 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrame by Familiar Frame: Understanding Replication in Video Diffusion Models
Mar 28, 2024Building on the momentum of image generation diffusion models, there is an increasing interest in video-based diffusion models. However, video generation poses greater challenges due to its higher-dimensional nature, the scarcity of training data, and the complex spatiotemporal relationships involved. Image generation models, due to their extensive data requirements, have already strained computational resources to their limits. There have been instances of these models reproducing elements from the training samples, leading to concerns and even legal disputes over sample replication. Video diffusion models, which operate with even more constrained datasets and are tasked with generating both spatial and temporal content, may be more prone to replicating samples from their training sets. Compounding the issue, these models are often evaluated using metrics that inadvertently reward replication. In our paper, we present a systematic investigation into the phenomenon of sample replication in video diffusion models. We scrutinize various recent diffusion models for video synthesis, assessing their tendency to replicate spatial and temporal content in both unconditional and conditional generation scenarios. Our study identifies strategies that are less likely to lead to replication. Furthermore, we propose new evaluation strategies that take replication into account, offering a more accurate measure of a model's ability to generate the original content.
Analyzing Bias in Diffusion-based Face Generation Models
May 10, 2023



Diffusion models are becoming increasingly popular in synthetic data generation and image editing applications. However, these models can amplify existing biases and propagate them to downstream applications. Therefore, it is crucial to understand the sources of bias in their outputs. In this paper, we investigate the presence of bias in diffusion-based face generation models with respect to attributes such as gender, race, and age. Moreover, we examine how dataset size affects the attribute composition and perceptual quality of both diffusion and Generative Adversarial Network (GAN) based face generation models across various attribute classes. Our findings suggest that diffusion models tend to worsen distribution bias in the training data for various attributes, which is heavily influenced by the size of the dataset. Conversely, GAN models trained on balanced datasets with a larger number of samples show less bias across different attributes.
SAR Despeckling using a Denoising Diffusion Probabilistic Model
Jun 09, 2022


Speckle is a multiplicative noise which affects all coherent imaging modalities including Synthetic Aperture Radar (SAR) images. The presence of speckle degrades the image quality and adversely affects the performance of SAR image understanding applications such as automatic target recognition and change detection. Thus, SAR despeckling is an important problem in remote sensing. In this paper, we introduce SAR-DDPM, a denoising diffusion probabilistic model for SAR despeckling. The proposed method comprises of a Markov chain that transforms clean images to white Gaussian noise by repeatedly adding random noise. The despeckled image is recovered by a reverse process which iteratively predicts the added noise using a noise predictor which is conditioned on the speckled image. In addition, we propose a new inference strategy based on cycle spinning to improve the despeckling performance. Our experiments on both synthetic and real SAR images demonstrate that the proposed method achieves significant improvements in both quantitative and qualitative results over the state-of-the-art despeckling methods.
SAR Despeckling Using Overcomplete Convolutional Networks
May 31, 2022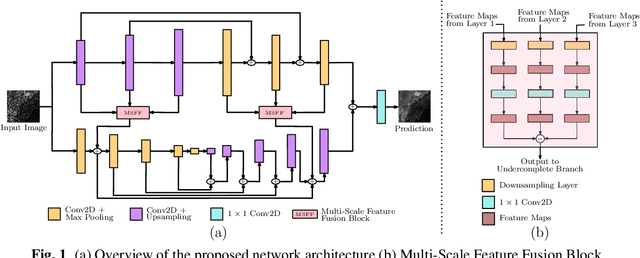
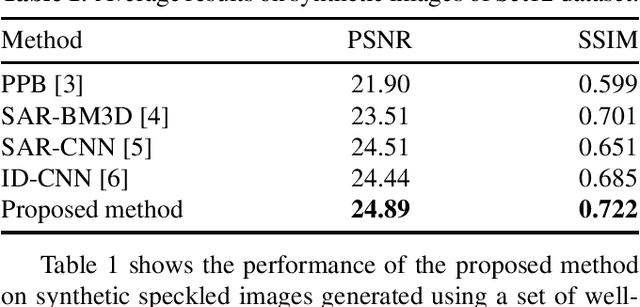


