 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Reinforcement Learning for Zero-Shot Coordination in Evolving Games
Nov 18, 2025Zero-shot coordination(ZSC), a key challenge in multi-agent game theory, has become a hot topic in reinforcement learning (RL) research recently, especially in complex evolving games. It focuses on the generalization ability of agents, requiring them to coordinate well with collaborators from a diverse, potentially evolving, pool of partners that are not seen before without any fine-tuning. Population-based training, which approximates such an evolving partner pool, has been proven to provide good zero-shot coordination performance; nevertheless, existing methods are limited by computational resources, mainly focusing on optimizing diversity in small populations while neglecting the potential performance gains from scaling population size. To address this issue, this paper proposes the Scalable Population Training (ScaPT), an efficient RL training framework comprising two key components: a meta-agent that efficiently realizes a population by selectively sharing parameters across agents, and a mutual information regularizer that guarantees population diversity. To empirically validate the effectiveness of ScaPT, this paper evaluates it along with representational frameworks in Hanabi cooperative game and confirms its superiority.
Robust Communicative Multi-Agent Reinforcement Learning with Active Defense
Dec 16, 2023



Communication in multi-agent reinforcement learning (MARL) has been proven to effectively promote cooperation among agents recently. Since communication in real-world scenarios is vulnerable to noises and adversarial attacks, it is crucial to develop robust communicative MARL technique. However, existing research in this domain has predominantly focused on passive defense strategies, where agents receive all messages equally, making it hard to balance performance and robustness. We propose an active defense strategy, where agents automatically reduce the impact of potentially harmful messages on the final decision. There are two challenges to implement this strategy, that are defining unreliable messages and adjusting the unreliable messages' impact on the final decision properly. To address them, we design an Active Defense Multi-Agent Communication framework (ADMAC), which estimates the reliability of received messages and adjusts their impact on the final decision accordingly with the help of a decomposable decision structure. The superiority of ADMAC over existing methods is validated by experiments in three communication-critical tasks under four types of attacks.
Promoting Cooperation in Multi-Agent Reinforcement Learning via Mutual Help
Feb 18, 2023Multi-agent reinforcement learning (MARL) has achieved great progress in cooperative tasks in recent years. However, in the local reward scheme, where only local rewards for each agent are given without global rewards shared by all the agents, traditional MARL algorithms lack sufficient consideration of agents' mutual influence. In cooperative tasks, agents' mutual influence is especially important since agents are supposed to coordinate to achieve better performance. In this paper, we propose a novel algorithm Mutual-Help-based MARL (MH-MARL) to instruct agents to help each other in order to promote cooperation. MH-MARL utilizes an expected action module to generate expected other agents' actions for each particular agent. Then, the expected actions are delivered to other agents for selective imitation during training. Experimental results show that MH-MARL improves the performance of MARL both in success rate and cumulative reward.
Low Entropy Communication in Multi-Agent Reinforcement Learning
Feb 10, 2023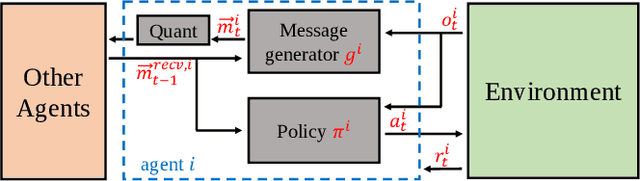
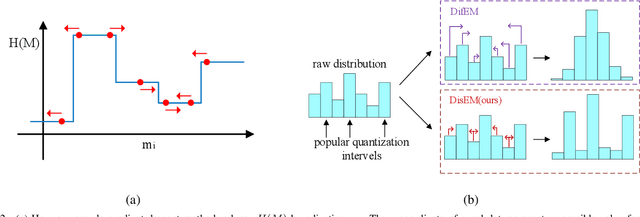
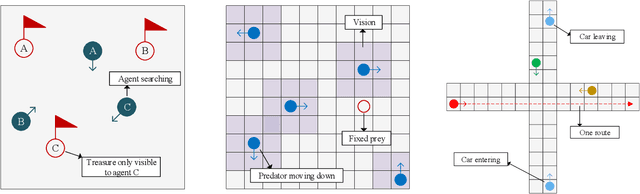
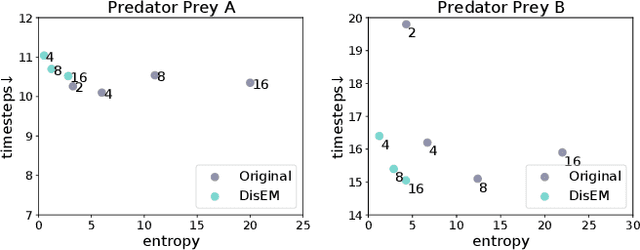
Communication in multi-agent reinforcement learning has been drawing attention recently for its significant role in cooperation. However, multi-agent systems may suffer from limitations on communication resources and thus need efficient communication techniques in real-world scenarios. According to the Shannon-Hartley theorem, messages to be transmitted reliably in worse channels require lower entropy. Therefore, we aim to reduce message entropy in multi-agent communication. A fundamental challenge is that the gradients of entropy are either 0 or infinity, disabling gradient-based methods. To handle it, we propose a pseudo gradient descent scheme, which reduces entropy by adjusting the distributions of messages wisely. We conduct experiments on two base communication frameworks with six environment settings and find that our scheme can reduce message entropy by up to 90% with nearly no loss of cooperation performance.
