 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference Microphone Selection for the Weighted Prediction Error Algorithm using the Normalized L-p Norm
Nov 05, 2024


Reverberation may severely degrade the quality of speech signals recorded using microphones in a room. For compact microphone arrays, the choice of the reference microphone for multi-microphone dereverberation typically does not have a large influence on the dereverberation performance. In contrast, when the microphones are spatially distributed, the choice of the reference microphone may significantly contribute to the dereverberation performance. In this paper, we propose to perform reference microphone selection for the weighted prediction error (WPE) dereverberation algorithm based on the normalized $\ell_p$-norm of the dereverberated output signal. Experimental results for different source positions in a reverberant laboratory show that the proposed method yields a better dereverberation performance than reference microphone selection based on the early-to-late reverberation ratio or signal power.
Long-Term Conversation Analysis: Privacy-Utility Trade-off under Noise and Reverberation
Aug 01, 2024

Recordings in everyday life require privacy preservation of the speech content and speaker identity. This contribution explores the influence of noise and reverberation on the trade-off between privacy and utility for low-cost privacy-preserving methods feasible for edge computing. These methods compromise spectral and temporal smoothing, speaker anonymization using the McAdams coefficient, sampling with a very low sampling rate, and combinations. Privacy is assessed by automatic speech and speaker recognition, while our utility considers voice activity detection and speaker diarization. Overall, our evaluation shows that additional noise degrades the performance of all models more than reverberation. This degradation corresponds to enhanced speech privacy, while utility is less deteriorated for some methods.
Microphone Subset Selection for the Weighted Prediction Error Algorithm using a Group Sparsity Penalty
Jan 16, 2024



Reverberation can severely degrade the quality of speech signals recorded using microphones in an enclosure. In acoustic sensor networks with spatially distributed microphones, a similar dereverberation performance may be achieved using only a subset of all available microphones. Using the popular convex relaxation method, in this paper we propose to perform microphone subset selection for the weighted prediction error (WPE) multi-channel dereverberation algorithm by introducing a group sparsity penalty on the prediction filter coefficients. The resulting problem is shown to be solved efficiently using the accelerated proximal gradient algorithm. Experimental evaluation using measured impulse responses shows that the performance of the proposed method is close to the optimal performance obtained by exhaustive search, both for frequency-dependent as well as frequency-independent microphone subset selection. Furthermore, the performance using only a few microphones for frequency-independent microphone subset selection is only marginally worse than using all available microphones.
Long-term Conversation Analysis: Exploring Utility and Privacy
Jun 28, 2023



The analysis of conversations recorded in everyday life requires privacy protection. In this contribution, we explore a privacy-preserving feature extraction method based on input feature dimension reduction, spectral smoothing and the low-cost speaker anonymization technique based on McAdams coefficient. We assess the utility of the feature extraction methods with a voice activity detection and a speaker diarization system, while privacy protection is determined with a speech recognition and a speaker verification model. We show that the combination of McAdams coefficient and spectral smoothing maintains the utility while improving privacy.
Two-Stage Voice Anonymization for Enhanced Privacy
Jun 28, 2023



In recent years, the need for privacy preservation when manipulating or storing personal data, including speech , has become a major issue. In this paper, we present a system addressing the speaker-level anonymization problem. We propose and evaluate a two-stage anonymization pipeline exploiting a state-of-the-art anonymization model described in the Voice Privacy Challenge 2022 in combination with a zero-shot voice conversion architecture able to capture speaker characteristics from a few seconds of speech. We show this architecture can lead to strong privacy preservation while preserving pitch information. Finally, we propose a new compressed metric to evaluate anonymization systems in privacy scenarios with different constraints on privacy and utility.
Dereverberation in Acoustic Sensor Networks Using Weighted Prediction Error With Microphone-dependent Prediction Delays
Jan 18, 2023


