 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeO-Researcher: An Open Ended Deep Research Model via Multi-Agent Distillation and Agentic RL
Jan 07, 2026The performance gap between closed-source and open-source large language models (LLMs) is largely attributed to disparities in access to high-quality training data. To bridge this gap, we introduce a novel framework for the automated synthesis of sophisticated, research-grade instructional data. Our approach centers on a multi-agent workflow where collaborative AI agents simulate complex tool-integrated reasoning to generate diverse and high-fidelity data end-to-end. Leveraging this synthesized data, we develop a two-stage training strategy that integrates supervised fine-tuning with a novel reinforcement learning method, designed to maximize model alignment and capability. Extensive experiments demonstrate that our framework empowers open-source models across multiple scales, enabling them to achieve new state-of-the-art performance on the major deep research benchmark. This work provides a scalable and effective pathway for advancing open-source LLMs without relying on proprietary data or models.
Judging with Personality and Confidence: A Study on Personality-Conditioned LLM Relevance Assessment
Jan 05, 2026Recent studies have shown that prompting can enable large language models (LLMs) to simulate specific personality traits and produce behaviors that align with those traits. However, there is limited understanding of how these simulated personalities influence critical web search decisions, specifically relevance assessment. Moreover, few studies have examined how simulated personalities impact confidence calibration, specifically the tendencies toward overconfidence or underconfidence. This gap exists even though psychological literature suggests these biases are trait-specific, often linking high extraversion to overconfidence and high neuroticism to underconfidence. To address this gap, we conducted a comprehensive study evaluating multiple LLMs, including commercial models and open-source models, prompted to simulate Big Five personality traits. We tested these models across three test collections (TREC DL 2019, TREC DL 2020, and LLMJudge), collecting two key outputs for each query-document pair: a relevance judgment and a self-reported confidence score. The findings show that personalities such as low agreeableness consistently align more closely with human labels than the unprompted condition. Additionally, low conscientiousness performs well in balancing the suppression of both overconfidence and underconfidence. We also observe that relevance scores and confidence distributions vary systematically across different personalities. Based on the above findings, we incorporate personality-conditioned scores and confidence as features in a random forest classifier. This approach achieves performance that surpasses the best single-personality condition on a new dataset (TREC DL 2021), even with limited training data. These findings highlight that personality-derived confidence offers a complementary predictive signal, paving the way for more reliable and human-aligned LLM evaluators.
