 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT Incorrectness Detection in Software Reviews
Mar 25, 2024We conducted a survey of 135 software engineering (SE) practitioners to understand how they use Generative AI-based chatbots like ChatGPT for SE tasks. We find that they want to use ChatGPT for SE tasks like software library selection but often worry about the truthfulness of ChatGPT responses. We developed a suite of techniques and a tool called CID (ChatGPT Incorrectness Detector) to automatically test and detect the incorrectness in ChatGPT responses. CID is based on the iterative prompting to ChatGPT by asking it contextually similar but textually divergent questions (using an approach that utilizes metamorphic relationships in texts). The underlying principle in CID is that for a given question, a response that is different from other responses (across multiple incarnations of the question) is likely an incorrect response. In a benchmark study of library selection, we show that CID can detect incorrect responses from ChatGPT with an F1-score of 0.74 - 0.75.
A Comparative Analysis of Machine Learning Approaches for Automated Face Mask Detection During COVID-19
Dec 15, 2021

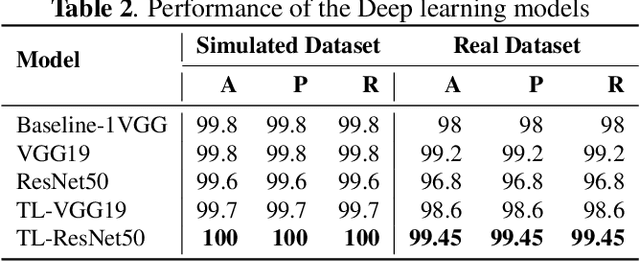
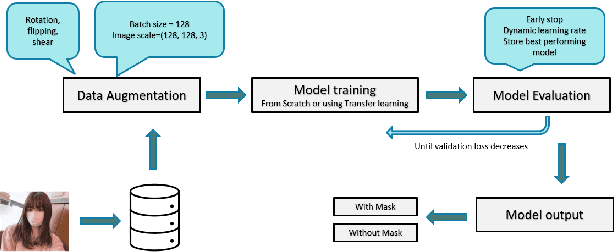
The World Health Organization (WHO) has recommended wearing face masks as one of the most effective measures to prevent COVID-19 transmission. In many countries, it is now mandatory to wear face masks, specially in public places. Since manual monitoring of face masks is often infeasible in the middle of the crowd, automatic detection can be beneficial. To facilitate that, we explored a number of deep learning models (i.e., VGG1, VGG19, ResNet50) for face-mask detection and evaluated them on two benchmark datasets. We also evaluated transfer learning (i.e., VGG19, ResNet50 pre-trained on ImageNet) in this context. We find that while the performances of all the models are quite good, transfer learning models achieve the best performance. Transfer learning improves the performance by 0.10\%--0.40\% with 30\% less training time. Our experiment also shows these high-performing models are not quite robust for real-world cases where the test dataset comes from a different distribution. Without any fine-tuning, the performance of these models drops by 47\% in cross-domain settings.
