 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Complexity Own Voice Reconstruction for Hearables with an In-Ear Microphone
Paper and Code
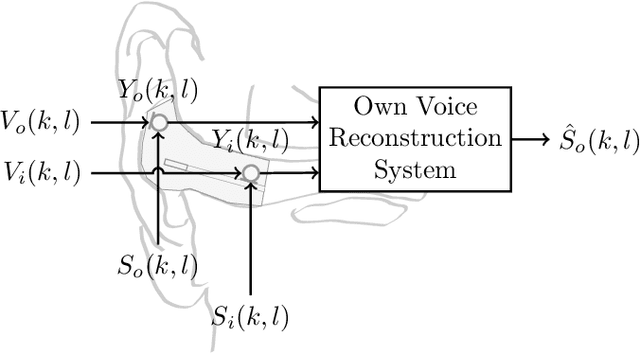
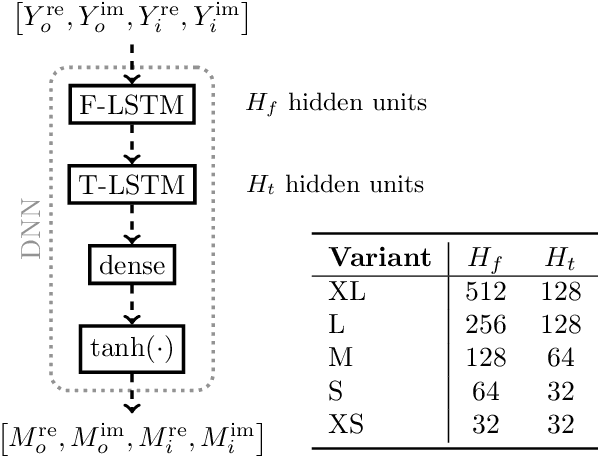
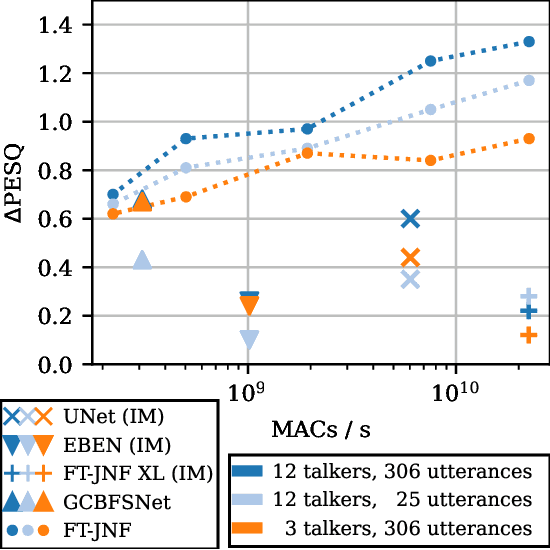
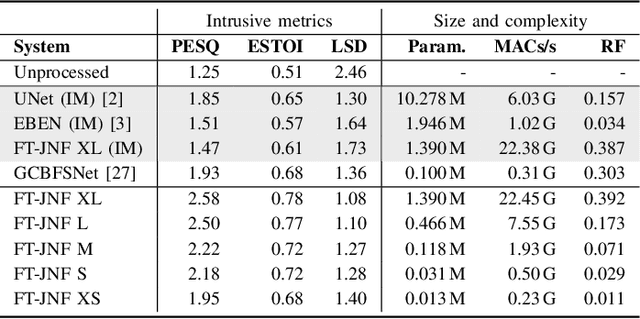
Hearable devices, equipped with one or more microphones, are commonly used for speech communication. Here, we consider the scenario where a hearable is used to capture the user's own voice in a noisy environment. In this scenario, own voice reconstruction (OVR) is essential for enhancing the quality and intelligibility of the recorded noisy own voice signals. In previous work, we developed a deep learning-based OVR system, aiming to reduce the amount of device-specific recordings for training by using data augmentation with phoneme-dependent models of own voice transfer characteristics. Given the limited computational resources available on hearables, in this paper we propose low-complexity variants of an OVR system based on the FT-JNF architecture and investigate the required amount of device-specific recordings for effective data augmentation and fine-tuning. Simulation results show that the proposed OVR system considerably improves speech quality, even under constraints of low complexity and a limited amount of device-specific recordings.