Synthetic Aperture Radar (SAR) despeckling is an important problem in remote sensing as speckle degrades SAR images, affecting downstream tasks like detection and segmentation. Recent studies show that convolutional neural networks(CNNs) outperform classical despeckling methods. Traditional CNNs try to increase the receptive field size as the network goes deeper, thus extracting global features. However,speckle is relatively small, and increasing receptive field does not help in extracting speckle features. This study employs an overcomplete CNN architecture to focus on learning low-level features by restricting the receptive field. The proposed network consists of an overcomplete branch to focus on the local structures and an undercomplete branch that focuses on the global structures. We show that the proposed network improves despeckling performance compared to recent despeckling methods on synthetic and real SAR images.
Transformer-based SAR Image Despeckling
Jan 23, 2022

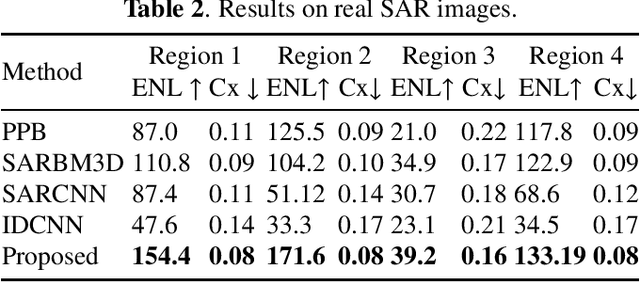
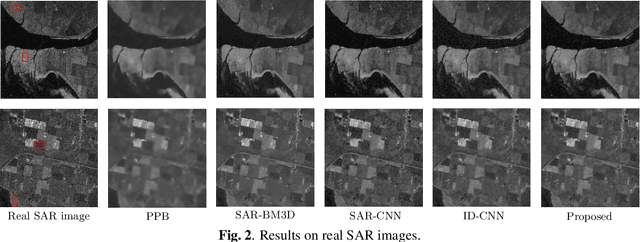
Synthetic Aperture Radar (SAR) images are usually degraded by a multiplicative noise known as speckle which makes processing and interpretation of SAR images difficult. In this paper, we introduce a transformer-based network for SAR image despeckling. The proposed despeckling network comprises of a transformer-based encoder which allows the network to learn global dependencies between different image regions - aiding in better despeckling. The network is trained end-to-end with synthetically generated speckled images using a composite loss function. Experiments show that the proposed method achieves significant improvements over traditional and convolutional neural network-based despeckling methods on both synthetic and real SAR images.
A Thickness Sensitive Vessel Extraction Framework for Retinal and Conjunctival Vascular Tortuosity Analysis
Jan 02, 2021
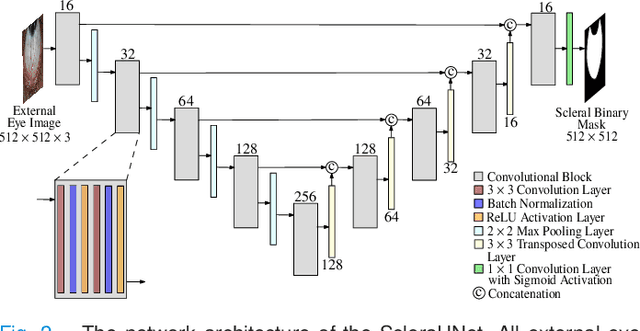
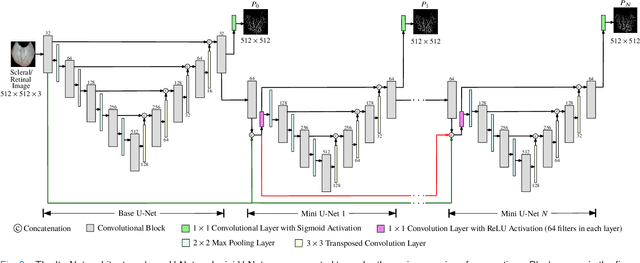

