 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUltrasound Scatterer Density Classification Using Convolutional Neural Networks by Exploiting Patch Statistics
Dec 04, 2020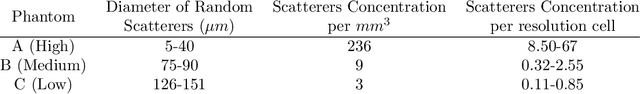
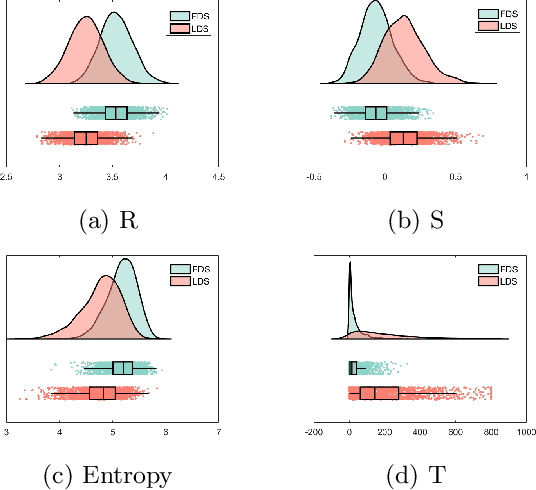
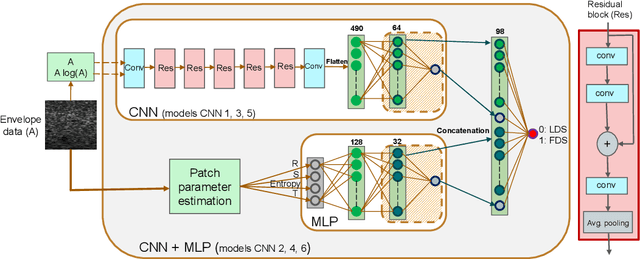
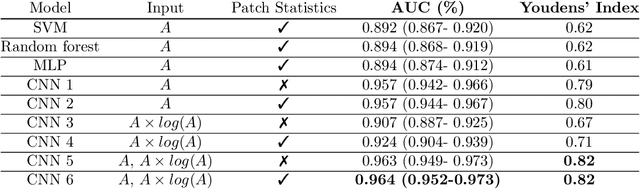
Quantitative ultrasound (QUS) can reveal crucial information on tissue properties such as scatterer density. If the scatterer density per resolution cell is above or below 10, the tissue is considered as fully developed speckle (FDS) or low-density scatterers (LDS), respectively. Conventionally, the scatterer density has been classified using estimated statistical parameters of the amplitude of backscattered echoes. However, if the patch size is small, the estimation is not accurate. These parameters are also highly dependent on imaging settings. In this paper, we propose a convolutional neural network (CNN) architecture for QUS, and train it using simulation data. We further improve the network performance by utilizing patch statistics as additional input channels. We evaluate the network using simulation data, experimental phantoms and in vivo data. We also compare our proposed network with different classic and deep learning models, and demonstrate its superior performance in classification of tissues with different scatterer density values. The results also show that the proposed network is able to work with different imaging parameters with no need for a reference phantom. This work demonstrates the potential of CNNs in classifying scatterer density in ultrasound images.
Fine tuning U-Net for ultrasound image segmentation: which layers?
Feb 19, 2020
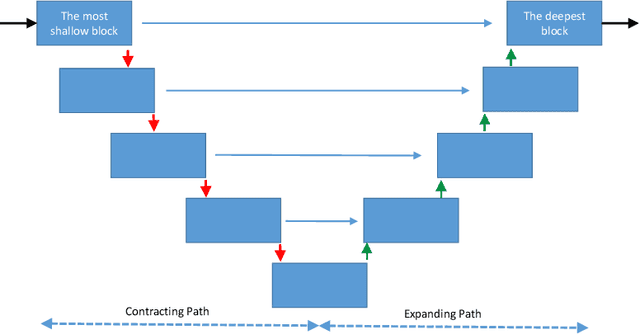

