 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Audio-Visual Speech Recognition by Lip-Subword Correlation Based Visual Pre-training and Cross-Modal Fusion Encoder
Paper and Code
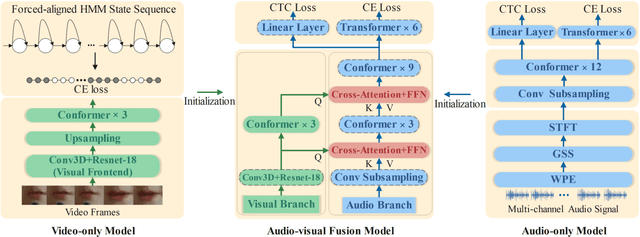
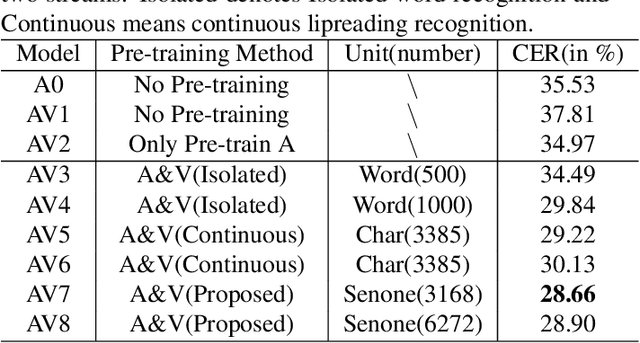
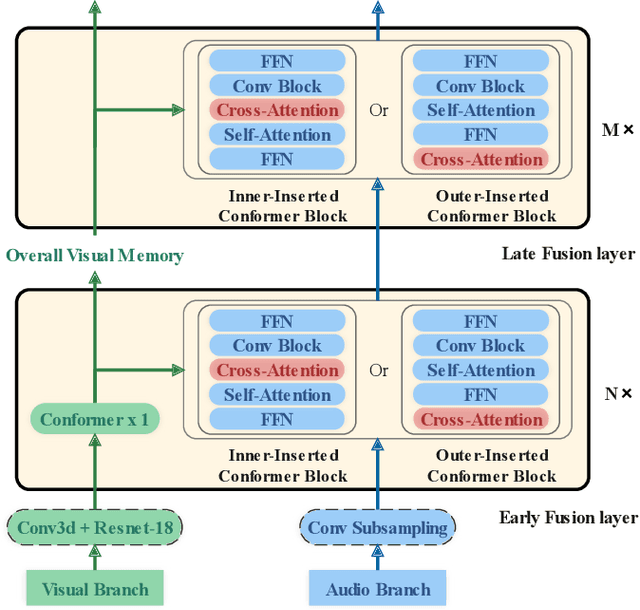
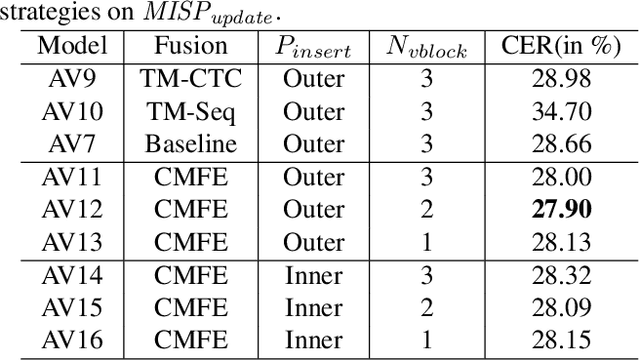
In recent research, slight performance improvement is observed from automatic speech recognition systems to audio-visual speech recognition systems in the end-to-end framework with low-quality videos. Unmatching convergence rates and specialized input representations between audio and visual modalities are considered to cause the problem. In this paper, we propose two novel techniques to improve audio-visual speech recognition (AVSR) under a pre-training and fine-tuning training framework. First, we explore the correlation between lip shapes and syllable-level subword units in Mandarin to establish good frame-level syllable boundaries from lip shapes. This enables accurate alignment of video and audio streams during visual model pre-training and cross-modal fusion. Next, we propose an audio-guided cross-modal fusion encoder (CMFE) neural network to utilize main training parameters for multiple cross-modal attention layers to make full use of modality complementarity. Experiments on the MISP2021-AVSR data set show the effectiveness of the two proposed techniques. Together, using only a relatively small amount of training data, the final system achieves better performances than state-of-the-art systems with more complex front-ends and back-ends.