 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOMPOSE: Composing Future Theorems from Citations and Formal Structure
May 28, 2026A plausible future mathematical claim must satisfy two constraints: it should follow the direction of prior work and respect the formal dependencies that constrain what can validly follow. Existing approaches typically model only one of these sources, producing claims that are either weakly grounded or insufficiently motivated. We introduce grounded future mathematical generation, where the goal is to generate a plausible future theorem-like claim for an anchor paper using two complementary sources of context: its scientific citation graph and aligned formal theorem dependency graph. To address this setting, we propose COMPOSE, a dual-graph framework that conditions a language model on both scientific citation context and formal theorem structure. To support this setting, we construct a dataset of 108K paired scientific-formal graph examples from arXiv and Mathlib, together with a benchmark of 47K future papers from 2024--2025. Experiments show that COMPOSE outperforms strong baselines on retrieval to real future papers and achieves the best overall performance under LLM-judge evaluation, producing more grounded and mathematically richer outputs. These results show that future mathematical generation benefits from combining scientific context with formal structure. Project page is available at https://david-busbib.github.io/COMPOSE-page/.
Neural Global Optimization via Iterative Refinement from Noisy Samples
Apr 04, 2026Global optimization of black-box functions from noisy samples is a fundamental challenge in machine learning and scientific computing. Traditional methods such as Bayesian Optimization often converge to local minima on multi-modal functions, while gradient-free methods require many function evaluations. We present a novel neural approach that learns to find global minima through iterative refinement. Our model takes noisy function samples and their fitted spline representation as input, then iteratively refines an initial guess toward the true global minimum. Trained on randomly generated functions with ground truth global minima obtained via exhaustive search, our method achieves a mean error of 8.05 percent on challenging multi-modal test functions, compared to 36.24 percent for the spline initialization, a 28.18 percent improvement. The model successfully finds global minima in 72 percent of test cases with error below 10 percent, demonstrating learned optimization principles rather than mere curve fitting. Our architecture combines encoding of multiple modalities including function values, derivatives, and spline coefficients with iterative position updates, enabling robust global optimization without requiring derivative information or multiple restarts.
CanonNet: Canonical Ordering and Curvature Learning for Point Cloud Analysis
Apr 03, 2025
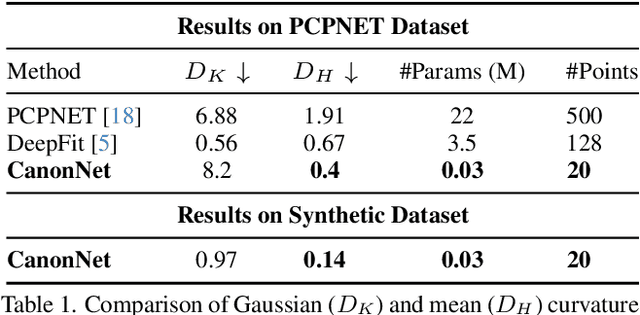


Point cloud processing poses two fundamental challenges: establishing consistent point ordering and effectively learning fine-grained geometric features. Current architectures rely on complex operations that limit expressivity while struggling to capture detailed surface geometry. We present CanonNet, a lightweight neural network composed of two complementary components: (1) a preprocessing pipeline that creates a canonical point ordering and orientation, and (2) a geometric learning framework where networks learn from synthetic surfaces with precise curvature values. This modular approach eliminates the need for complex transformation-invariant architectures while effectively capturing local geometric properties. Our experiments demonstrate state-of-the-art performance in curvature estimation and competitive results in geometric descriptor tasks with significantly fewer parameters (\textbf{100X}) than comparable methods. CanonNet's efficiency makes it particularly suitable for real-world applications where computational resources are limited, demonstrating that mathematical preprocessing can effectively complement neural architectures for point cloud analysis. The code for the project is publicly available \hyperlink{https://benjyfri.github.io/CanonNet/}{https://benjyfri.github.io/CanonNet/}.
The Fibonacci Network: A Simple Alternative for Positional Encoding
Nov 07, 2024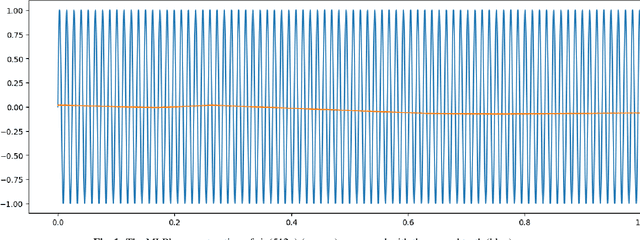

