Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the limits of cross-domain generalization in automated X-ray prediction
Paper and Code
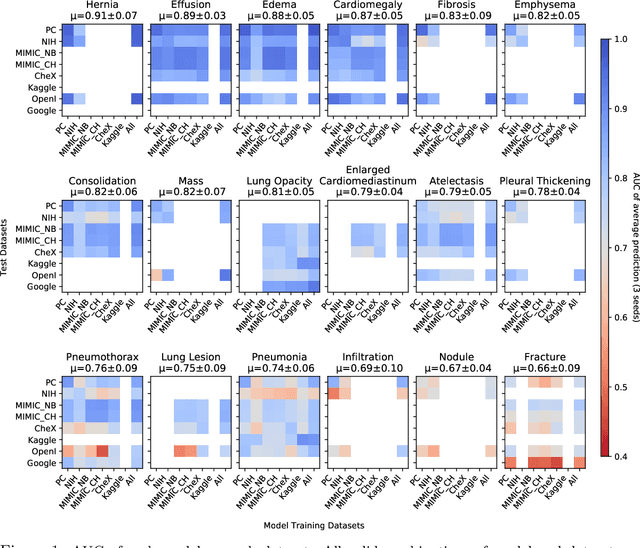

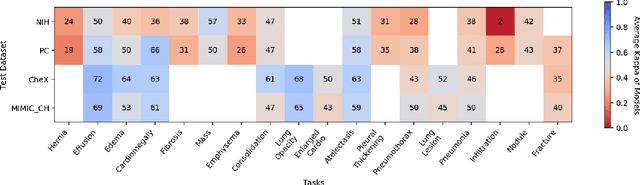
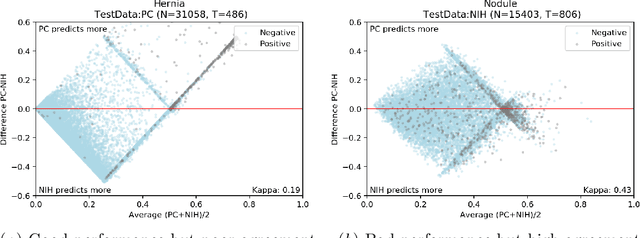
This large scale study focuses on quantifying what X-rays diagnostic prediction tasks generalize well across multiple different datasets. We present evidence that the issue of generalization is not due to a shift in the images but instead a shift in the labels. We study the cross-domain performance, agreement between models, and model representations. We find interesting discrepancies between performance and agreement where models which both achieve good performance disagree in their predictions as well as models which agree yet achieve poor performance. We also test for concept similarity by regularizing a network to group tasks across multiple datasets together and observe variation across the tasks.
* Submitted to MIDL2020
View paper on
 OpenReview
OpenReview