 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Communicative Multi-Agent Reinforcement Learning with Active Defense
Dec 16, 2023



Communication in multi-agent reinforcement learning (MARL) has been proven to effectively promote cooperation among agents recently. Since communication in real-world scenarios is vulnerable to noises and adversarial attacks, it is crucial to develop robust communicative MARL technique. However, existing research in this domain has predominantly focused on passive defense strategies, where agents receive all messages equally, making it hard to balance performance and robustness. We propose an active defense strategy, where agents automatically reduce the impact of potentially harmful messages on the final decision. There are two challenges to implement this strategy, that are defining unreliable messages and adjusting the unreliable messages' impact on the final decision properly. To address them, we design an Active Defense Multi-Agent Communication framework (ADMAC), which estimates the reliability of received messages and adjusts their impact on the final decision accordingly with the help of a decomposable decision structure. The superiority of ADMAC over existing methods is validated by experiments in three communication-critical tasks under four types of attacks.
Promoting Cooperation in Multi-Agent Reinforcement Learning via Mutual Help
Feb 18, 2023Multi-agent reinforcement learning (MARL) has achieved great progress in cooperative tasks in recent years. However, in the local reward scheme, where only local rewards for each agent are given without global rewards shared by all the agents, traditional MARL algorithms lack sufficient consideration of agents' mutual influence. In cooperative tasks, agents' mutual influence is especially important since agents are supposed to coordinate to achieve better performance. In this paper, we propose a novel algorithm Mutual-Help-based MARL (MH-MARL) to instruct agents to help each other in order to promote cooperation. MH-MARL utilizes an expected action module to generate expected other agents' actions for each particular agent. Then, the expected actions are delivered to other agents for selective imitation during training. Experimental results show that MH-MARL improves the performance of MARL both in success rate and cumulative reward.
Low Entropy Communication in Multi-Agent Reinforcement Learning
Feb 10, 2023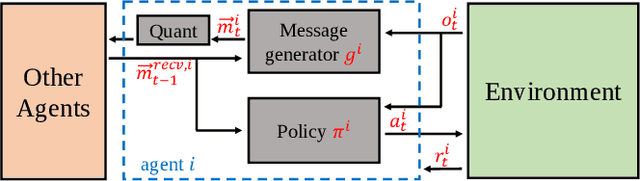
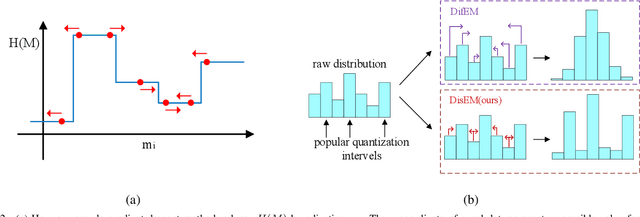
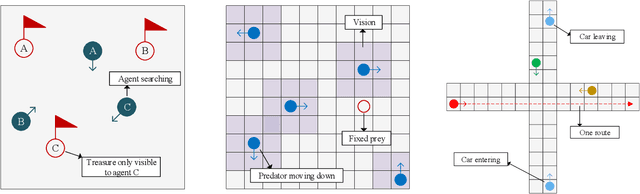
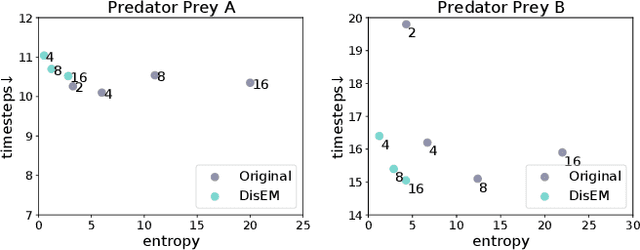
Communication in multi-agent reinforcement learning has been drawing attention recently for its significant role in cooperation. However, multi-agent systems may suffer from limitations on communication resources and thus need efficient communication techniques in real-world scenarios. According to the Shannon-Hartley theorem, messages to be transmitted reliably in worse channels require lower entropy. Therefore, we aim to reduce message entropy in multi-agent communication. A fundamental challenge is that the gradients of entropy are either 0 or infinity, disabling gradient-based methods. To handle it, we propose a pseudo gradient descent scheme, which reduces entropy by adjusting the distributions of messages wisely. We conduct experiments on two base communication frameworks with six environment settings and find that our scheme can reduce message entropy by up to 90% with nearly no loss of cooperation performance.