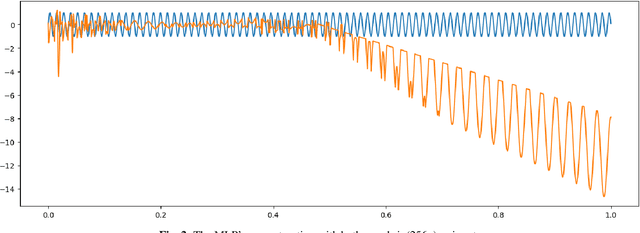
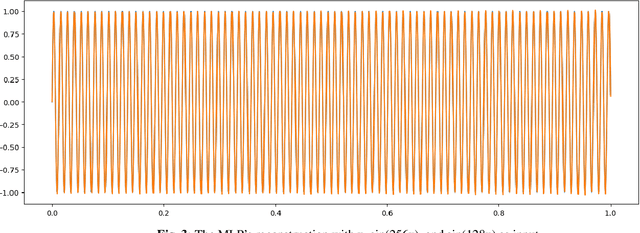
Coordinate-based Multi-Layer Perceptrons (MLPs) are known to have difficulty reconstructing high frequencies of the training data. A common solution to this problem is Positional Encoding (PE), which has become quite popular. However, PE has drawbacks. It has high-frequency artifacts and adds another hyper-hyperparameter, just like batch normalization and dropout do. We believe that under certain circumstances PE is not necessary, and a smarter construction of the network architecture together with a smart training method is sufficient to achieve similar results. In this paper, we show that very simple MLPs can quite easily output a frequency when given input of the half-frequency and quarter-frequency. Using this, we design a network architecture in blocks, where the input to each block is the output of the two previous blocks along with the original input. We call this a {\it Fibonacci Network}. By training each block on the corresponding frequencies of the signal, we show that Fibonacci Networks can reconstruct arbitrarily high frequencies.
Camera Calibration and Stereo via a Single Image of a Spherical Mirror
Sep 24, 2024



This paper presents a novel technique for camera calibration using a single view that incorporates a spherical mirror. Leveraging the distinct characteristics of the sphere's contour visible in the image and its reflections, we showcase the effectiveness of our method in achieving precise calibration. Furthermore, the reflection from the mirrored surface provides additional information about the surrounding scene beyond the image frame. Our method paves the way for the development of simple catadioptric stereo systems. We explore the challenges and opportunities associated with employing a single mirrored sphere, highlighting the potential applications of this setup in practical scenarios. The paper delves into the intricacies of the geometry and calibration procedures involved in catadioptric stereo utilizing a spherical mirror. Experimental results, encompassing both synthetic and real-world data, are presented to illustrate the feasibility and accuracy of our approach.
Beyond the Benchmark: Detecting Diverse Anomalies in Videos
Oct 03, 2023



Video Anomaly Detection (VAD) plays a crucial role in modern surveillance systems, aiming to identify various anomalies in real-world situations. However, current benchmark datasets predominantly emphasize simple, single-frame anomalies such as novel object detection. This narrow focus restricts the advancement of VAD models. In this research, we advocate for an expansion of VAD investigations to encompass intricate anomalies that extend beyond conventional benchmark boundaries. To facilitate this, we introduce two datasets, HMDB-AD and HMDB-Violence, to challenge models with diverse action-based anomalies. These datasets are derived from the HMDB51 action recognition dataset. We further present Multi-Frame Anomaly Detection (MFAD), a novel method built upon the AI-VAD framework. AI-VAD utilizes single-frame features such as pose estimation and deep image encoding, and two-frame features such as object velocity. They then apply a density estimation algorithm to compute anomaly scores. To address complex multi-frame anomalies, we add a deep video encoding features capturing long-range temporal dependencies, and logistic regression to enhance final score calculation. Experimental results confirm our assumptions, highlighting existing models limitations with new anomaly types. MFAD excels in both simple and complex anomaly detection scenarios.
Robust affine feature matching via quadratic assignment on Grassmannians
Mar 07, 2023



GraNNI (Grassmannians for Nearest Neighbours Identification) a new algorithm to solve the problem of affine registration is proposed. The algorithm is based on the Grassmannian of $k$--dimensional planes in $\mathbb{R}^n$ and minimizing the Frobenius norm between the two elements of the Grassmannian. The Quadratic Assignment Problem (QAP) is used to find the matching. The results of the experiments show that the algorithm is more robust to noise and point discrepancy in point clouds than previous approaches.
An approach to robust ICP initialization
Dec 10, 2022



In this note, we propose an approach for initializing the Iterative Closest Point (ICP) algorithm that allows us to apply ICP to unlabelled point clouds that are related by rigid transformations. We also give bounds on the robustness of our approach to noise. Numerical experiments confirm our theoretical findings.
DecisioNet: A Binary-Tree Structured Neural Network
Jul 10, 2022



Deep neural networks (DNNs) and decision trees (DTs) are both state-of-the-art classifiers. DNNs perform well due to their representational learning capabilities, while DTs are computationally efficient as they perform inference along one route (root-to-leaf) that is dependent on the input data. In this paper, we present DecisioNet (DN), a binary-tree structured neural network. We propose a systematic way to convert an existing DNN into a DN to create a lightweight version of the original model. DecisioNet takes the best of both worlds - it uses neural modules to perform representational learning and utilizes its tree structure to perform only a portion of the computations. We evaluate various DN architectures, along with their corresponding baseline models on the FashionMNIST, CIFAR10, and CIFAR100 datasets. We show that the DN variants achieve similar accuracy while significantly reducing the computational cost of the original network.
Fully Convolutional Fractional Scaling
Mar 20, 2022



We introduce a fully convolutional fractional scaling component, FCFS. Fully convolutional networks can be applied to any size input and previously did not support non-integer scaling. Our architecture is simple with an efficient single layer implementation. Examples and code implementations of three common scaling methods are published.