 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLowResource at BLP-2023 Task 2: Leveraging BanglaBert for Low Resource Sentiment Analysis of Bangla Language
Paper and Code

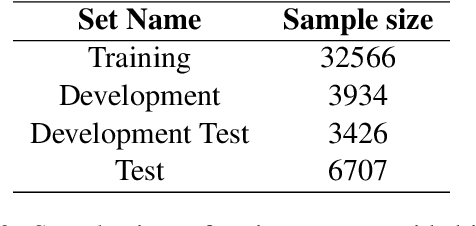

This paper describes the system of the LowResource Team for Task 2 of BLP-2023, which involves conducting sentiment analysis on a dataset composed of public posts and comments from diverse social media platforms. Our primary aim is to utilize BanglaBert, a BERT model pre-trained on a large Bangla corpus, using various strategies including fine-tuning, dropping random tokens, and using several external datasets. Our final model is an ensemble of the three best BanglaBert variations. Our system has achieved overall 3rd in the Test Set among 30 participating teams with a score of 0.718. Additionally, we discuss the promising systems that didn't perform well namely task-adaptive pertaining and paraphrasing using BanglaT5. Training codes and external datasets which are used for our system are publicly available at https://github.com/Aunabil4602/bnlp-workshop-task2-2023