 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA hybrid Kolmogorov-Arnold network for medical image segmentation
Feb 07, 2026Medical image segmentation plays a vital role in diagnosis and treatment planning, but remains challenging due to the inherent complexity and variability of medical images, especially in capturing non-linear relationships within the data. We propose U-KABS, a novel hybrid framework that integrates the expressive power of Kolmogorov-Arnold Networks (KANs) with a U-shaped encoder-decoder architecture to enhance segmentation performance. The U-KABS model combines the convolutional and squeeze-and-excitation stage, which enhances channel-wise feature representations, and the KAN Bernstein Spline (KABS) stage, which employs learnable activation functions based on Bernstein polynomials and B-splines. This hybrid design leverages the global smoothness of Bernstein polynomials and the local adaptability of B-splines, enabling the model to effectively capture both broad contextual trends and fine-grained patterns critical for delineating complex structures in medical images. Skip connections between encoder and decoder layers support effective multi-scale feature fusion and preserve spatial details. Evaluated across diverse medical imaging benchmark datasets, U-KABS demonstrates superior performance compared to strong baselines, particularly in segmenting complex anatomical structures.
Time series forecasting with Hahn Kolmogorov-Arnold networks
Jan 25, 2026Recent Transformer- and MLP-based models have demonstrated strong performance in long-term time series forecasting, yet Transformers remain limited by their quadratic complexity and permutation-equivariant attention, while MLPs exhibit spectral bias. We propose HaKAN, a versatile model based on Kolmogorov-Arnold Networks (KANs), leveraging Hahn polynomial-based learnable activation functions and providing a lightweight and interpretable alternative for multivariate time series forecasting. Our model integrates channel independence, patching, a stack of Hahn-KAN blocks with residual connections, and a bottleneck structure comprised of two fully connected layers. The Hahn-KAN block consists of inter- and intra-patch KAN layers to effectively capture both global and local temporal patterns. Extensive experiments on various forecasting benchmarks demonstrate that our model consistently outperforms recent state-of-the-art methods, with ablation studies validating the effectiveness of its core components.
Adaptive graph Kolmogorov-Arnold network for 3D human pose estimation
Nov 11, 2025Graph convolutional network (GCN)-based methods have shown strong performance in 3D human pose estimation by leveraging the natural graph structure of the human skeleton. However, their local receptive field limits their ability to capture long-range dependencies essential for handling occlusions and depth ambiguities. They also exhibit spectral bias, which prioritizes low-frequency components while struggling to model high-frequency details. In this paper, we introduce PoseKAN, an adaptive graph Kolmogorov-Arnold Network (KAN), framework that extends KANs to graph-based learning for 2D-to-3D pose lifting from a single image. Unlike GCNs that use fixed activation functions, KANs employ learnable functions on graph edges, allowing data-driven, adaptive feature transformations. This enhances the model's adaptability and expressiveness, making it more expressive in learning complex pose variations. Our model employs multi-hop feature aggregation, ensuring the body joints can leverage information from both local and distant neighbors, leading to improved spatial awareness. It also incorporates residual PoseKAN blocks for deeper feature refinement, and a global response normalization for improved feature selectivity and contrast. Extensive experiments on benchmark datasets demonstrate the competitive performance of our model against state-of-the-art methods.
LuKAN: A Kolmogorov-Arnold Network Framework for 3D Human Motion Prediction
Aug 06, 2025



The goal of 3D human motion prediction is to forecast future 3D poses of the human body based on historical motion data. Existing methods often face limitations in achieving a balance between prediction accuracy and computational efficiency. In this paper, we present LuKAN, an effective model based on Kolmogorov-Arnold Networks (KANs) with Lucas polynomial activations. Our model first applies the discrete wavelet transform to encode temporal information in the input motion sequence. Then, a spatial projection layer is used to capture inter-joint dependencies, ensuring structural consistency of the human body. At the core of LuKAN is the Temporal Dependency Learner, which employs a KAN layer parameterized by Lucas polynomials for efficient function approximation. These polynomials provide computational efficiency and an enhanced capability to handle oscillatory behaviors. Finally, the inverse discrete wavelet transform reconstructs motion sequences in the time domain, generating temporally coherent predictions. Extensive experiments on three benchmark datasets demonstrate the competitive performance of our model compared to strong baselines, as evidenced by both quantitative and qualitative evaluations. Moreover, its compact architecture coupled with the linear recurrence of Lucas polynomials, ensures computational efficiency.