Systemic diseases such as diabetes, hypertension, atherosclerosis are among the leading causes of annual human mortality rate. It is suggested that retinal and conjunctival vascular tortuosity is a potential biomarker for such systemic diseases. Most importantly, it is observed that the tortuosity depends on the thickness of these vessels. Therefore, selective calculation of tortuosity within specific vessel thicknesses is required depending on the disease being analysed. In this paper, we propose a thickness sensitive vessel extraction framework that is primarily applicable for studies related to retinal and conjunctival vascular tortuosity. The framework uses a Convolutional Neural Network based on the IterNet architecture to obtain probability maps of the entire vasculature. They are then processed by a multi-scale vessel enhancement technique that exploits both fine and coarse structural vascular details of these probability maps in order to extract vessels of specified thicknesses. We evaluated the proposed framework on four datasets including DRIVE and SBVPI, and obtained Matthew's Correlation Coefficient values greater than 0.71 for all the datasets. In addition, the proposed framework was utilized to determine the association of diabetes with retinal and conjunctival vascular tortuosity. We observed that retinal vascular tortuosity (Eccentricity based Tortuosity Index) of the diabetic group was significantly higher (p < .05) than that of the non-diabetic group and that conjunctival vascular tortuosity (Total Curvature normalized by Arc Length) of diabetic group was significantly lower (p < .05) than that of the non-diabetic group. These observations were in agreement with the literature, strengthening the suitability of the proposed framework.
A Joint Convolutional and Spatial Quad-Directional LSTM Network for Phase Unwrapping
Oct 26, 2020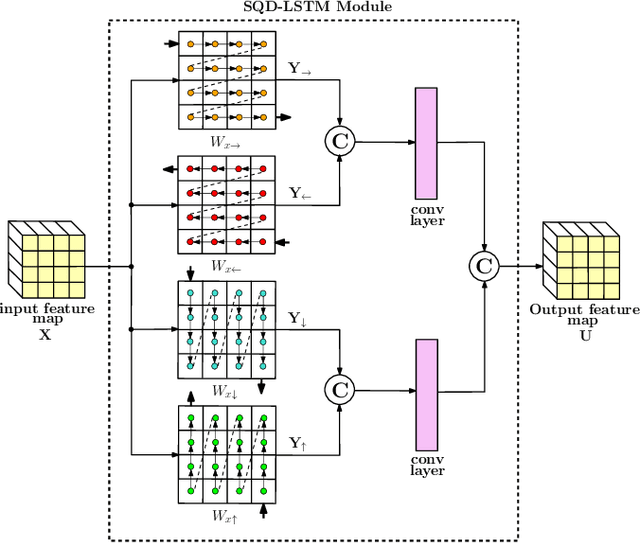
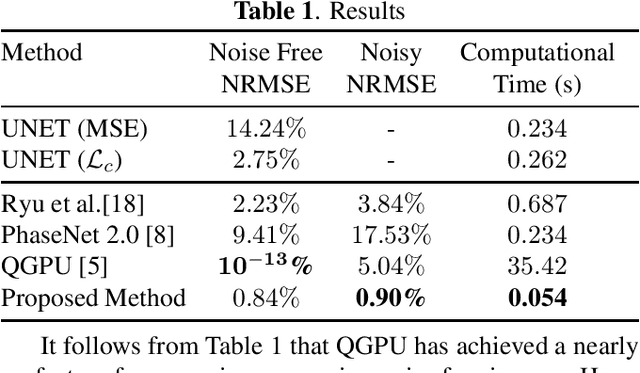

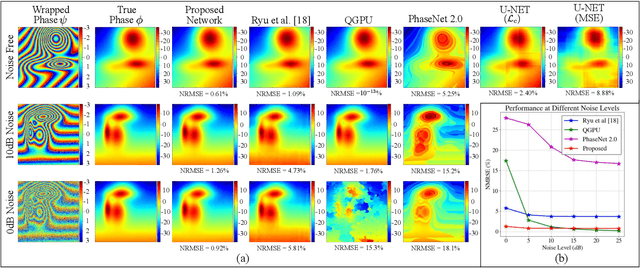
Phase unwrapping is a classical ill-posed problem which aims to recover the true phase from wrapped phase. In this paper, we introduce a novel Convolutional Neural Network (CNN) that incorporates a Spatial Quad-Directional Long Short Term Memory (SQD-LSTM) for phase unwrapping, by formulating it as a regression problem. Incorporating SQD-LSTM can circumvent the typical CNNs' inherent difficulty of learning global spatial dependencies which are vital when recovering the true phase. Furthermore, we employ a problem specific composite loss function to train this network. The proposed network is found to be performing better than the existing methods under severe noise conditions (Normalized Root Mean Square Error of 1.3 % at SNR = 0 dB) while spending a significantly less computational time (0.054 s). The network also does not require a large scale dataset during training, thus making it ideal for applications with limited data that require fast and accurate phase unwrapping.