 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Trade-off between Redundancy and Local Coherence in Summarization
Paper and Code

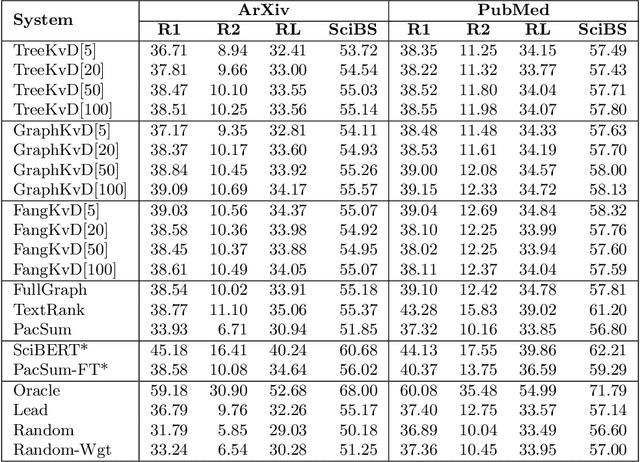

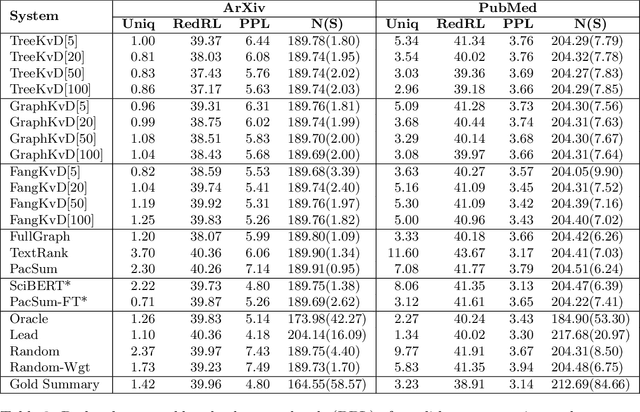
Extractive summarization systems are known to produce poorly coherent and, if not accounted for, highly redundant text. In this work, we tackle the problem of summary redundancy in unsupervised extractive summarization of long, highly-redundant documents. For this, we leverage a psycholinguistic theory of human reading comprehension which directly models local coherence and redundancy. Implementing this theory, our system operates at the proposition level and exploits properties of human memory representations to rank similarly content units that are coherent and non-redundant, hence encouraging the extraction of less redundant final summaries. Because of the impact of the summary length on automatic measures, we control for it by formulating content selection as an optimization problem with soft constraints in the budget of information retrieved. Using summarization of scientific articles as a case study, extensive experiments demonstrate that the proposed systems extract consistently less redundant summaries across increasing levels of document redundancy, whilst maintaining comparable performance (in terms of relevancy and local coherence) against strong unsupervised baselines according to automated evaluations.