 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack Box Lie Group Preconditioners for SGD
Nov 08, 2022A matrix free and a low rank approximation preconditioner are proposed to accelerate the convergence of stochastic gradient descent (SGD) by exploiting curvature information sampled from Hessian-vector products or finite differences of parameters and gradients similar to the BFGS algorithm. Both preconditioners are fitted with an online updating manner minimizing a criterion that is free of line search and robust to stochastic gradient noise, and further constrained to be on certain connected Lie groups to preserve their corresponding symmetry or invariance, e.g., orientation of coordinates by the connected general linear group with positive determinants. The Lie group's equivariance property facilitates preconditioner fitting, and its invariance property saves any need of damping, which is common in second-order optimizers, but difficult to tune. The learning rate for parameter updating and step size for preconditioner fitting are naturally normalized, and their default values work well in most situations.
Dictionary-Based Fusion of Contact and Acoustic Microphones for Wind Noise Reduction
May 18, 2022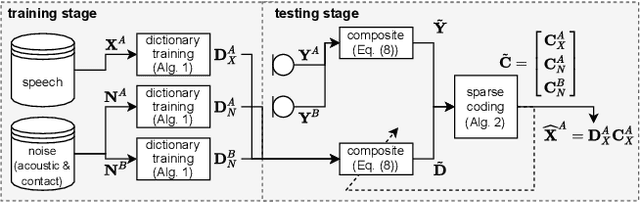
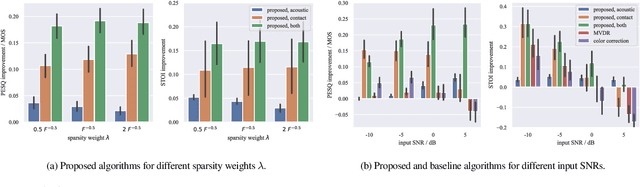
In mobile speech communication applications, wind noise can lead to a severe reduction of speech quality and intelligibility. Since the performance of speech enhancement algorithms using acoustic microphones tends to substantially degrade in extremely challenging scenarios, auxiliary sensors such as contact microphones can be used. Although contact microphones offer a much lower recorded wind noise level, they come at the cost of speech distortion and additional noise components. Aiming at exploiting the advantages of acoustic and contact microphones for wind noise reduction, in this paper