Robust Reinforcement Learning under model misspecification
Mar 29, 2021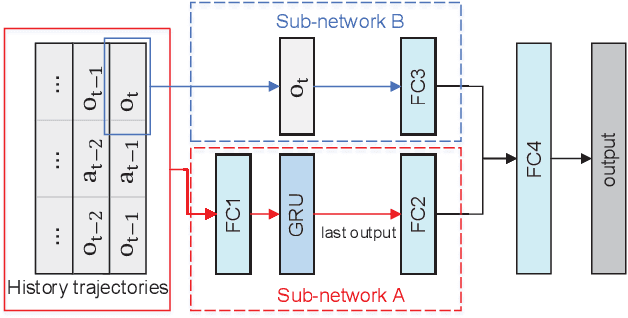
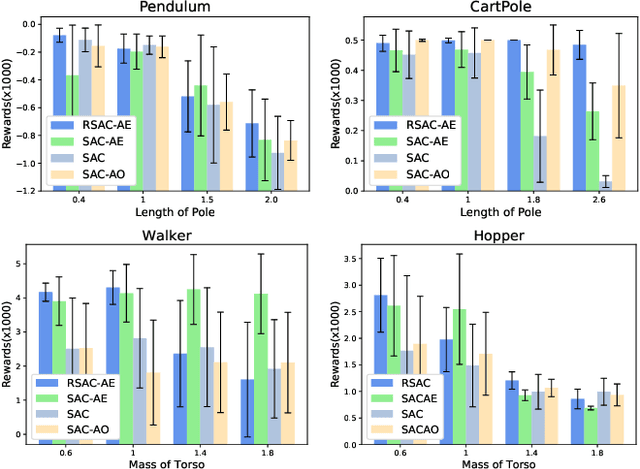
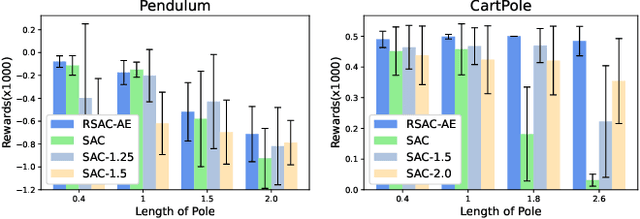
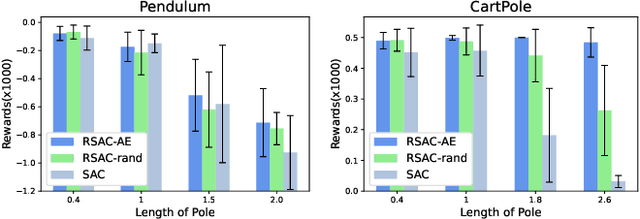
Reinforcement learning has achieved remarkable performance in a wide range of tasks these days. Nevertheless, some unsolved problems limit its applications in real-world control. One of them is model misspecification, a situation where an agent is trained and deployed in environments with different transition dynamics. We propose an novel framework that utilize history trajectory and Partial Observable Markov Decision Process Modeling to deal with this dilemma. Additionally, we put forward an efficient adversarial attack method to assist robust training. Our experiments in four gym domains validate the effectiveness of our framework.