 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSample-Efficient Multi-Agent Reinforcement Learning with Demonstrations for Flocking Control
Paper and Code
Sep 17, 2022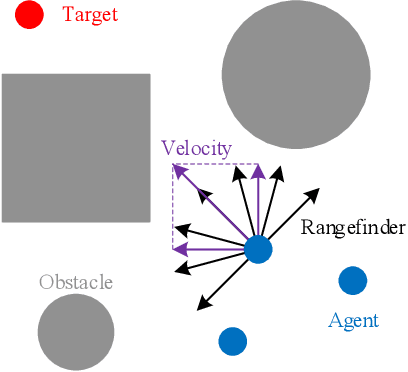
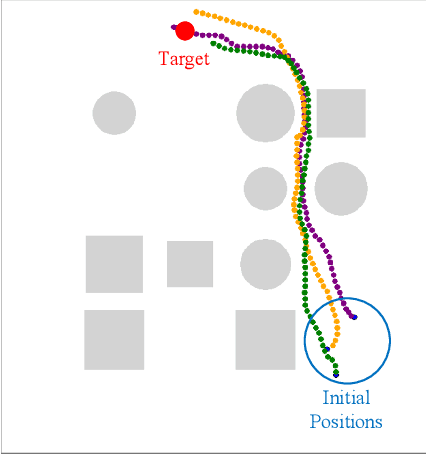
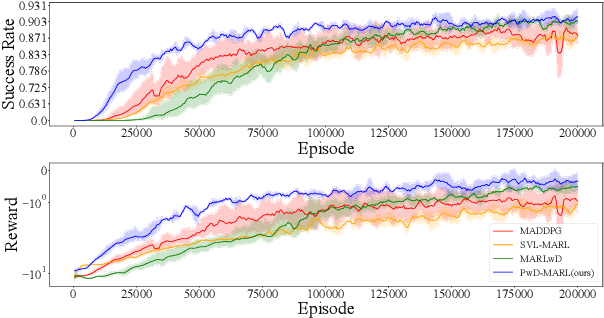
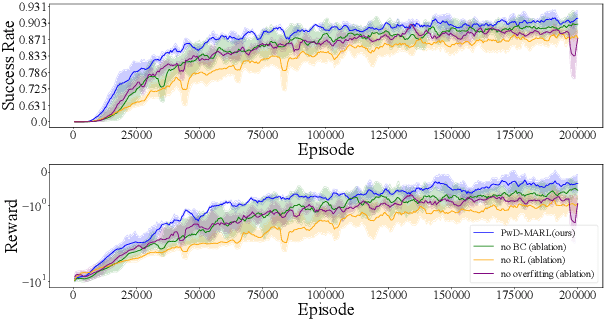
Flocking control is a significant problem in multi-agent systems such as multi-agent unmanned aerial vehicles and multi-agent autonomous underwater vehicles, which enhances the cooperativity and safety of agents. In contrast to traditional methods, multi-agent reinforcement learning (MARL) solves the problem of flocking control more flexibly. However, methods based on MARL suffer from sample inefficiency, since they require a huge number of experiences to be collected from interactions between agents and the environment. We propose a novel method Pretraining with Demonstrations for MARL (PwD-MARL), which can utilize non-expert demonstrations collected in advance with traditional methods to pretrain agents. During the process of pretraining, agents learn policies from demonstrations by MARL and behavior cloning simultaneously, and are prevented from overfitting demonstrations. By pretraining with non-expert demonstrations, PwD-MARL improves sample efficiency in the process of online MARL with a warm start. Experiments show that PwD-MARL improves sample efficiency and policy performance in the problem of flocking control, even with bad or few demonstrations.