A federated large language model for long-term time series forecasting
Jul 30, 2024Long-term time series forecasting in centralized environments poses unique challenges regarding data privacy, communication overhead, and scalability. To address these challenges, we propose FedTime, a federated large language model (LLM) tailored for long-range time series prediction. Specifically, we introduce a federated pre-trained LLM with fine-tuning and alignment strategies. Prior to the learning process, we employ K-means clustering to partition edge devices or clients into distinct clusters, thereby facilitating more focused model training. We also incorporate channel independence and patching to better preserve local semantic information, ensuring that important contextual details are retained while minimizing the risk of information loss. We demonstrate the effectiveness of our FedTime model through extensive experiments on various real-world forecasting benchmarks, showcasing substantial improvements over recent approaches. In addition, we demonstrate the efficiency of FedTime in streamlining resource usage, resulting in reduced communication overhead.
Flexible graph convolutional network for 3D human pose estimation
Jul 26, 2024



Although graph convolutional networks exhibit promising performance in 3D human pose estimation, their reliance on one-hop neighbors limits their ability to capture high-order dependencies among body joints, crucial for mitigating uncertainty arising from occlusion or depth ambiguity. To tackle this limitation, we introduce Flex-GCN, a flexible graph convolutional network designed to learn graph representations that capture broader global information and dependencies. At its core is the flexible graph convolution, which aggregates features from both immediate and second-order neighbors of each node, while maintaining the same time and memory complexity as the standard convolution. Our network architecture comprises residual blocks of flexible graph convolutional layers, as well as a global response normalization layer for global feature aggregation, normalization and calibration. Quantitative and qualitative results demonstrate the effectiveness of our model, achieving competitive performance on benchmark datasets.
PEEKABOO: Hiding parts of an image for unsupervised object localization
Jul 24, 2024
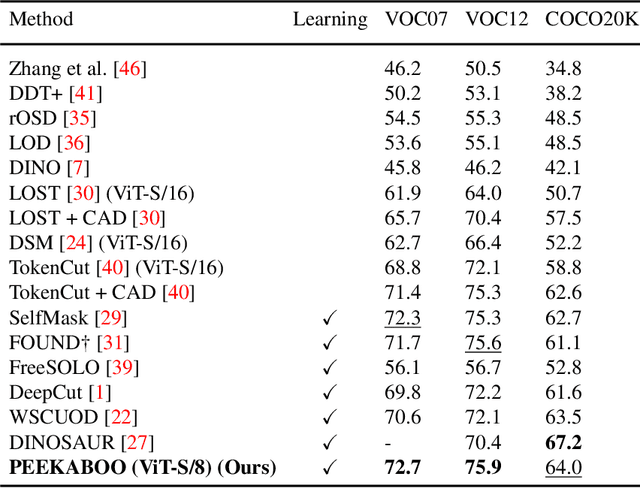
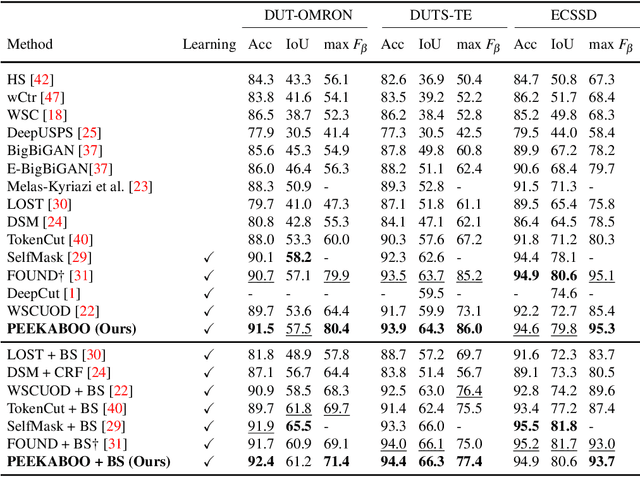

Localizing objects in an unsupervised manner poses significant challenges due to the absence of key visual information such as the appearance, type and number of objects, as well as the lack of labeled object classes typically available in supervised settings. While recent approaches to unsupervised object localization have demonstrated significant progress by leveraging self-supervised visual representations, they often require computationally intensive training processes, resulting in high resource demands in terms of computation, learnable parameters, and data. They also lack explicit modeling of visual context, potentially limiting their accuracy in object localization. To tackle these challenges, we propose a single-stage learning framework, dubbed PEEKABOO, for unsupervised object localization by learning context-based representations at both the pixel- and shape-level of the localized objects through image masking. The key idea is to selectively hide parts of an image and leverage the remaining image information to infer the location of objects without explicit supervision. The experimental results, both quantitative and qualitative, across various benchmark datasets, demonstrate the simplicity, effectiveness and competitive performance of our approach compared to state-of-the-art methods in both single object discovery and unsupervised salient object detection tasks. Code and pre-trained models are available at: https://github.com/hasibzunair/peekaboo
