 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Multichannel Wiener Filtering for Wireless Acoustic Sensor Networks
Mar 10, 2026In a wireless acoustic sensor network (WASN), devices (i.e., nodes) can collaborate through distributed algorithms to collectively perform audio signal processing tasks. This paper focuses on the distributed estimation of node-specific desired speech signals using network-wide Wiener filtering. The objective is to match the performance of a centralized system that would have access to all microphone signals, while reducing the communication bandwidth usage of the algorithm. Existing solutions, such as the distributed adaptive node-specific signal estimation (DANSE) algorithm, converge towards the multichannel Wiener filter (MWF) which solves a centralized linear minimum mean square error (LMMSE) signal estimation problem. However, they do so iteratively, which can be slow and impractical. Many solutions also assume that all nodes observe the same set of sources of interest, which is often not the case in practice. To overcome these limitations, we propose the distributed multichannel Wiener filter (dMWF) for fully connected WASNs. The dMWF is non-iterative and optimal even when nodes observe different sets of sources. In this algorithm, nodes exchange neighbor-pair-specific, low-dimensional (fused) signals estimating the contribution of sources observed by both nodes in the pair. We formally prove the optimality of dMWF and demonstrate its performance in simulated speech enhancement experiments. The proposed algorithm is shown to outperform DANSE in terms of objective metrics after short operation times, highlighting the benefit of its iterationless design.
DNN-Based Online Source Counting Based on Spatial Generalized Magnitude Squared Coherence
Jan 28, 2026The number of active sound sources is a key parameter in many acoustic signal processing tasks, such as source localization, source separation, and multi-microphone speech enhancement. This paper proposes a novel method for online source counting by detecting changes in the number of active sources based on spatial coherence. The proposed method exploits the fact that a single coherent source in spatially white background noise yields high spatial coherence, whereas only noise results in low spatial coherence. By applying a spatial whitening operation, the source counting problem is reformulated as a change detection task, aiming to identify the time frames when the number of active sources changes. The method leverages the generalized magnitude-squared coherence as a measure to quantify spatial coherence, providing features for a compact neural network trained to detect source count changes framewise. Simulation results with binaural hearing aids in reverberant acoustic scenes with up to 4 speakers and background noise demonstrate the effectiveness of the proposed method for online source counting.
Closed-Form Successive Relative Transfer Function Vector Estimation based on Blind Oblique Projection Incorporating Noise Whitening
Aug 06, 2025Relative transfer functions (RTFs) of sound sources play a crucial role in beamforming, enabling effective noise and interference suppression. This paper addresses the challenge of online estimating the RTF vectors of multiple sound sources in noisy and reverberant environments, for the specific scenario where sources activate successively. While the RTF vector of the first source can be estimated straightforwardly, the main challenge arises in estimating the RTF vectors of subsequent sources during segments where multiple sources are simultaneously active. The blind oblique projection (BOP) method has been proposed to estimate the RTF vector of a newly activating source by optimally blocking this source. However, this method faces several limitations: high computational complexity due to its reliance on iterative gradient descent optimization, the introduction of random additional vectors, which can negatively impact performance, and the assumption of high signal-to-noise ratio (SNR). To overcome these limitations, in this paper we propose three extensions to the BOP method. First, we derive a closed-form solution for optimizing the BOP cost function, significantly reducing computational complexity. Second, we introduce orthogonal additional vectors instead of random vectors, enhancing RTF vector estimation accuracy. Third, we incorporate noise handling techniques inspired by covariance subtraction and whitening, increasing robustness in low SNR conditions. To provide a frame-by-frame estimate of the source activity pattern, required by both the conventional BOP method and the proposed method, we propose a spatial-coherence-based online source counting method. Simulations are performed with real-world reverberant noisy recordings featuring 3 successively activating speakers, with and without a-priori knowledge of the source activity pattern.
Relative Transfer Function Vector Estimation for Acoustic Sensor Networks Exploiting Covariance Matrix Structure
Oct 27, 2023
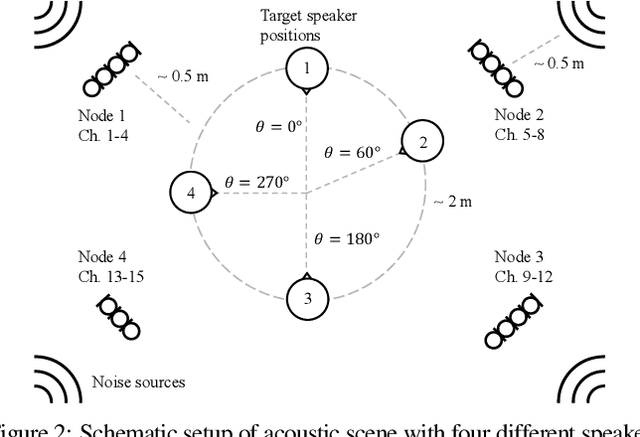

