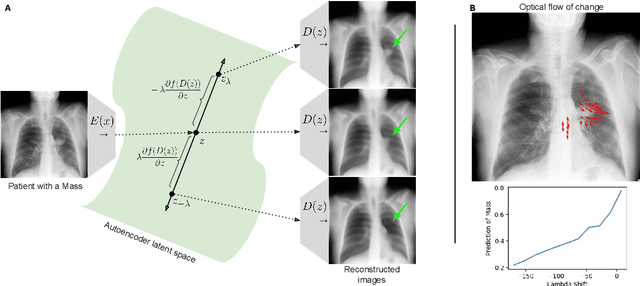

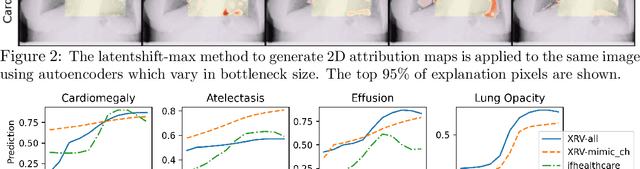

Motivation: Traditional image attribution methods struggle to satisfactorily explain predictions of neural networks. Prediction explanation is important, especially in the medical imaging, for avoiding the unintended consequences of deploying AI systems when false positive predictions can impact patient care. Thus, there is a pressing need to develop improved models for model explainability and introspection. Specific Problem: A new approach is to transform input images to increase or decrease features which cause the prediction. However, current approaches are difficult to implement as they are monolithic or rely on GANs. These hurdles prevent wide adoption. Our approach: Given an arbitrary classifier, we propose a simple autoencoder and gradient update (Latent Shift) that can transform the latent representation of an input image to exaggerate or curtail the features used for prediction. We use this method to study chest X-ray classifiers and evaluate their performance. We conduct a reader study with two radiologists assessing 240 chest X-ray predictions to identify which ones are false positives (half are) using traditional attribution maps or our proposed method. Results: We found low overlap with ground truth pathology masks for models with reasonably high accuracy. However, the results from our reader study indicate that these models are generally looking at the correct features. We also found that the Latent Shift explanation allows a user to have more confidence in true positive predictions compared to traditional approaches (0.15$\pm$0.95 in a 5 point scale with p=0.01) with only a small increase in false positive predictions (0.04$\pm$1.06 with p=0.57). Accompanying webpage: https://mlmed.org/gifsplanation Source code: https://github.com/mlmed/gifsplanation
Fine tuning U-Net for ultrasound image segmentation: which layers?
Feb 19, 2020
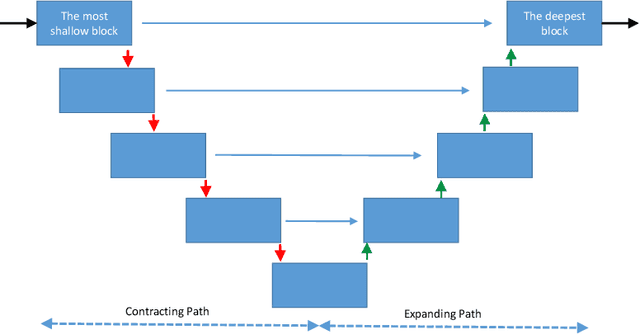

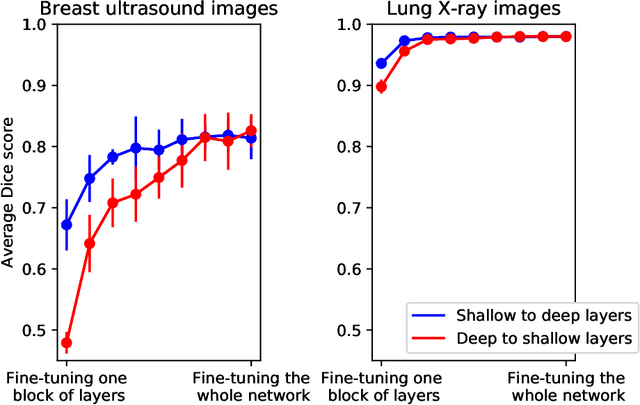
Fine-tuning a network which has been trained on a large dataset is an alternative to full training in order to overcome the problem of scarce and expensive data in medical applications. While the shallow layers of the network are usually kept unchanged, deeper layers are modified according to the new dataset. This approach may not work for ultrasound images due to their drastically different appearance. In this study, we investigated the effect of fine-tuning different layers of a U-Net which was trained on segmentation of natural images in breast ultrasound image segmentation. Tuning the contracting part and fixing the expanding part resulted in substantially better results compared to fixing the contracting part and tuning the expanding part. Furthermore, we showed that starting to fine-tune the U-Net from the shallow layers and gradually including more layers will lead to a better performance compared to fine-tuning the network from the deep layers moving back to shallow layers. We did not observe the same results on segmentation of X-ray images, which have different salient features compared to ultrasound, it may therefore be more appropriate to fine-tune the shallow layers rather than deep layers. Shallow layers learn lower level features (including speckle pattern, and probably the noise and artifact properties) which are critical in automatic segmentation in this modality.
On the limits of cross-domain generalization in automated X-ray prediction
Feb 06, 2020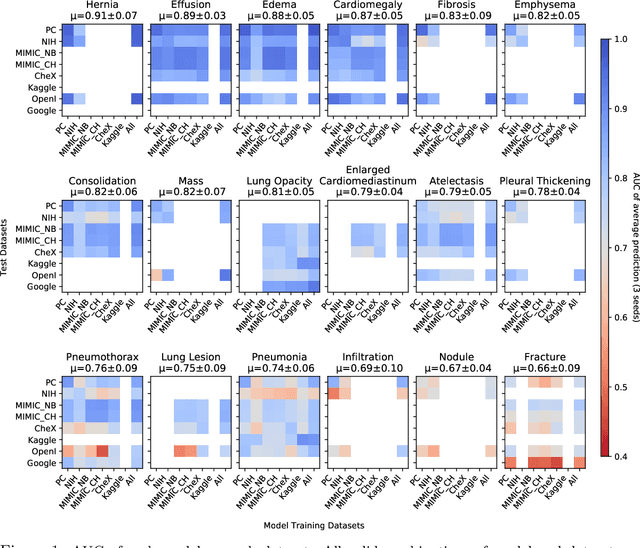

