 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSub-optimal Policy Aided Multi-Agent Reinforcement Learning for Flocking Control
Paper and Code
Sep 17, 2022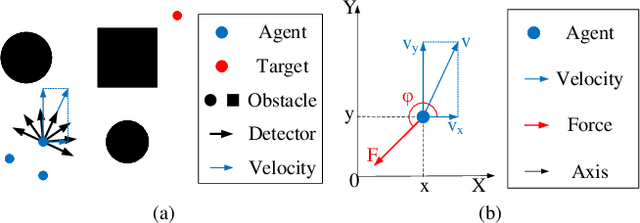
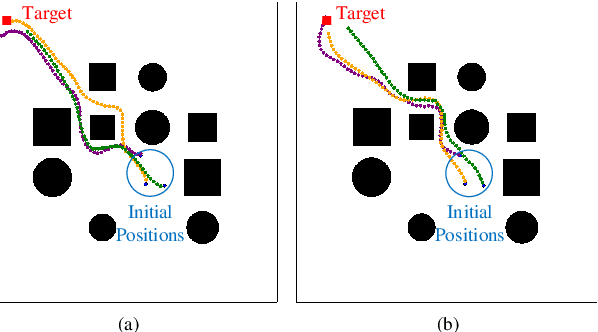
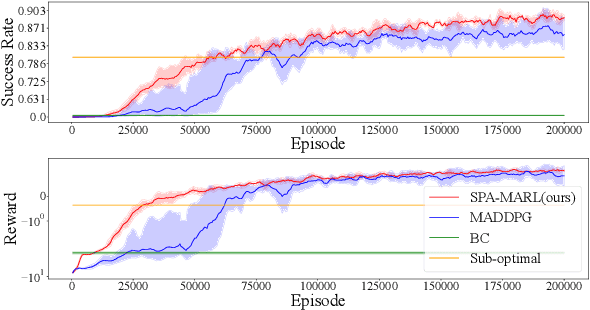
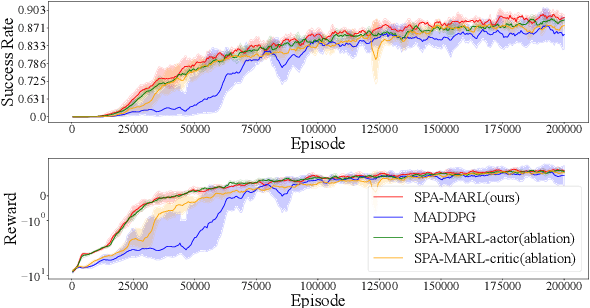
Flocking control is a challenging problem, where multiple agents, such as drones or vehicles, need to reach a target position while maintaining the flock and avoiding collisions with obstacles and collisions among agents in the environment. Multi-agent reinforcement learning has achieved promising performance in flocking control. However, methods based on traditional reinforcement learning require a considerable number of interactions between agents and the environment. This paper proposes a sub-optimal policy aided multi-agent reinforcement learning algorithm (SPA-MARL) to boost sample efficiency. SPA-MARL directly leverages a prior policy that can be manually designed or solved with a non-learning method to aid agents in learning, where the performance of the policy can be sub-optimal. SPA-MARL recognizes the difference in performance between the sub-optimal policy and itself, and then imitates the sub-optimal policy if the sub-optimal policy is better. We leverage SPA-MARL to solve the flocking control problem. A traditional control method based on artificial potential fields is used to generate a sub-optimal policy. Experiments demonstrate that SPA-MARL can speed up the training process and outperform both the MARL baseline and the used sub-optimal policy.