 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting the Segmentation Model of End-to-End Diarization with Vector Clustering
Jun 13, 2025



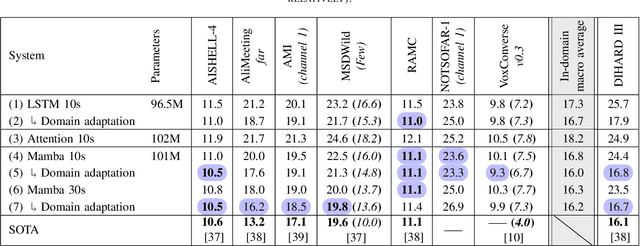
End-to-End Neural Diarization with Vector Clustering is a powerful and practical approach to perform Speaker Diarization. Multiple enhancements have been proposed for the segmentation model of these pipelines, but their synergy had not been thoroughly evaluated. In this work, we provide an in-depth analysis on the impact of major architecture choices on the performance of the pipeline. We investigate different encoders (SincNet, pretrained and finetuned WavLM), different decoders (LSTM, Mamba, and Conformer), different losses (multilabel and multiclass powerset), and different chunk sizes. Through in-depth experiments covering nine datasets, we found that the finetuned WavLM-based encoder always results in the best systems by a wide margin. The LSTM decoder is outclassed by Mamba- and Conformer-based decoders, and while we found Mamba more robust to other architecture choices, it is slightly inferior to our best architecture, which uses a Conformer encoder. We found that multilabel and multiclass powerset losses do not have the same distribution of errors. We confirmed that the multiclass loss helps almost all models attain superior performance, except when finetuning WavLM, in which case, multilabel is the superior choice. We also evaluated the impact of the chunk size on all aforementioned architecture choices and found that newer architectures tend to better handle long chunk sizes, which can greatly improve pipeline performance. Our best system achieved state-of-the-art results on five widely used speaker diarization datasets.
Mamba-based Segmentation Model for Speaker Diarization
Oct 10, 2024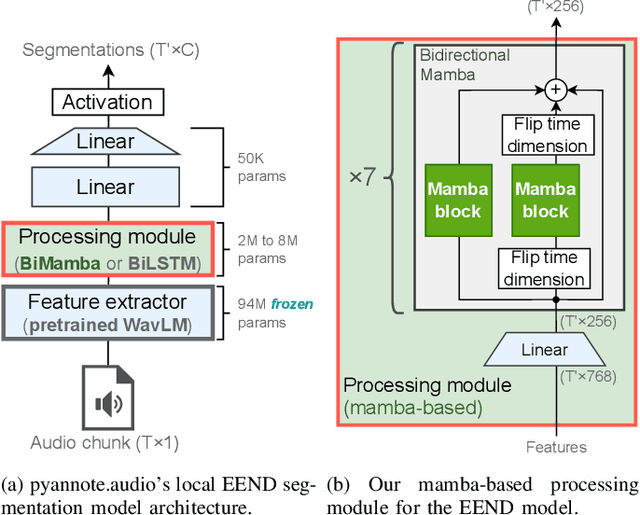
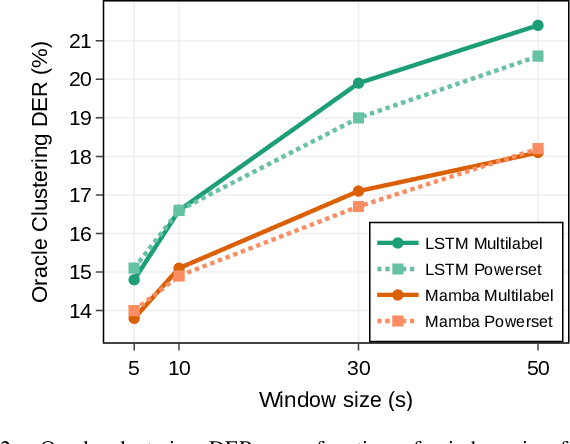
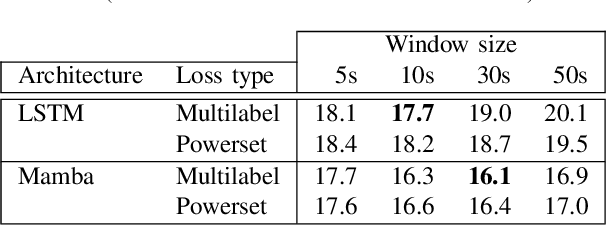
Mamba is a newly proposed architecture which behaves like a recurrent neural network (RNN) with attention-like capabilities. These properties are promising for speaker diarization, as attention-based models have unsuitable memory requirements for long-form audio, and traditional RNN capabilities are too limited. In this paper, we propose to assess the potential of Mamba for diarization by comparing the state-of-the-art neural segmentation of the pyannote pipeline with our proposed Mamba-based variant. Mamba's stronger processing capabilities allow usage of longer local windows, which significantly improve diarization quality by making the speaker embedding extraction more reliable. We find Mamba to be a superior alternative to both traditional RNN and the tested attention-based model. Our proposed Mamba-based system achieves state-of-the-art performance on three widely used diarization datasets.
On the calibration of powerset speaker diarization models
Sep 24, 2024End-to-end neural diarization models have usually relied on a multilabel-classification formulation of the speaker diarization problem. Recently, we proposed a powerset multiclass formulation that has beaten the state-of-the-art on multiple datasets. In this paper, we propose to study the calibration of a powerset speaker diarization model, and explore some of its uses. We study the calibration in-domain, as well as out-of-domain, and explore the data in low-confidence regions. The reliability of model confidence is then tested in practice: we use the confidence of the pretrained model to selectively create training and validation subsets out of unannotated data, and compare this to random selection. We find that top-label confidence can be used to reliably predict high-error regions. Moreover, training on low-confidence regions provides a better calibrated model, and validating on low-confidence regions can be more annotation-efficient than random regions.
NTT Multi-Speaker ASR System for the DASR Task of CHiME-8 Challenge
Sep 09, 2024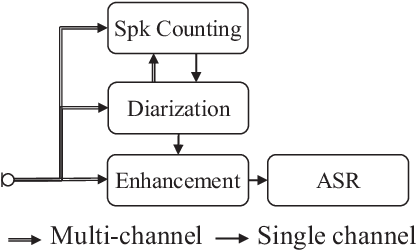
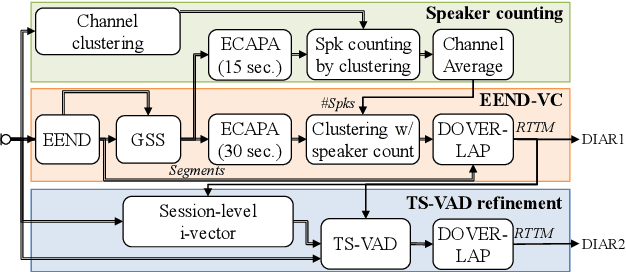

