 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Multi-Frame MVDR Filtering for Binaural Noise Reduction
Paper and Code
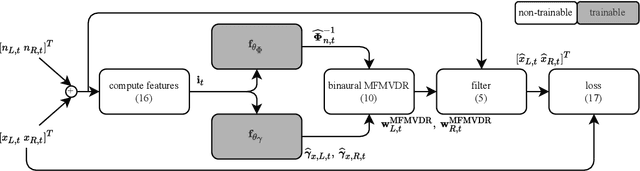
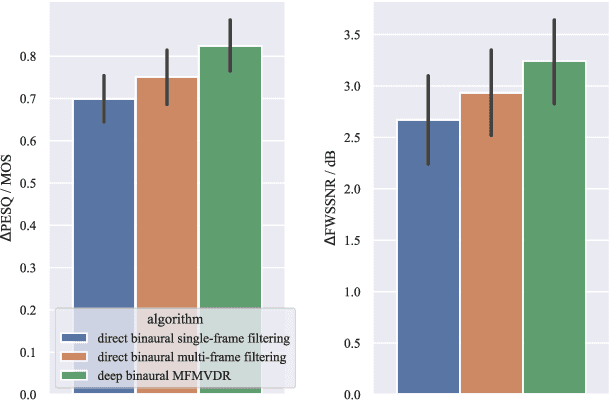
To improve speech intelligibility and speech quality in noisy environments, binaural noise reduction algorithms for head-mounted assistive listening devices are of crucial importance. Several binaural noise reduction algorithms such as the well-known binaural minimum variance distortionless response (MVDR) beamformer have been proposed, which exploit spatial correlations of both the target speech and the noise components. Furthermore, for single-microphone scenarios, multi-frame algorithms such as the multi-frame MVDR (MFMVDR) filter have been proposed, which exploit temporal instead of spatial correlations. In this contribution, we propose a binaural extension of the MFMVDR filter, which exploits both spatial and temporal correlations. The binaural MFMVDR filters are embedded in an end-to-end deep learning framework, where the required parameters, i.e., the speech spatio-temporal correlation vectors as well as the (inverse) noise spatio-temporal covariance matrix, are estimated by temporal convolutional networks (TCNs) that are trained by minimizing the mean spectral absolute error loss function. Simulation results comprising measured binaural room impulses and diverse noise sources at signal-to-noise ratios from -5 dB to 20 dB demonstrate the advantage of utilizing the binaural MFMVDR filter structure over directly estimating the binaural multi-frame filter coefficients with TCNs.