In the last decades several multi-microphone speech dereverberation algorithms have been proposed, among which the weighted prediction error (WPE) algorithm. In the WPE algorithm, a prediction delay is required to reduce the correlation between the prediction signals and the direct component in the reference microphone signal. In compact arrays with closely-spaced microphones, the prediction delay is often chosen microphone-independent. In acoustic sensor networks with spatially distributed microphones, large time-differences-of-arrival (TDOAs) of the speech source between the reference microphone and other microphones typically occur. Hence, when using a microphone-independent prediction delay the reference and prediction signals may still be significantly correlated, leading to distortion in the dereverberated output signal. In order to decorrelate the signals, in this paper we propose to apply TDOA compensation with respect to the reference microphone, resulting in microphone-dependent prediction delays for the WPE algorithm. We consider both optimal TDOA compensation using crossband filtering in the short-time Fourier transform domain as well as band-to-band and integer delay approximations. Simulation results for different reverberation times using oracle as well as estimated TDOAs clearly show the benefit of using microphone-dependent prediction delays.
Geometry-aware DoA Estimation using a Deep Neural Network with mixed-data input features
Dec 09, 2022

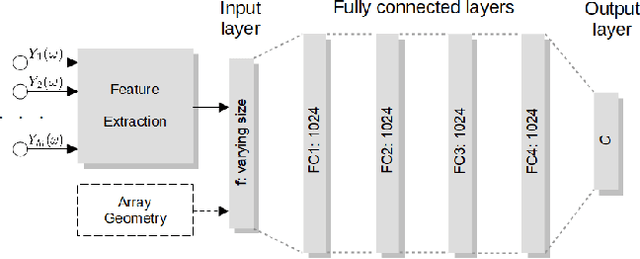

Unlike model-based direction of arrival (DoA) estimation algorithms, supervised learning-based DoA estimation algorithms based on deep neural networks (DNNs) are usually trained for one specific microphone array geometry, resulting in poor performance when applied to a different array geometry. In this paper we illustrate the fundamental difference between supervised learning-based and model-based algorithms leading to this sensitivity. Aiming at designing a supervised learning-based DoA estimation algorithm that generalizes well to different array geometries, in this paper we propose a geometry-aware DoA estimation algorithm. The algorithm uses a fully connected DNN and takes mixed data as input features, namely the time lags maximizing the generalized cross-correlation with phase transform and the microphone coordinates, which are assumed to be known. Experimental results for a reverberant scenario demonstrate the flexibility of the proposed algorithm towards different array geometries and show that the proposed algorithm outperforms model-based algorithms such as steered response power with phase transform.
Signal-informed DNN-based DOA Estimation combining an External Microphone and GCC-PHAT Features
Jun 11, 2022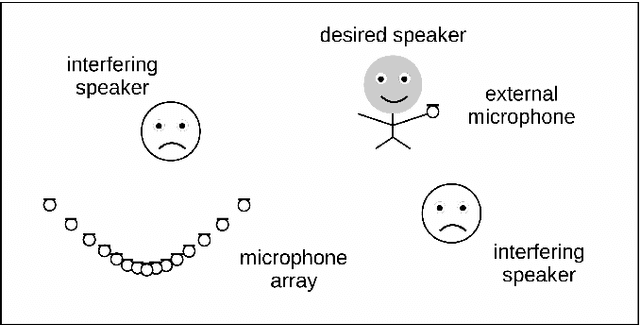


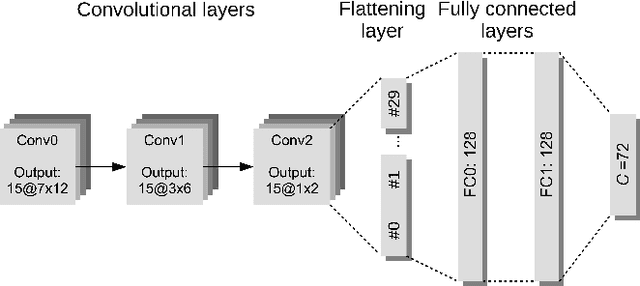
Aiming at estimating the direction of arrival (DOA) of a desired speaker in a multi-talker environment using a microphone array, in this paper we propose a signal-informed method exploiting the availability of an external microphone attached to the desired speaker. The proposed method applies a binary mask to the GCC-PHAT input features of a convolutional neural network, where the binary mask is computed based on the power distribution of the external microphone signal. Experimental results for a reverberant scenario with up to four interfering speakers demonstrate that the signal-informed masking improves the localization accuracy, without requiring any knowledge about the interfering speakers.