In many multi-microphone algorithms for noise reduction, an estimate of the relative transfer function (RTF) vector of the target speaker is required. The state-of-the-art covariance whitening (CW) method estimates the RTF vector as the principal eigenvector of the whitened noisy covariance matrix, where whitening is performed using an estimate of the noise covariance matrix. In this paper, we consider an acoustic sensor network consisting of multiple microphone nodes. Assuming uncorrelated noise between the nodes but not within the nodes, we propose two RTF vector estimation methods that leverage the block-diagonal structure of the noise covariance matrix. The first method modifies the CW method by considering only the diagonal blocks of the estimated noise covariance matrix. In contrast, the second method only considers the off-diagonal blocks of the noisy covariance matrix, but cannot be solved using a simple eigenvalue decomposition. When applying the estimated RTF vector in a minimum variance distortionless response beamformer, simulation results for real-world recordings in a reverberant environment with multiple noise sources show that the modified CW method performs slightly better than the CW method in terms of SNR improvement, while the off-diagonal selection method outperforms a biased RTF vector estimate obtained as the principal eigenvector of the noisy covariance matrix.
Covariance Blocking and Whitening Method for Successive Relative Transfer Function Vector Estimation in Multi-Speaker Scenarios
Oct 25, 2023


This paper addresses the challenge of estimating the relative transfer function (RTF) vectors of multiple speakers in a noisy and reverberant environment. More specifically, we consider a scenario where two speakers activate successively. In this scenario, the RTF vector of the first speaker can be estimated in a straightforward way and the main challenge lies in estimating the RTF vector of the second speaker during segments where both speakers are simultaneously active. To estimate the RTF vector of the second speaker the so-called blind oblique projection (BOP) method determines the oblique projection operator that optimally blocks the second speaker. Instead of blocking the second speaker, in this paper we propose a covariance blocking and whitening (CBW) method, which first blocks the first speaker and applies whitening using the estimated noise covariance matrix and then estimates the RTF vector of the second speaker based on a singular value decomposition. When using the estimated RTF vectors of both speakers in a linearly constrained minimum variance beamformer, simulation results using real-world recordings for multiple speaker positions demonstrate that the proposed CBW method outperforms the conventional BOP and covariance whitening methods in terms of signal-to-interferer-and-noise ratio improvement.
Adaptive Dereverberation, Noise and Interferer Reduction Using Sparse Weighted Linearly Constrained Minimum Power Beamforming
Mar 13, 2023


Interfering sources, background noise and reverberation degrade speech quality and intelligibility in hearing aid applications. In this paper, we present an adaptive algorithm aiming at dereverberation, noise and interferer reduction and preservation of binaural cues based on the wBLCMP beamformer. The wBLCMP beamformer unifies the multi-channel weighted prediction error method performing dereverberation and the linearly constrained minimum power beamformer performing noise and interferer reduction into a single convolutional beamformer. We propose to adaptively compute the optimal filter by incorporating an exponential window into a sparsity-promoting lp-norm cost function, which enables to track a moving target speaker. Simulation results with successive target speakers at different positions show that the proposed adaptive version of the wBLCMP beamformer outperforms a non-adaptive version in terms of objective speech enhancement performance measures.
Joint Multi-Channel Dereverberation and Noise Reduction Using a Unified Convolutional Beamformer With Sparse Priors
Jun 03, 2021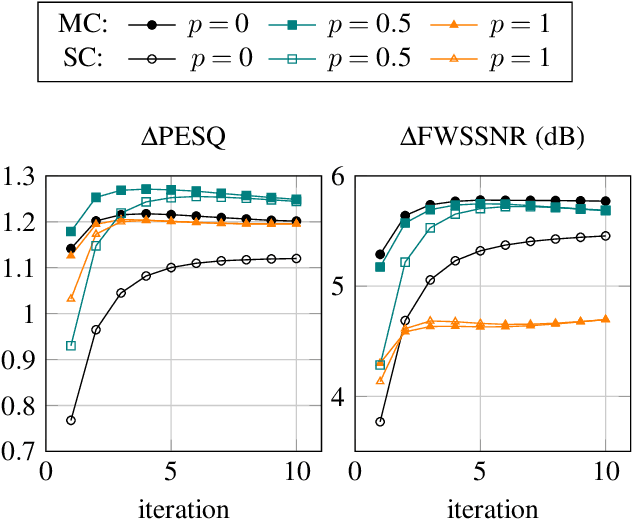
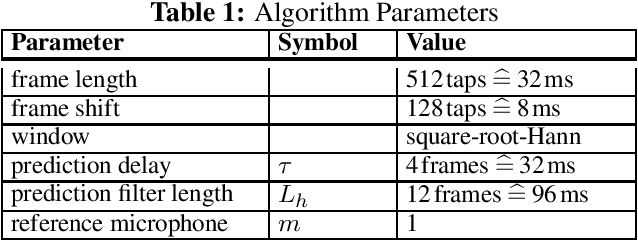
Recently, the convolutional weighted power minimization distortionless response (WPD) beamformer was proposed, which unifies multi-channel weighted prediction error dereverberation and minimum power distortionless response beamforming. To optimize the convolutional filter, the desired speech component is modeled with a time-varying Gaussian model, which promotes the sparsity of the desired speech component in the short-time Fourier transform domain compared to the noisy microphone signals. In this paper we generalize the convolutional WPD beamformer by using an lp-norm cost function, introducing an adjustable shape parameter which enables to control the sparsity of the desired speech component. Experiments based on the REVERB challenge dataset show that the proposed method outperforms the conventional convolutional WPD beamformer in terms of objective speech quality metrics.