 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Multi-Channel Dereverberation and Noise Reduction Using a Unified Convolutional Beamformer With Sparse Priors
Paper and Code
Jun 03, 2021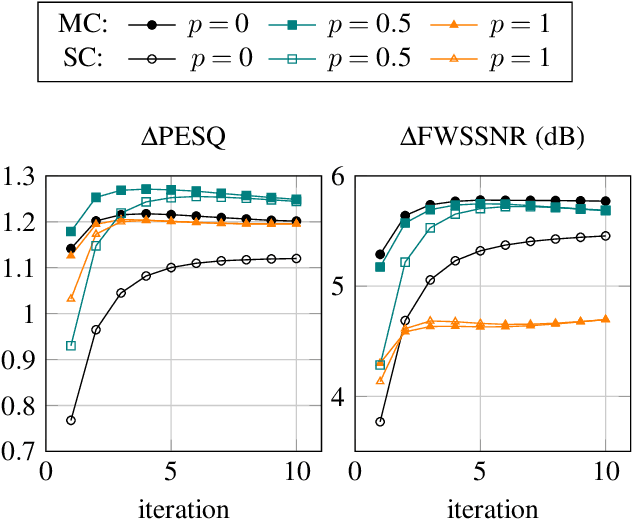
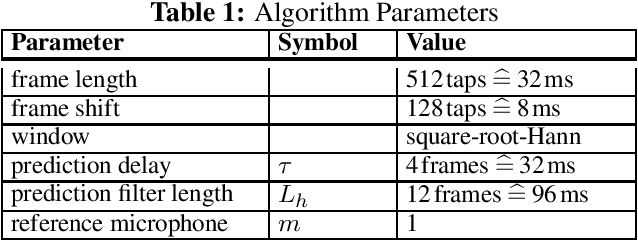
Recently, the convolutional weighted power minimization distortionless response (WPD) beamformer was proposed, which unifies multi-channel weighted prediction error dereverberation and minimum power distortionless response beamforming. To optimize the convolutional filter, the desired speech component is modeled with a time-varying Gaussian model, which promotes the sparsity of the desired speech component in the short-time Fourier transform domain compared to the noisy microphone signals. In this paper we generalize the convolutional WPD beamformer by using an lp-norm cost function, introducing an adjustable shape parameter which enables to control the sparsity of the desired speech component. Experiments based on the REVERB challenge dataset show that the proposed method outperforms the conventional convolutional WPD beamformer in terms of objective speech quality metrics.