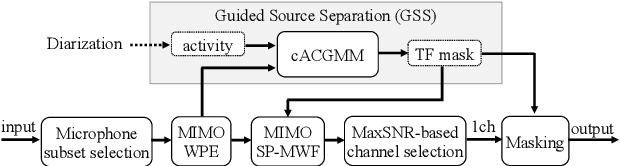
We present a distant automatic speech recognition (DASR) system developed for the CHiME-8 DASR track. It consists of a diarization first pipeline. For diarization, we use end-to-end diarization with vector clustering (EEND-VC) followed by target speaker voice activity detection (TS-VAD) refinement. To deal with various numbers of speakers, we developed a new multi-channel speaker counting approach. We then apply guided source separation (GSS) with several improvements to the baseline system. Finally, we perform ASR using a combination of systems built from strong pre-trained models. Our proposed system achieves a macro tcpWER of 21.3 % on the dev set, which is a 57 % relative improvement over the baseline.
Powerset multi-class cross entropy loss for neural speaker diarization
Oct 19, 2023


Since its introduction in 2019, the whole end-to-end neural diarization (EEND) line of work has been addressing speaker diarization as a frame-wise multi-label classification problem with permutation-invariant training. Despite EEND showing great promise, a few recent works took a step back and studied the possible combination of (local) supervised EEND diarization with (global) unsupervised clustering. Yet, these hybrid contributions did not question the original multi-label formulation. We propose to switch from multi-label (where any two speakers can be active at the same time) to powerset multi-class classification (where dedicated classes are assigned to pairs of overlapping speakers). Through extensive experiments on 9 different benchmarks, we show that this formulation leads to significantly better performance (mostly on overlapping speech) and robustness to domain mismatch, while eliminating the detection threshold hyperparameter, critical for the multi-label formulation.