 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Processing Distortions: Disentangling the Impact of Speech Enhancement Errors on Speech Recognition Performance
Apr 23, 2024



It is challenging to improve automatic speech recognition (ASR) performance in noisy conditions with a single-channel speech enhancement (SE) front-end. This is generally attributed to the processing distortions caused by the nonlinear processing of single-channel SE front-ends. However, the causes of such degraded ASR performance have not been fully investigated. How to design single-channel SE front-ends in a way that significantly improves ASR performance remains an open research question. In this study, we investigate a signal-level numerical metric that can explain the cause of degradation in ASR performance. To this end, we propose a novel analysis scheme based on the orthogonal projection-based decomposition of SE errors. This scheme manually modifies the ratio of the decomposed interference, noise, and artifact errors, and it enables us to directly evaluate the impact of each error type on ASR performance. Our analysis reveals the particularly detrimental effect of artifact errors on ASR performance compared to the other types of errors. This provides us with a more principled definition of processing distortions that cause the ASR performance degradation. Then, we study two practical approaches for reducing the impact of artifact errors. First, we prove that the simple observation adding (OA) post-processing (i.e., interpolating the enhanced and observed signals) can monotonically improve the signal-to-artifact ratio. Second, we propose a novel training objective, called artifact-boosted signal-to-distortion ratio (AB-SDR), which forces the model to estimate the enhanced signals with fewer artifact errors. Through experiments, we confirm that both the OA and AB-SDR approaches are effective in decreasing artifact errors caused by single-channel SE front-ends, allowing them to significantly improve ASR performance.
How does end-to-end speech recognition training impact speech enhancement artifacts?
Nov 20, 2023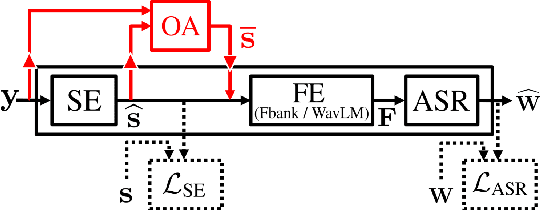
Jointly training a speech enhancement (SE) front-end and an automatic speech recognition (ASR) back-end has been investigated as a way to mitigate the influence of \emph{processing distortion} generated by single-channel SE on ASR. In this paper, we investigate the effect of such joint training on the signal-level characteristics of the enhanced signals from the viewpoint of the decomposed noise and artifact errors. The experimental analyses provide two novel findings: 1) ASR-level training of the SE front-end reduces the artifact errors while increasing the noise errors, and 2) simply interpolating the enhanced and observed signals, which achieves a similar effect of reducing artifacts and increasing noise, improves ASR performance without jointly modifying the SE and ASR modules, even for a strong ASR back-end using a WavLM feature extractor. Our findings provide a better understanding of the effect of joint training and a novel insight for designing an ASR agnostic SE front-end.
