 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Extractive Summarization by Human Memory Simulation
Paper and Code

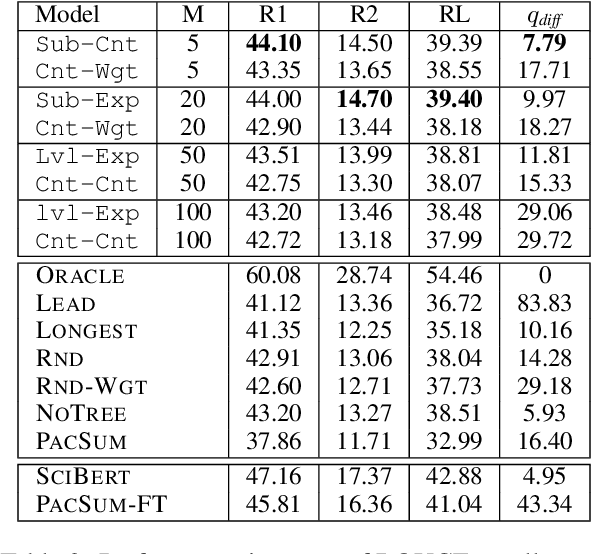

Summarization systems face the core challenge of identifying and selecting important information. In this paper, we tackle the problem of content selection in unsupervised extractive summarization of long, structured documents. We introduce a wide range of heuristics that leverage cognitive representations of content units and how these are retained or forgotten in human memory. We find that properties of these representations of human memory can be exploited to capture relevance of content units in scientific articles. Experiments show that our proposed heuristics are effective at leveraging cognitive structures and the organization of the document (i.e.\ sections of an article), and automatic and human evaluations provide strong evidence that these heuristics extract more summary-worthy content units.