 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudiovisual Highlight Detection in Videos
Feb 11, 2021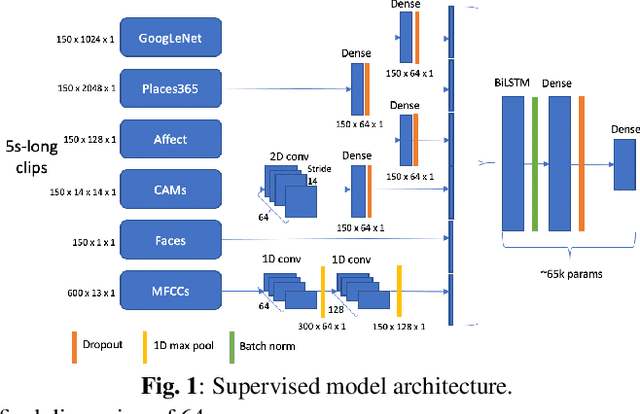
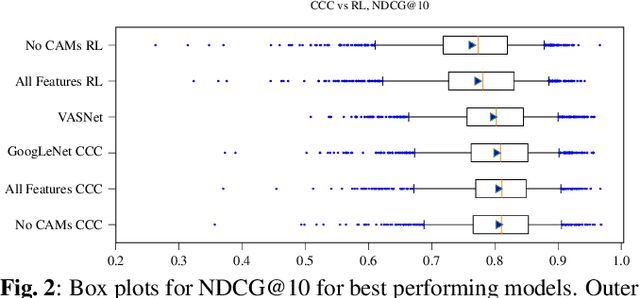
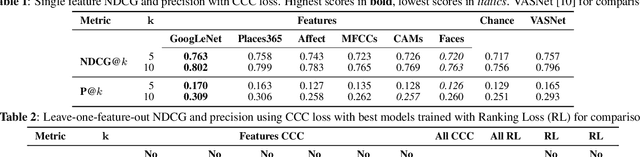
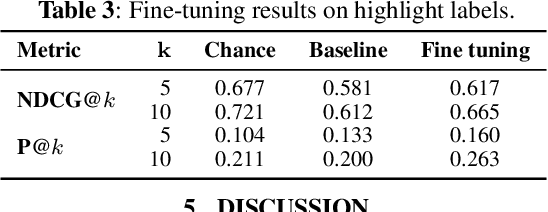
In this paper, we test the hypothesis that interesting events in unstructured videos are inherently audiovisual. We combine deep image representations for object recognition and scene understanding with representations from an audiovisual affect recognition model. To this set, we include content agnostic audio-visual synchrony representations and mel-frequency cepstral coefficients to capture other intrinsic properties of audio. These features are used in a modular supervised model. We present results from two experiments: efficacy study of single features on the task, and an ablation study where we leave one feature out at a time. For the video summarization task, our results indicate that the visual features carry most information, and including audiovisual features improves over visual-only information. To better study the task of highlight detection, we run a pilot experiment with highlights annotations for a small subset of video clips and fine-tune our best model on it. Results indicate that we can transfer knowledge from the video summarization task to a model trained specifically for the task of highlight detection.