 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Moral Integrity Corpus: A Benchmark for Ethical Dialogue Systems
Apr 06, 2022



Conversational agents have come increasingly closer to human competence in open-domain dialogue settings; however, such models can reflect insensitive, hurtful, or entirely incoherent viewpoints that erode a user's trust in the moral integrity of the system. Moral deviations are difficult to mitigate because moral judgments are not universal, and there may be multiple competing judgments that apply to a situation simultaneously. In this work, we introduce a new resource, not to authoritatively resolve moral ambiguities, but instead to facilitate systematic understanding of the intuitions, values and moral judgments reflected in the utterances of dialogue systems. The Moral Integrity Corpus, MIC, is such a resource, which captures the moral assumptions of 38k prompt-reply pairs, using 99k distinct Rules of Thumb (RoTs). Each RoT reflects a particular moral conviction that can explain why a chatbot's reply may appear acceptable or problematic. We further organize RoTs with a set of 9 moral and social attributes and benchmark performance for attribute classification. Most importantly, we show that current neural language models can automatically generate new RoTs that reasonably describe previously unseen interactions, but they still struggle with certain scenarios. Our findings suggest that MIC will be a useful resource for understanding and language models' implicit moral assumptions and flexibly benchmarking the integrity of conversational agents. To download the data, see https://github.com/GT-SALT/mic
The CARE Dataset for Affective Response Detection
Jan 28, 2022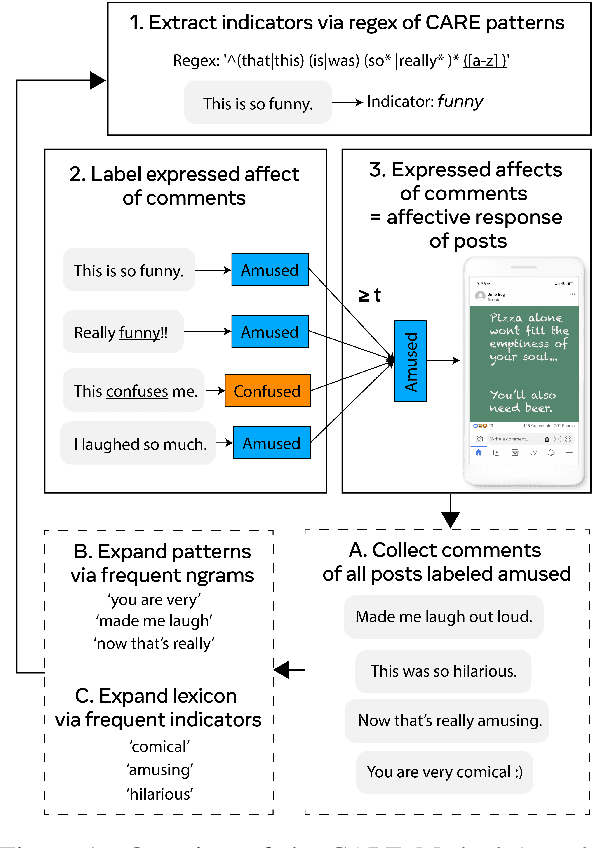

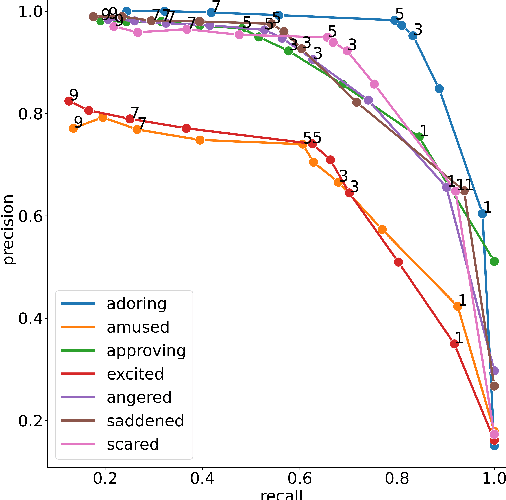

Social media plays an increasing role in our communication with friends and family, and our consumption of information and entertainment. Hence, to design effective ranking functions for posts on social media, it would be useful to predict the affective response to a post (e.g., whether the user is likely to be humored, inspired, angered, informed). Similar to work on emotion recognition (which focuses on the affect of the publisher of the post), the traditional approach to recognizing affective response would involve an expensive investment in human annotation of training data. We introduce CARE$_{db}$, a dataset of 230k social media posts annotated according to 7 affective responses using the Common Affective Response Expression (CARE) method. The CARE method is a means of leveraging the signal that is present in comments that are posted in response to a post, providing high-precision evidence about the affective response of the readers to the post without human annotation. Unlike human annotation, the annotation process we describe here can be iterated upon to expand the coverage of the method, particularly for new affective responses. We present experiments that demonstrate that the CARE annotations compare favorably with crowd-sourced annotations. Finally, we use CARE$_{db}$ to train competitive BERT-based models for predicting affective response as well as emotion detection, demonstrating the utility of the dataset for related tasks.
Detecting Inspiring Content on Social Media
Sep 06, 2021
Inspiration moves a person to see new possibilities and transforms the way they perceive their own potential. Inspiration has received little attention in psychology, and has not been researched before in the NLP community. To the best of our knowledge, this work is the first to study inspiration through machine learning methods. We aim to automatically detect inspiring content from social media data. To this end, we analyze social media posts to tease out what makes a post inspiring and what topics are inspiring. We release a dataset of 5,800 inspiring and 5,800 non-inspiring English-language public post unique ids collected from a dump of Reddit public posts made available by a third party and use linguistic heuristics to automatically detect which social media English-language posts are inspiring.