 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero Shot Text to Speech Augmentation for Automatic Speech Recognition on Low-Resource Accented Speech Corpora
Sep 17, 2024In recent years, automatic speech recognition (ASR) models greatly improved transcription performance both in clean, low noise, acoustic conditions and in reverberant environments. However, all these systems rely on the availability of hundreds of hours of labelled training data in specific acoustic conditions. When such a training dataset is not available, the performance of the system is heavily impacted. For example, this happens when a specific acoustic environment or a particular population of speakers is under-represented in the training dataset. Specifically, in this paper we investigate the effect of accented speech data on an off-the-shelf ASR system. Furthermore, we suggest a strategy based on zero-shot text-to-speech to augment the accented speech corpora. We show that this augmentation method is able to mitigate the loss in performance of the ASR system on accented data up to 5% word error rate reduction (WERR). In conclusion, we demonstrate that by incorporating a modest fraction of real with synthetically generated data, the ASR system exhibits superior performance compared to a model trained exclusively on authentic accented speech with up to 14% WERR.
Long-Term Conversation Analysis: Privacy-Utility Trade-off under Noise and Reverberation
Aug 01, 2024

Recordings in everyday life require privacy preservation of the speech content and speaker identity. This contribution explores the influence of noise and reverberation on the trade-off between privacy and utility for low-cost privacy-preserving methods feasible for edge computing. These methods compromise spectral and temporal smoothing, speaker anonymization using the McAdams coefficient, sampling with a very low sampling rate, and combinations. Privacy is assessed by automatic speech and speaker recognition, while our utility considers voice activity detection and speaker diarization. Overall, our evaluation shows that additional noise degrades the performance of all models more than reverberation. This degradation corresponds to enhanced speech privacy, while utility is less deteriorated for some methods.
Speaker anonymization using neural audio codec language models
Sep 28, 2023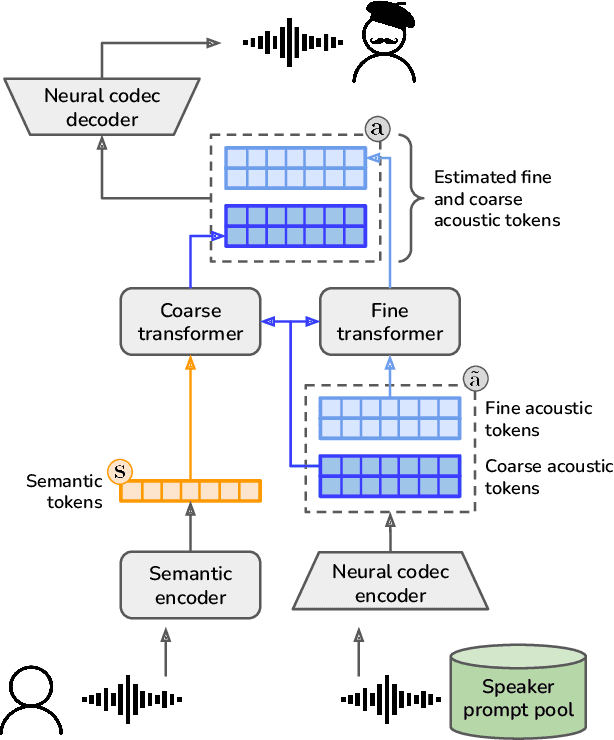
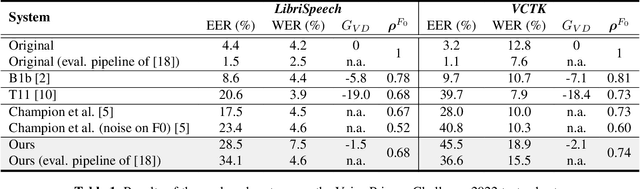
The vast majority of approaches to speaker anonymization involve the extraction of fundamental frequency estimates, linguistic features and a speaker embedding which is perturbed to obfuscate the speaker identity before an anonymized speech waveform is resynthesized using a vocoder. Recent work has shown that x-vector transformations are difficult to control consistently: other sources of speaker information contained within fundamental frequency and linguistic features are re-entangled upon vocoding, meaning that anonymized speech signals still contain speaker information. We propose an approach based upon neural audio codecs (NACs), which are known to generate high-quality synthetic speech when combined with language models. NACs use quantized codes, which are known to effectively bottleneck speaker-related information: we demonstrate the potential of speaker anonymization systems based on NAC language modeling by applying the evaluation framework of the Voice Privacy Challenge 2022.
Long-term Conversation Analysis: Exploring Utility and Privacy
Jun 28, 2023



The analysis of conversations recorded in everyday life requires privacy protection. In this contribution, we explore a privacy-preserving feature extraction method based on input feature dimension reduction, spectral smoothing and the low-cost speaker anonymization technique based on McAdams coefficient. We assess the utility of the feature extraction methods with a voice activity detection and a speaker diarization system, while privacy protection is determined with a speech recognition and a speaker verification model. We show that the combination of McAdams coefficient and spectral smoothing maintains the utility while improving privacy.
Two-Stage Voice Anonymization for Enhanced Privacy
Jun 28, 2023



In recent years, the need for privacy preservation when manipulating or storing personal data, including speech , has become a major issue. In this paper, we present a system addressing the speaker-level anonymization problem. We propose and evaluate a two-stage anonymization pipeline exploiting a state-of-the-art anonymization model described in the Voice Privacy Challenge 2022 in combination with a zero-shot voice conversion architecture able to capture speaker characteristics from a few seconds of speech. We show this architecture can lead to strong privacy preservation while preserving pitch information. Finally, we propose a new compressed metric to evaluate anonymization systems in privacy scenarios with different constraints on privacy and utility.
Relative Acoustic Features for Distance Estimation in Smart-Homes
Dec 02, 2022



Any audio recording encapsulates the unique fingerprint of the associated acoustic environment, namely the background noise and reverberation. Considering the scenario of a room equipped with a fixed smart speaker device with one or more microphones and a wearable smart device (watch, glasses or smartphone), we employed the improved proportionate normalized least mean square adaptive filter to estimate the relative room impulse response mapping the audio recordings of the two devices. We performed inter-device distance estimation by exploiting a new set of features obtained extending the definition of some acoustic attributes of the room impulse response to its relative version. In combination with the sparseness measure of the estimated relative room impulse response, the relative features allow precise inter-device distance estimation which can be exploited for tasks such as best microphone selection or acoustic scene analysis. Experimental results from simulated rooms of different dimensions and reverberation times demonstrate the effectiveness of this computationally lightweight approach for smart home acoustic ranging applications