O-Mem: Omni Memory System for Personalized, Long Horizon, Self-Evolving Agents
Nov 18, 2025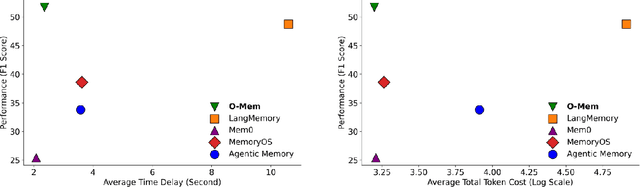
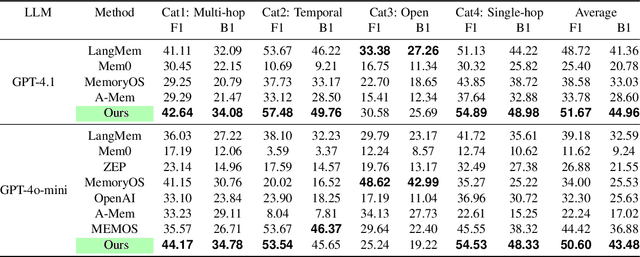
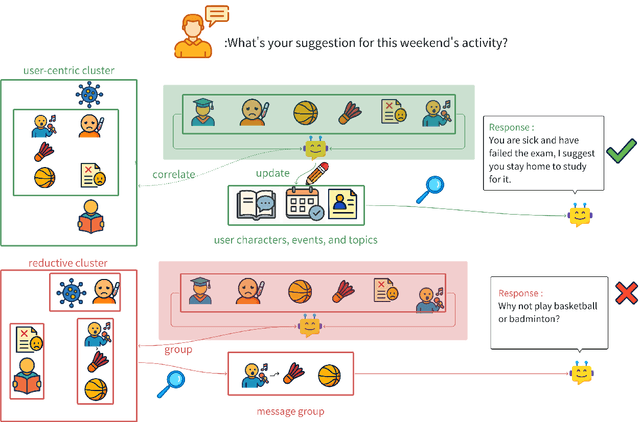

Recent advancements in LLM-powered agents have demonstrated significant potential in generating human-like responses; however, they continue to face challenges in maintaining long-term interactions within complex environments, primarily due to limitations in contextual consistency and dynamic personalization. Existing memory systems often depend on semantic grouping prior to retrieval, which can overlook semantically irrelevant yet critical user information and introduce retrieval noise. In this report, we propose the initial design of O-Mem, a novel memory framework based on active user profiling that dynamically extracts and updates user characteristics and event records from their proactive interactions with agents. O-Mem supports hierarchical retrieval of persona attributes and topic-related context, enabling more adaptive and coherent personalized responses. O-Mem achieves 51.67% on the public LoCoMo benchmark, a nearly 3% improvement upon LangMem,the previous state-of-the-art, and it achieves 62.99% on PERSONAMEM, a 3.5% improvement upon A-Mem,the previous state-of-the-art. O-Mem also boosts token and interaction response time efficiency compared to previous memory frameworks. Our work opens up promising directions for developing efficient and human-like personalized AI assistants in the future.
"It Felt Like Having a Second Mind": Investigating Human-AI Co-creativity in Prewriting with Large Language Models
Jul 20, 2023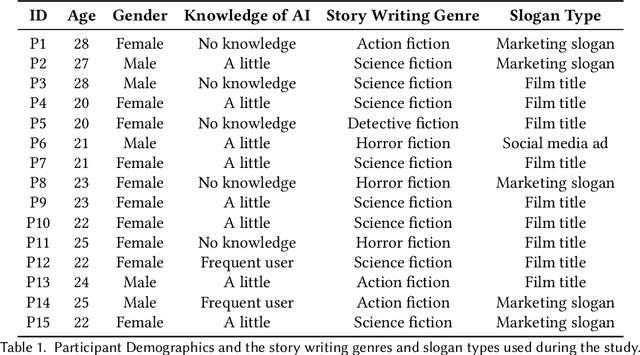
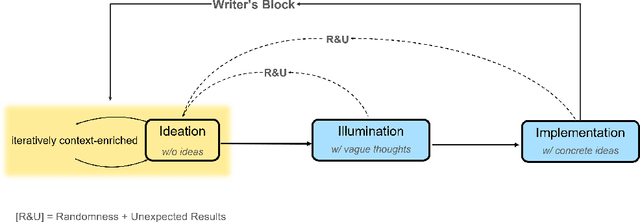


Prewriting is the process of discovering and developing ideas before a first draft, which requires divergent thinking and often implies unstructured strategies such as diagramming, outlining, free-writing, etc. Although large language models (LLMs) have been demonstrated to be useful for a variety of tasks including creative writing, little is known about how users would collaborate with LLMs to support prewriting. The preferred collaborative role and initiative of LLMs during such a creativity process is also unclear. To investigate human-LLM collaboration patterns and dynamics during prewriting, we conducted a three-session qualitative study with 15 participants in two creative tasks: story writing and slogan writing. The findings indicated that during collaborative prewriting, there appears to be a three-stage iterative Human-AI Co-creativity process that includes Ideation, Illumination, and Implementation stages. This collaborative process champions the human in a dominant role, in addition to mixed and shifting levels of initiative that exist between humans and LLMs. This research also reports on collaboration breakdowns that occur during this process, user perceptions of using existing LLMs during Human-AI Co-creativity, and discusses design implications to support this co-creativity process.