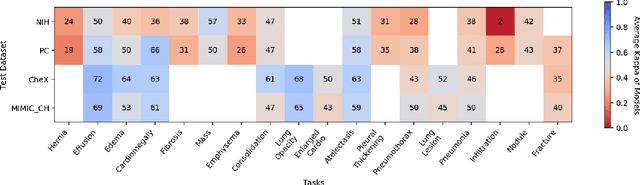
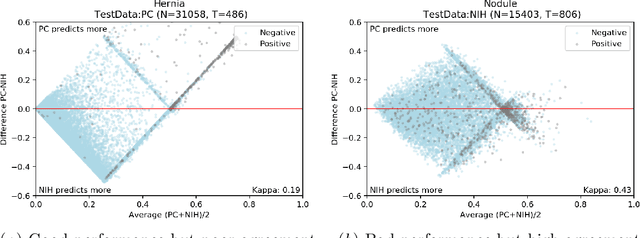
This large scale study focuses on quantifying what X-rays diagnostic prediction tasks generalize well across multiple different datasets. We present evidence that the issue of generalization is not due to a shift in the images but instead a shift in the labels. We study the cross-domain performance, agreement between models, and model representations. We find interesting discrepancies between performance and agreement where models which both achieve good performance disagree in their predictions as well as models which agree yet achieve poor performance. We also test for concept similarity by regularizing a network to group tasks across multiple datasets together and observe variation across the tasks.
Breast lesion segmentation in ultrasound images with limited annotated data
Jan 21, 2020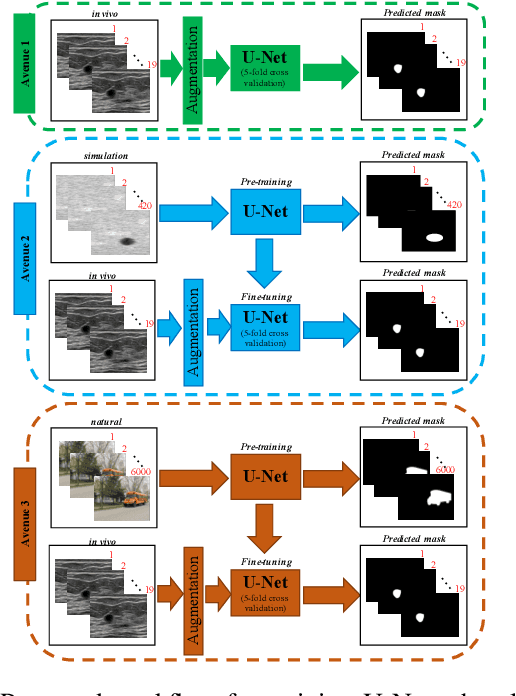