How Bad Are Artifacts?: Analyzing the Impact of Speech Enhancement Errors on ASR
Jan 18, 2022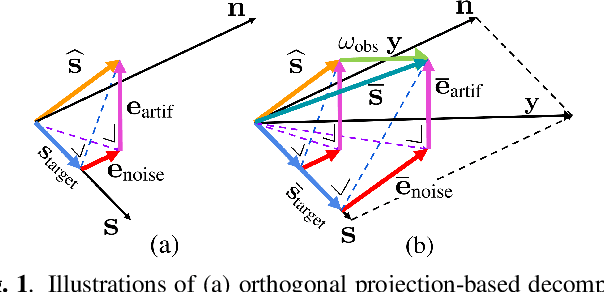
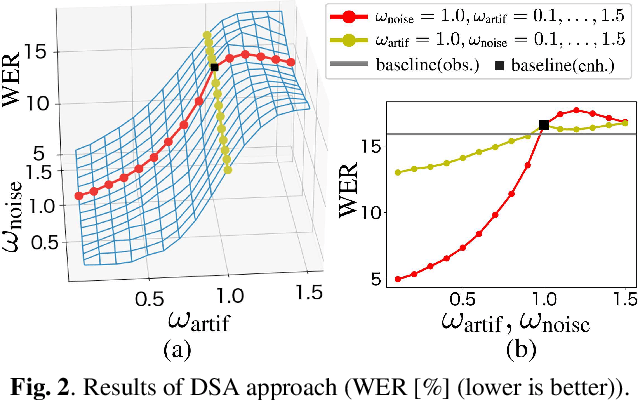
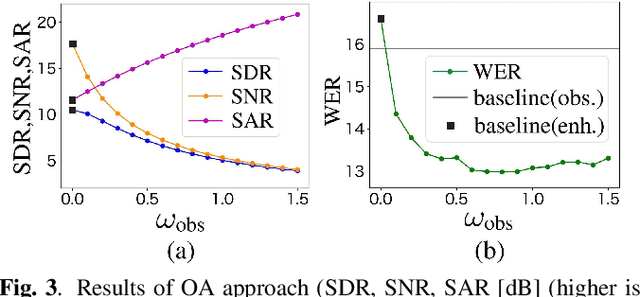
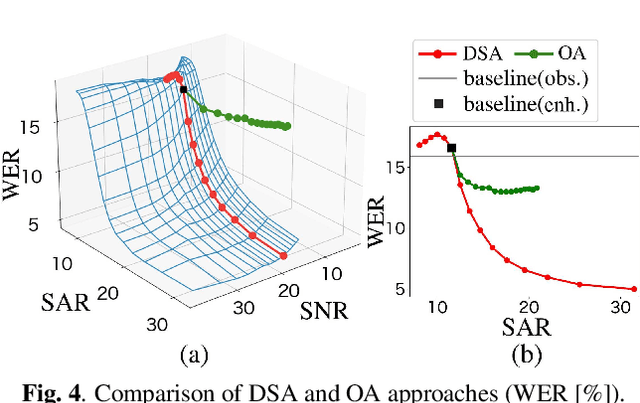
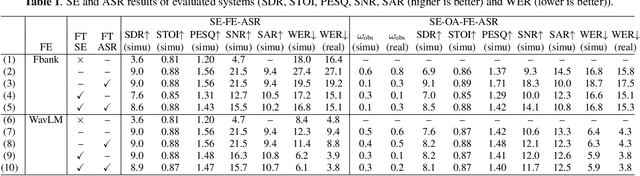
It is challenging to improve automatic speech recognition (ASR) performance in noisy conditions with single-channel speech enhancement (SE). In this paper, we investigate the causes of ASR performance degradation by decomposing the SE errors using orthogonal projection-based decomposition (OPD). OPD decomposes the SE errors into noise and artifact components. The artifact component is defined as the SE error signal that cannot be represented as a linear combination of speech and noise sources. We propose manually scaling the error components to analyze their impact on ASR. We experimentally identify the artifact component as the main cause of performance degradation, and we find that mitigating the artifact can greatly improve ASR performance. Furthermore, we demonstrate that the simple observation adding (OA) technique (i.e., adding a scaled version of the observed signal to the enhanced speech) can monotonically increase the signal-to-artifact ratio under a mild condition. Accordingly, we experimentally confirm that OA improves ASR performance for both simulated and real recordings. The findings of this paper provide a better understanding of the influence of SE errors on ASR and open the door to future research on novel approaches for designing effective single-channel SE front-ends for ASR.
Automatic Node Selection for Deep Neural Networks using Group Lasso Regularization
Nov 17, 2016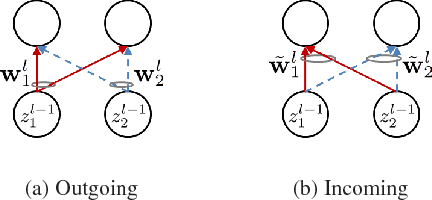
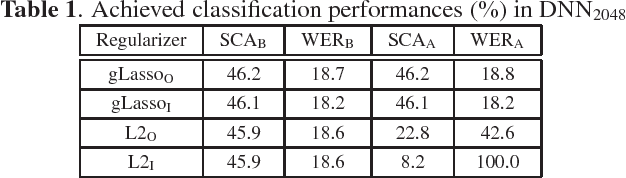
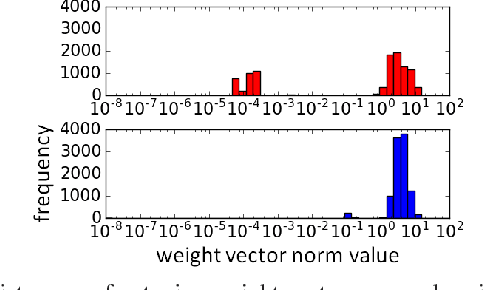
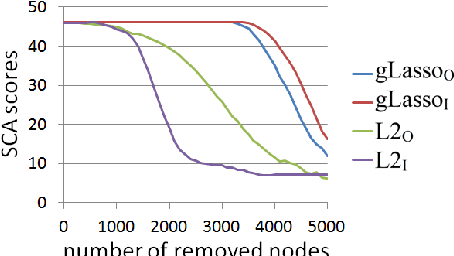
We examine the effect of the Group Lasso (gLasso) regularizer in selecting the salient nodes of Deep Neural Network (DNN) hidden layers by applying a DNN-HMM hybrid speech recognizer to TED Talks speech data. We test two types of gLasso regularization, one for outgoing weight vectors and another for incoming weight vectors, as well as two sizes of DNNs: 2048 hidden layer nodes and 4096 nodes. Furthermore, we compare gLasso and L2 regularizers. Our experiment results demonstrate that our DNN training, in which the gLasso regularizer was embedded, successfully selected the hidden layer nodes that are necessary and sufficient for achieving high classification power.