we propose to extend conventional single-microphone dictionary-based speech enhancement approaches by simultaneously modeling the acoustic and contact microphone signals. We propose to train a single speech dictionary and two noise dictionaries and use a relative transfer function to model the relationship between the speech components at the microphones. Simulation results show that the proposed approach yields improvements in both speech quality and intelligibility compared to several baseline approaches, most notably approaches using only the contact microphones or only the acoustic microphone.
Hand-tremor frequency estimation in videos
Sep 10, 2018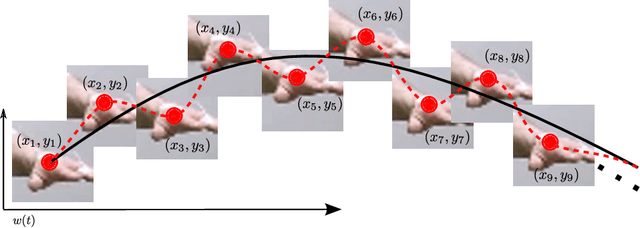
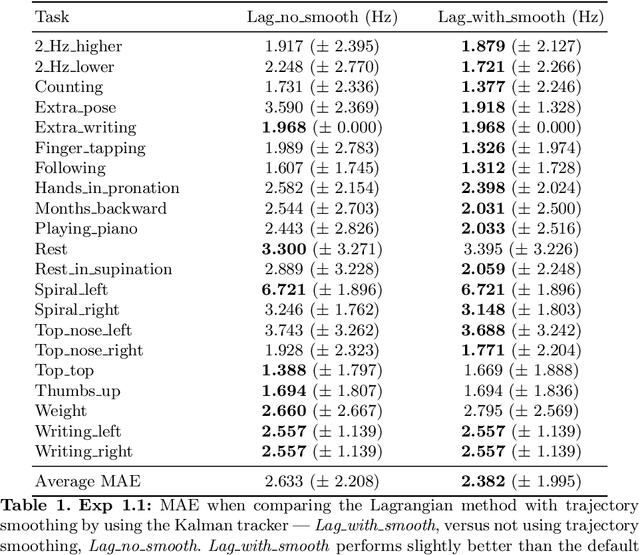
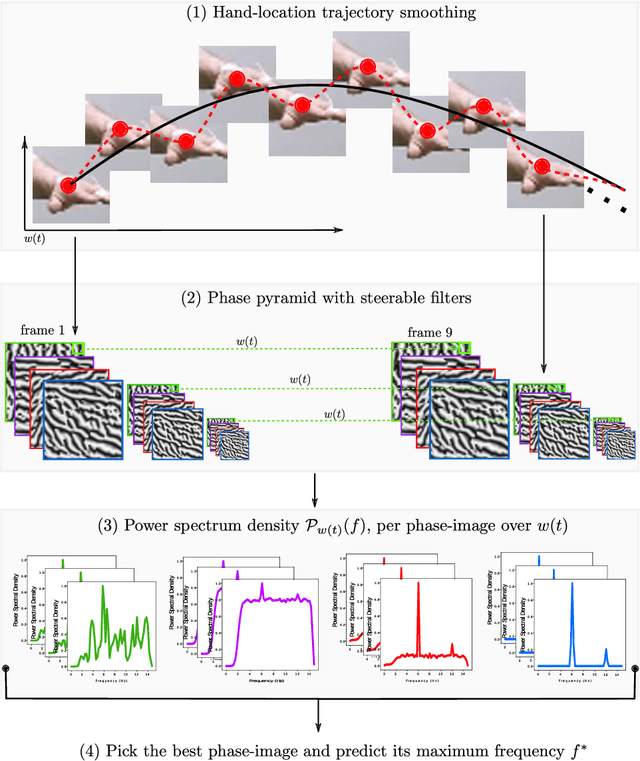
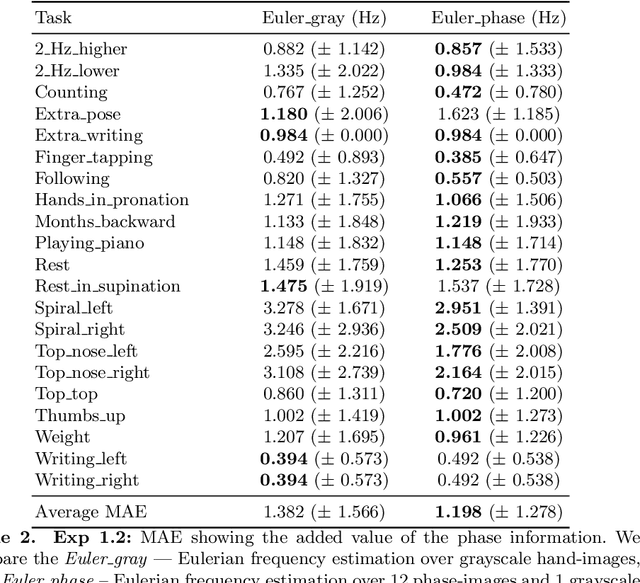
We focus on the problem of estimating human hand-tremor frequency from input RGB video data. Estimating tremors from video is important for non-invasive monitoring, analyzing and diagnosing patients suffering from motor-disorders such as Parkinson's disease. We consider two approaches for hand-tremor frequency estimation: (a) a Lagrangian approach where we detect the hand at every frame in the video, and estimate the tremor frequency along the trajectory; and (b) an Eulerian approach where we first localize the hand, we subsequently remove the large motion along the movement trajectory of the hand, and we use the video information over time encoded as intensity values or phase information to estimate the tremor frequency. We estimate hand tremors on a new human tremor dataset, TIM-Tremor, containing static tasks as well as a multitude of more dynamic tasks, involving larger motion of the hands. The dataset has 55 tremor patient recordings together with: associated ground truth accelerometer data from the most affected hand, RGB video data, and aligned depth data.