Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Generative Model for Score Normalization in Speaker Recognition
Paper and Code
Sep 28, 2017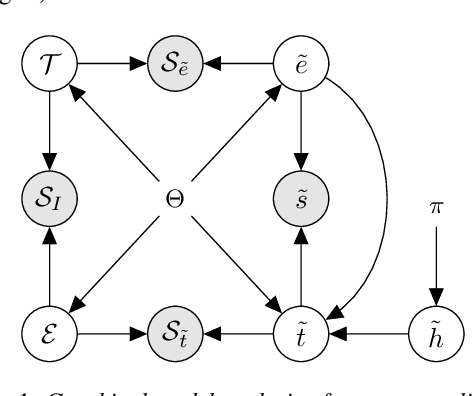
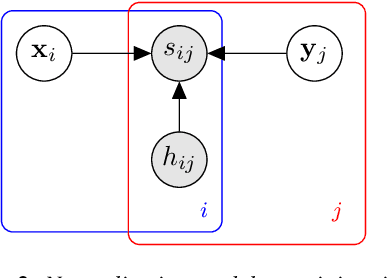
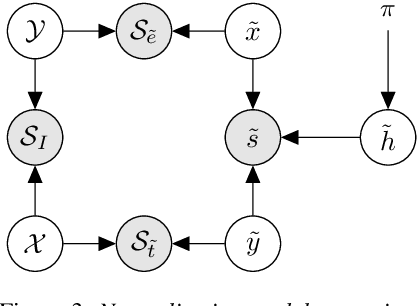
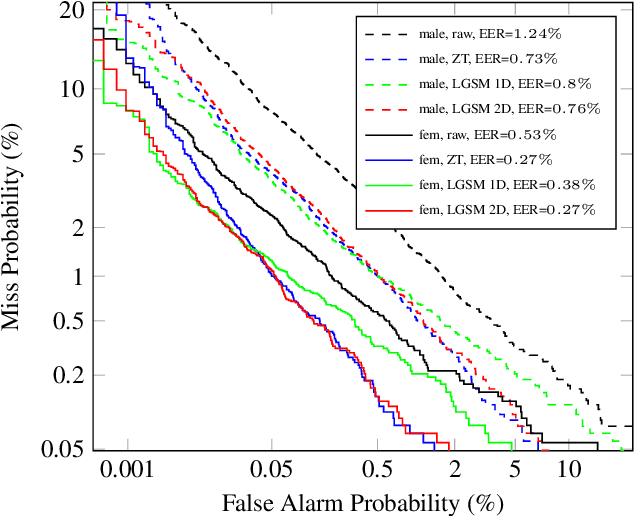
We propose a theoretical framework for thinking about score normalization, which confirms that normalization is not needed under (admittedly fragile) ideal conditions. If, however, these conditions are not met, e.g. under data-set shift between training and runtime, our theory reveals dependencies between scores that could be exploited by strategies such as score normalization. Indeed, it has been demonstrated over and over experimentally, that various ad-hoc score normalization recipes do work. We present a first attempt at using probability theory to design a generative score-space normalization model which gives similar improvements to ZT-norm on the text-dependent RSR 2015 database.
* InterSpeech 2017
View paper on