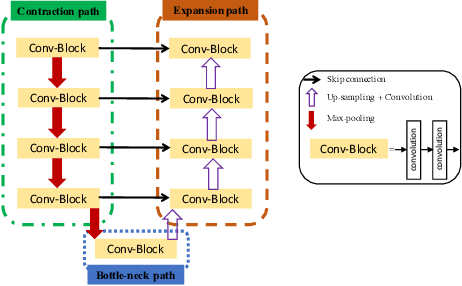

Ultrasound (US) is one of the most commonly used imaging modalities in both diagnosis and surgical interventions due to its low-cost, safety, and non-invasive characteristic. US image segmentation is currently a unique challenge because of the presence of speckle noise. As manual segmentation requires considerable efforts and time, the development of automatic segmentation algorithms has attracted researchers attention. Although recent methodologies based on convolutional neural networks have shown promising performances, their success relies on the availability of a large number of training data, which is prohibitively difficult for many applications. Therefore, in this study we propose the use of simulated US images and natural images as auxiliary datasets in order to pre-train our segmentation network, and then to fine-tune with limited in vivo data. We show that with as little as 19 in vivo images, fine-tuning the pre-trained network improves the dice score by 21% compared to training from scratch. We also demonstrate that if the same number of natural and simulation US images is available, pre-training on simulation data is preferable.
DeepAAA: clinically applicable and generalizable detection of abdominal aortic aneurysm using deep learning
Jul 04, 2019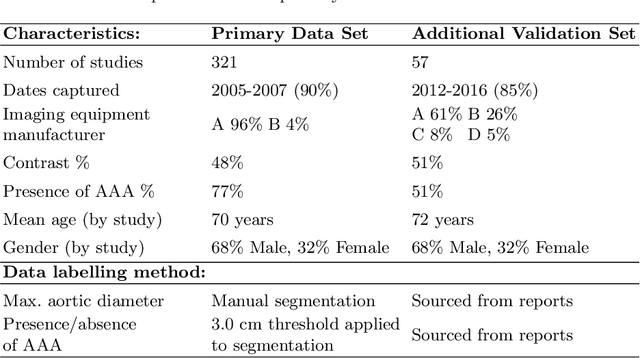
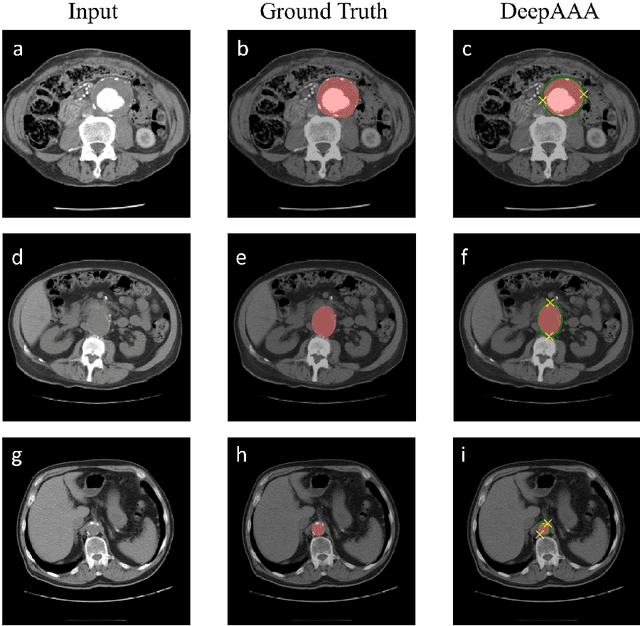
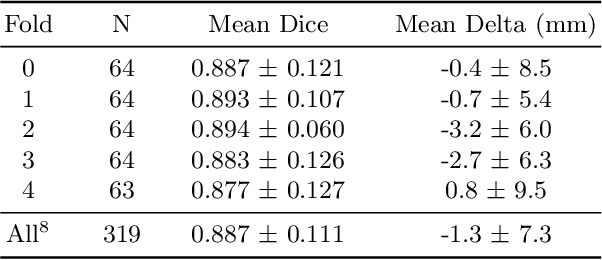
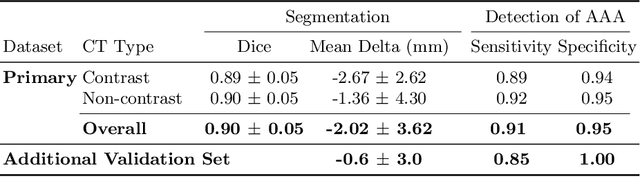
We propose a deep learning-based technique for detection and quantification of abdominal aortic aneurysms (AAAs). The condition, which leads to more than 10,000 deaths per year in the United States, is asymptomatic, often detected incidentally, and often missed by radiologists. Our model architecture is a modified 3D U-Net combined with ellipse fitting that performs aorta segmentation and AAA detection. The study uses 321 abdominal-pelvic CT examinations performed by Massachusetts General Hospital Department of Radiology for training and validation. The model is then further tested for generalizability on a separate set of 57 examinations with differing patient demographics and acquisition characteristics than the original dataset. DeepAAA achieves high performance on both sets of data (sensitivity/specificity 0.91/0.95 and 0.85 / 1.0 respectively), on contrast and non-contrast CT scans and works with image volumes with varying numbers of images. We find that DeepAAA exceeds literature-reported performance of radiologists on incidental AAA detection. It is expected that the model can serve as an effective background detector in routine CT examinations to prevent incidental AAAs from being missed.