Sample-Efficient Multi-Agent Reinforcement Learning with Demonstrations for Flocking Control
Sep 17, 2022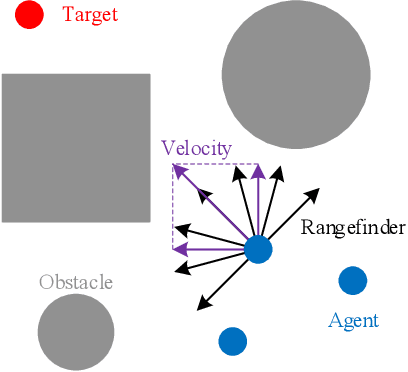
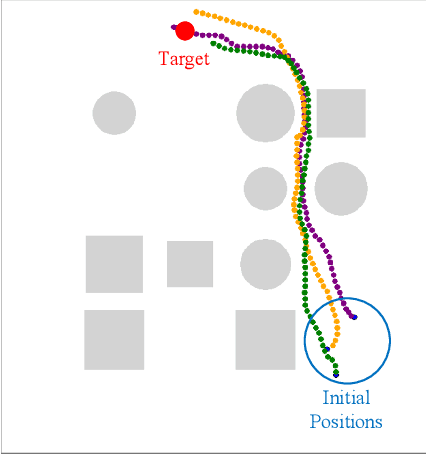
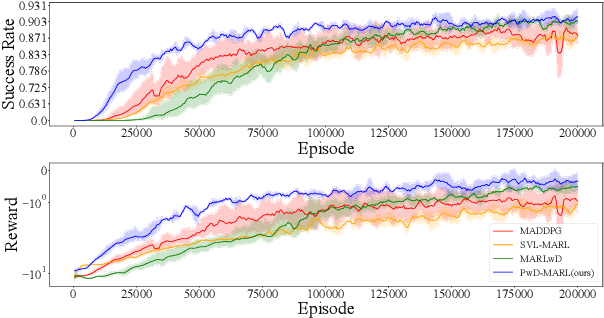
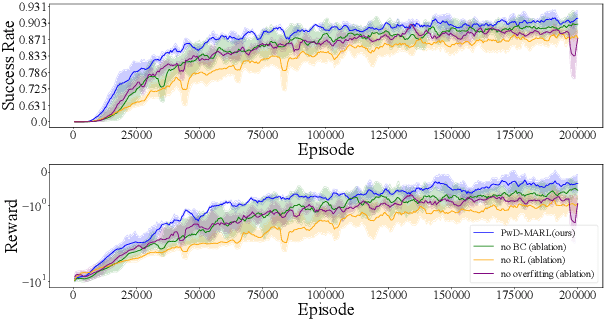
Flocking control is a significant problem in multi-agent systems such as multi-agent unmanned aerial vehicles and multi-agent autonomous underwater vehicles, which enhances the cooperativity and safety of agents. In contrast to traditional methods, multi-agent reinforcement learning (MARL) solves the problem of flocking control more flexibly. However, methods based on MARL suffer from sample inefficiency, since they require a huge number of experiences to be collected from interactions between agents and the environment. We propose a novel method Pretraining with Demonstrations for MARL (PwD-MARL), which can utilize non-expert demonstrations collected in advance with traditional methods to pretrain agents. During the process of pretraining, agents learn policies from demonstrations by MARL and behavior cloning simultaneously, and are prevented from overfitting demonstrations. By pretraining with non-expert demonstrations, PwD-MARL improves sample efficiency in the process of online MARL with a warm start. Experiments show that PwD-MARL improves sample efficiency and policy performance in the problem of flocking control, even with bad or few demonstrations.