Multi-hop graph transformer network for 3D human pose estimation
May 05, 2024Accurate 3D human pose estimation is a challenging task due to occlusion and depth ambiguity. In this paper, we introduce a multi-hop graph transformer network designed for 2D-to-3D human pose estimation in videos by leveraging the strengths of multi-head self-attention and multi-hop graph convolutional networks with disentangled neighborhoods to capture spatio-temporal dependencies and handle long-range interactions. The proposed network architecture consists of a graph attention block composed of stacked layers of multi-head self-attention and graph convolution with learnable adjacency matrix, and a multi-hop graph convolutional block comprised of multi-hop convolutional and dilated convolutional layers. The combination of multi-head self-attention and multi-hop graph convolutional layers enables the model to capture both local and global dependencies, while the integration of dilated convolutional layers enhances the model's ability to handle spatial details required for accurate localization of the human body joints. Extensive experiments demonstrate the effectiveness and generalization ability of our model, achieving competitive performance on benchmark datasets.
RSUD20K: A Dataset for Road Scene Understanding In Autonomous Driving
Jan 14, 2024



Road scene understanding is crucial in autonomous driving, enabling machines to perceive the visual environment. However, recent object detectors tailored for learning on datasets collected from certain geographical locations struggle to generalize across different locations. In this paper, we present RSUD20K, a new dataset for road scene understanding, comprised of over 20K high-resolution images from the driving perspective on Bangladesh roads, and includes 130K bounding box annotations for 13 objects. This challenging dataset encompasses diverse road scenes, narrow streets and highways, featuring objects from different viewpoints and scenes from crowded environments with densely cluttered objects and various weather conditions. Our work significantly improves upon previous efforts, providing detailed annotations and increased object complexity. We thoroughly examine the dataset, benchmarking various state-of-the-art object detectors and exploring large vision models as image annotators.
Adaptive spectral graph wavelets for collaborative filtering
Dec 05, 2023Collaborative filtering is a popular approach in recommender systems, whose objective is to provide personalized item suggestions to potential users based on their purchase or browsing history. However, personalized recommendations require considerable amount of behavioral data on users, which is usually unavailable for new users, giving rise to the cold-start problem. To help alleviate this challenging problem, we introduce a spectral graph wavelet collaborative filtering framework for implicit feedback data, where users, items and their interactions are represented as a bipartite graph. Specifically, we first propose an adaptive transfer function by leveraging a power transform with the goal of stabilizing the variance of graph frequencies in the spectral domain. Then, we design a deep recommendation model for efficient learning of low-dimensional embeddings of users and items using spectral graph wavelets in an end-to-end fashion. In addition to capturing the graph's local and global structures, our approach yields localization of graph signals in both spatial and spectral domains, and hence not only learns discriminative representations of users and items, but also promotes the recommendation quality. The effectiveness of our proposed model is demonstrated through extensive experiments on real-world benchmark datasets, achieving better recommendation performance compared with strong baseline methods.