 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePersonaDual: Balancing Personalization and Objectivity via Adaptive Reasoning
Jan 13, 2026As users increasingly expect LLMs to align with their preferences, personalized information becomes valuable. However, personalized information can be a double-edged sword: it can improve interaction but may compromise objectivity and factual correctness, especially when it is misaligned with the question. To alleviate this problem, we propose PersonaDual, a framework that supports both general-purpose objective reasoning and personalized reasoning in a single model, and adaptively switches modes based on context. PersonaDual is first trained with SFT to learn two reasoning patterns, and then further optimized via reinforcement learning with our proposed DualGRPO to improve mode selection. Experiments on objective and personalized benchmarks show that PersonaDual preserves the benefits of personalization while reducing interference, achieving near interference-free performance and better leveraging helpful personalized signals to improve objective problem-solving.
O-Researcher: An Open Ended Deep Research Model via Multi-Agent Distillation and Agentic RL
Jan 07, 2026The performance gap between closed-source and open-source large language models (LLMs) is largely attributed to disparities in access to high-quality training data. To bridge this gap, we introduce a novel framework for the automated synthesis of sophisticated, research-grade instructional data. Our approach centers on a multi-agent workflow where collaborative AI agents simulate complex tool-integrated reasoning to generate diverse and high-fidelity data end-to-end. Leveraging this synthesized data, we develop a two-stage training strategy that integrates supervised fine-tuning with a novel reinforcement learning method, designed to maximize model alignment and capability. Extensive experiments demonstrate that our framework empowers open-source models across multiple scales, enabling them to achieve new state-of-the-art performance on the major deep research benchmark. This work provides a scalable and effective pathway for advancing open-source LLMs without relying on proprietary data or models.
MiniMax-01: Scaling Foundation Models with Lightning Attention
Jan 14, 2025We introduce MiniMax-01 series, including MiniMax-Text-01 and MiniMax-VL-01, which are comparable to top-tier models while offering superior capabilities in processing longer contexts. The core lies in lightning attention and its efficient scaling. To maximize computational capacity, we integrate it with Mixture of Experts (MoE), creating a model with 32 experts and 456 billion total parameters, of which 45.9 billion are activated for each token. We develop an optimized parallel strategy and highly efficient computation-communication overlap techniques for MoE and lightning attention. This approach enables us to conduct efficient training and inference on models with hundreds of billions of parameters across contexts spanning millions of tokens. The context window of MiniMax-Text-01 can reach up to 1 million tokens during training and extrapolate to 4 million tokens during inference at an affordable cost. Our vision-language model, MiniMax-VL-01 is built through continued training with 512 billion vision-language tokens. Experiments on both standard and in-house benchmarks show that our models match the performance of state-of-the-art models like GPT-4o and Claude-3.5-Sonnet while offering 20-32 times longer context window. We publicly release MiniMax-01 at https://github.com/MiniMax-AI.
Low Entropy Communication in Multi-Agent Reinforcement Learning
Feb 10, 2023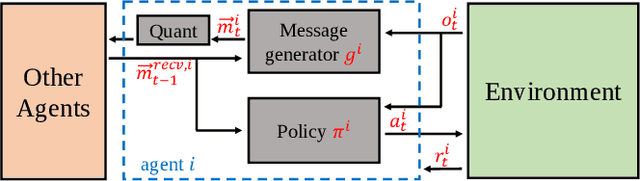
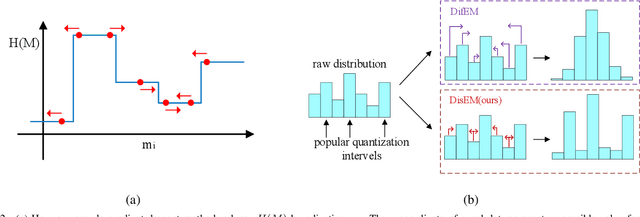
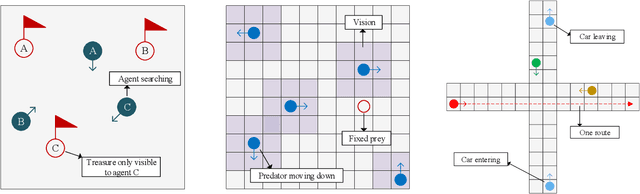
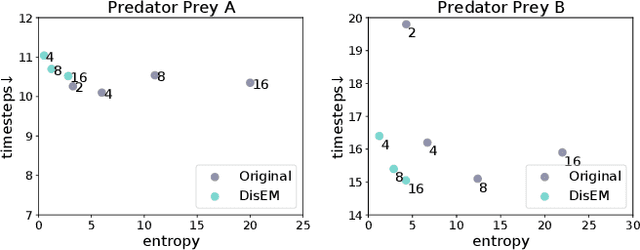
Communication in multi-agent reinforcement learning has been drawing attention recently for its significant role in cooperation. However, multi-agent systems may suffer from limitations on communication resources and thus need efficient communication techniques in real-world scenarios. According to the Shannon-Hartley theorem, messages to be transmitted reliably in worse channels require lower entropy. Therefore, we aim to reduce message entropy in multi-agent communication. A fundamental challenge is that the gradients of entropy are either 0 or infinity, disabling gradient-based methods. To handle it, we propose a pseudo gradient descent scheme, which reduces entropy by adjusting the distributions of messages wisely. We conduct experiments on two base communication frameworks with six environment settings and find that our scheme can reduce message entropy by up to 90% with nearly no loss of cooperation performance.