Sub-optimal Policy Aided Multi-Agent Reinforcement Learning for Flocking Control
Sep 17, 2022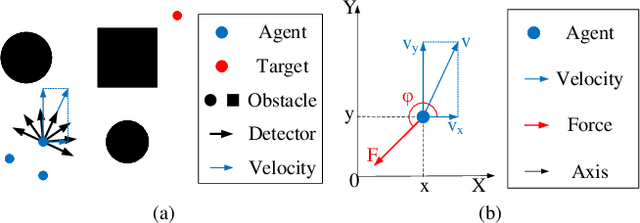
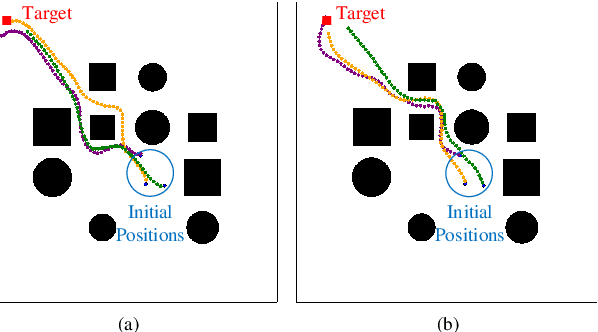
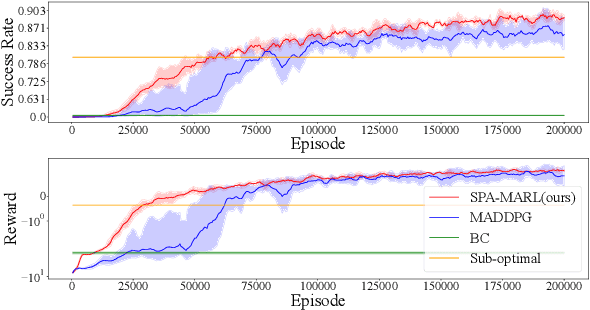
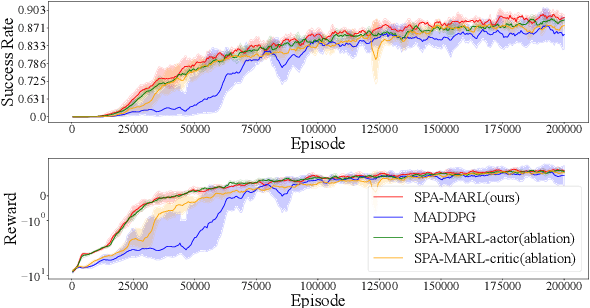
Flocking control is a challenging problem, where multiple agents, such as drones or vehicles, need to reach a target position while maintaining the flock and avoiding collisions with obstacles and collisions among agents in the environment. Multi-agent reinforcement learning has achieved promising performance in flocking control. However, methods based on traditional reinforcement learning require a considerable number of interactions between agents and the environment. This paper proposes a sub-optimal policy aided multi-agent reinforcement learning algorithm (SPA-MARL) to boost sample efficiency. SPA-MARL directly leverages a prior policy that can be manually designed or solved with a non-learning method to aid agents in learning, where the performance of the policy can be sub-optimal. SPA-MARL recognizes the difference in performance between the sub-optimal policy and itself, and then imitates the sub-optimal policy if the sub-optimal policy is better. We leverage SPA-MARL to solve the flocking control problem. A traditional control method based on artificial potential fields is used to generate a sub-optimal policy. Experiments demonstrate that SPA-MARL can speed up the training process and outperform both the MARL baseline and the used sub-optimal policy.