COVID-19Base: A knowledgebase to explore biomedical entities related to COVID-19
May 12, 2020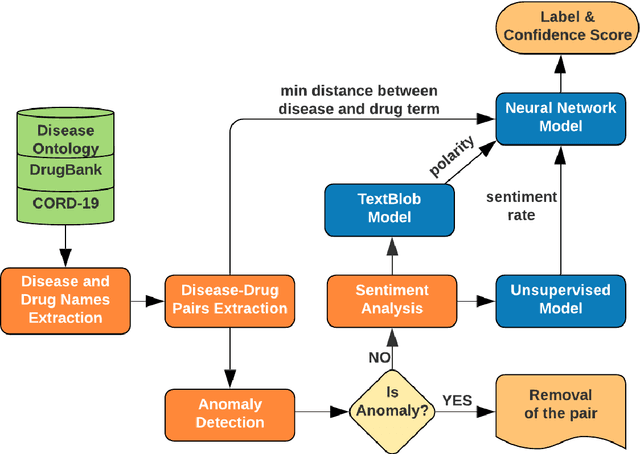
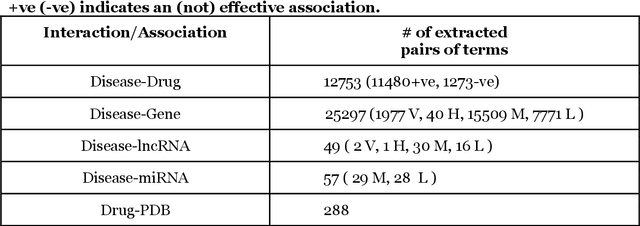
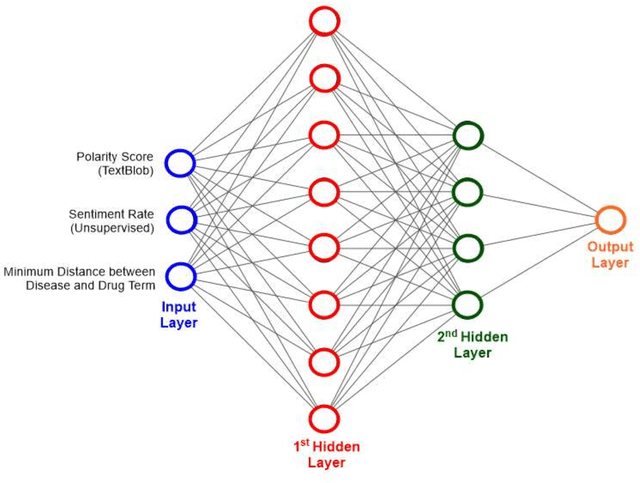
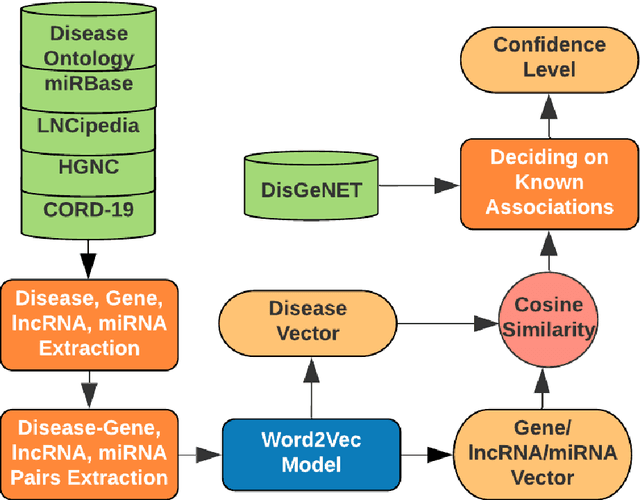
We are presenting COVID-19Base, a knowledgebase highlighting the biomedical entities related to COVID-19 disease based on literature mining. To develop COVID-19Base, we mine the information from publicly available scientific literature and related public resources. We considered seven topic-specific dictionaries, including human genes, human miRNAs, human lncRNAs, diseases, Protein Databank, drugs, and drug side effects, are integrated to mine all scientific evidence related to COVID-19. We have employed an automated literature mining and labeling system through a novel approach to measure the effectiveness of drugs against diseases based on natural language processing, sentiment analysis, and deep learning. To the best of our knowledge, this is the first knowledgebase dedicated to COVID-19, which integrates such large variety of related biomedical entities through literature mining. Proper investigation of the mined biomedical entities along with the identified interactions among those, reported in COVID-19Base, would help the research community to discover possible ways for the therapeutic treatment of COVID-19.
A Benchmark Study on Machine Learning Methods for Fake News Detection
May 12, 2019
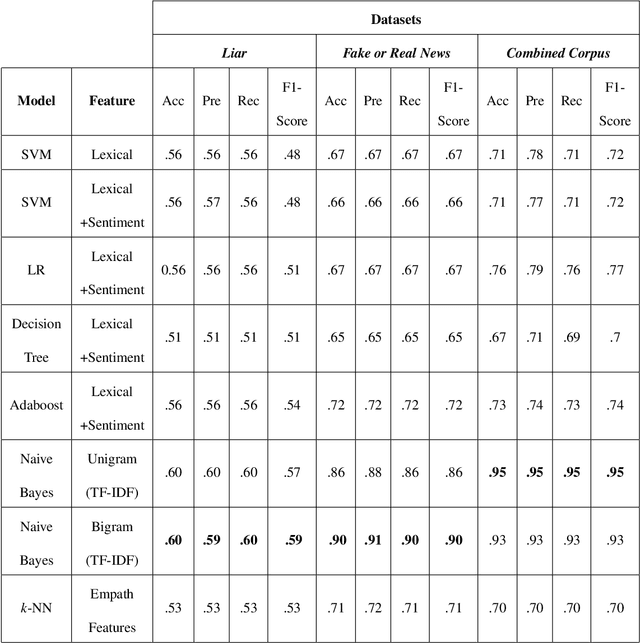
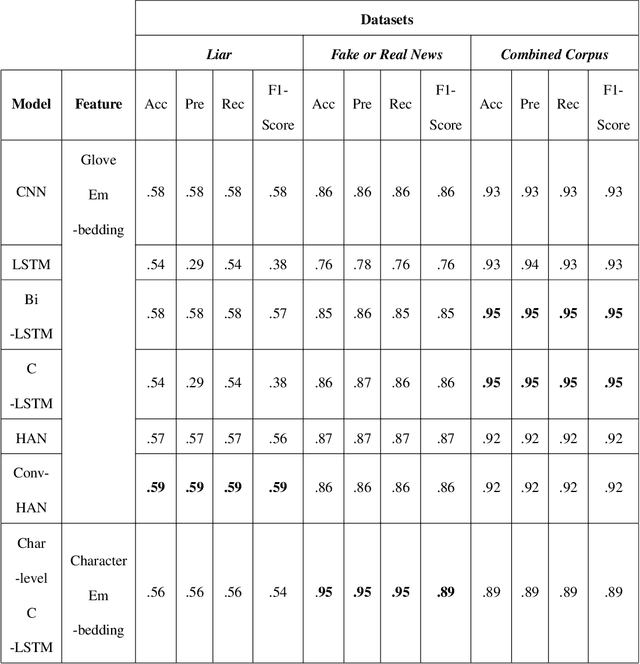
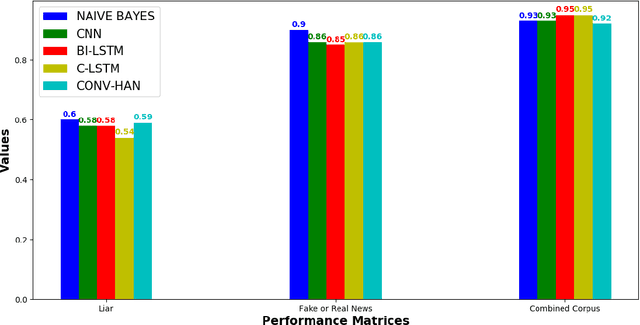
The proliferation of fake news and its propagation on social media have become a major concern due to its ability to create devastating impacts. Different machine learning approaches have been attempted to detect it. However, most of those focused on a special type of news (such as political) and did not apply many advanced techniques. In this research, we conduct a benchmark study to assess the performance of different applicable approaches on three different datasets where the largest and most diversified one was developed by us. We also implemented some advanced deep learning models that have shown promising results.