 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemanticBoost: Elevating Motion Generation with Augmented Textual Cues
Paper and Code


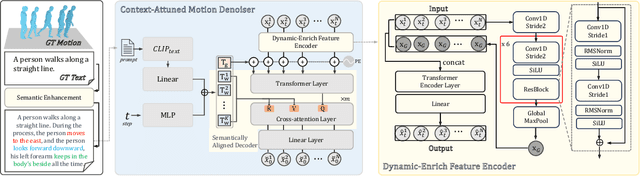

Current techniques face difficulties in generating motions from intricate semantic descriptions, primarily due to insufficient semantic annotations in datasets and weak contextual understanding. To address these issues, we present SemanticBoost, a novel framework that tackles both challenges simultaneously. Our framework comprises a Semantic Enhancement module and a Context-Attuned Motion Denoiser (CAMD). The Semantic Enhancement module extracts supplementary semantics from motion data, enriching the dataset's textual description and ensuring precise alignment between text and motion data without depending on large language models. On the other hand, the CAMD approach provides an all-encompassing solution for generating high-quality, semantically consistent motion sequences by effectively capturing context information and aligning the generated motion with the given textual descriptions. Distinct from existing methods, our approach can synthesize accurate orientational movements, combined motions based on specific body part descriptions, and motions generated from complex, extended sentences. Our experimental results demonstrate that SemanticBoost, as a diffusion-based method, outperforms auto-regressive-based techniques, achieving cutting-edge performance on the Humanml3D dataset while maintaining realistic and smooth motion generation quality.