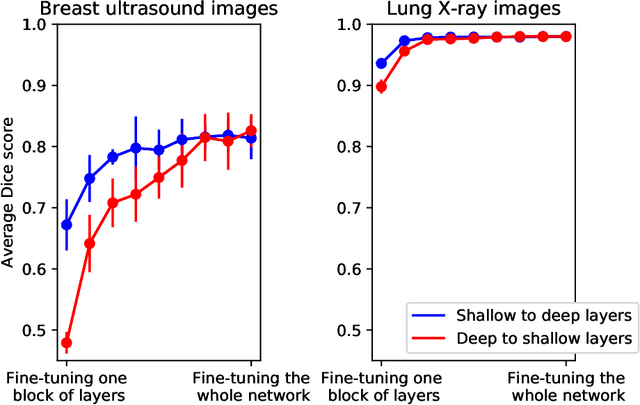
Fine-tuning a network which has been trained on a large dataset is an alternative to full training in order to overcome the problem of scarce and expensive data in medical applications. While the shallow layers of the network are usually kept unchanged, deeper layers are modified according to the new dataset. This approach may not work for ultrasound images due to their drastically different appearance. In this study, we investigated the effect of fine-tuning different layers of a U-Net which was trained on segmentation of natural images in breast ultrasound image segmentation. Tuning the contracting part and fixing the expanding part resulted in substantially better results compared to fixing the contracting part and tuning the expanding part. Furthermore, we showed that starting to fine-tune the U-Net from the shallow layers and gradually including more layers will lead to a better performance compared to fine-tuning the network from the deep layers moving back to shallow layers. We did not observe the same results on segmentation of X-ray images, which have different salient features compared to ultrasound, it may therefore be more appropriate to fine-tune the shallow layers rather than deep layers. Shallow layers learn lower level features (including speckle pattern, and probably the noise and artifact properties) which are critical in automatic segmentation in this modality.
Breast lesion segmentation in ultrasound images with limited annotated data
Jan 21, 2020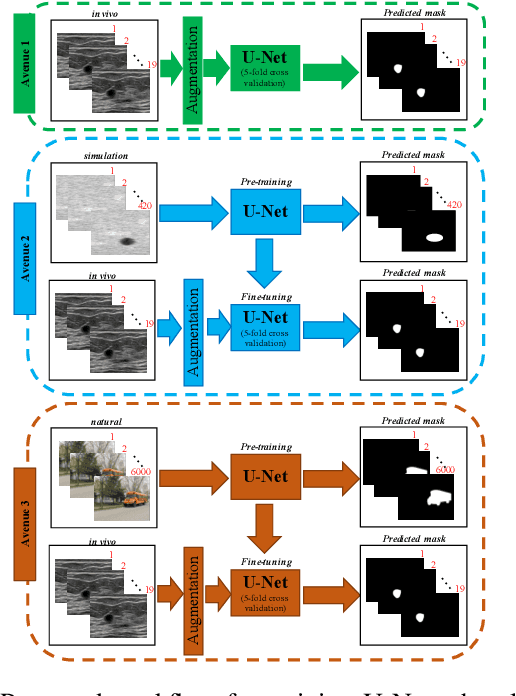

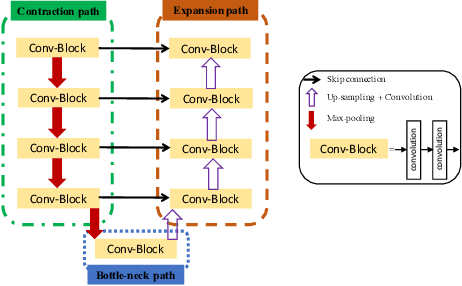

Ultrasound (US) is one of the most commonly used imaging modalities in both diagnosis and surgical interventions due to its low-cost, safety, and non-invasive characteristic. US image segmentation is currently a unique challenge because of the presence of speckle noise. As manual segmentation requires considerable efforts and time, the development of automatic segmentation algorithms has attracted researchers attention. Although recent methodologies based on convolutional neural networks have shown promising performances, their success relies on the availability of a large number of training data, which is prohibitively difficult for many applications. Therefore, in this study we propose the use of simulated US images and natural images as auxiliary datasets in order to pre-train our segmentation network, and then to fine-tune with limited in vivo data. We show that with as little as 19 in vivo images, fine-tuning the pre-trained network improves the dice score by 21% compared to training from scratch. We also demonstrate that if the same number of natural and simulation US images is available, pre-training on simulation data is preferable.