 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally stable video segmentation without video annotations
Oct 17, 2021
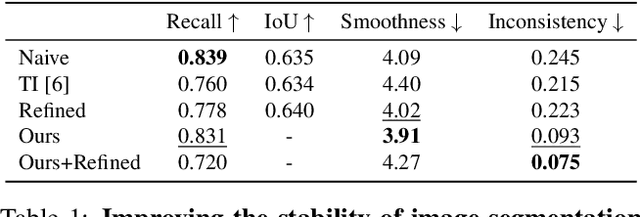
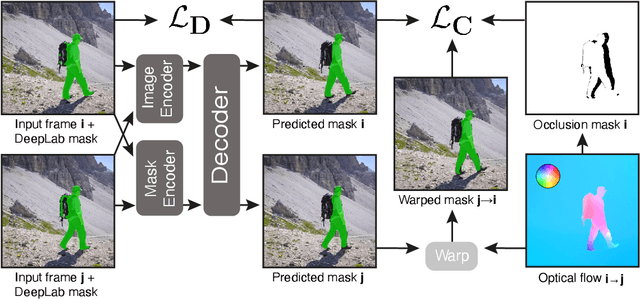
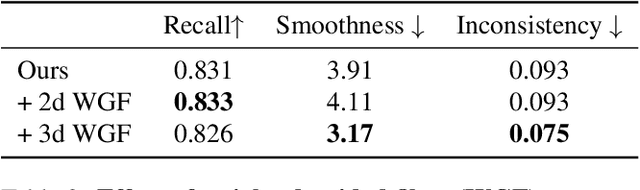
Temporally consistent dense video annotations are scarce and hard to collect. In contrast, image segmentation datasets (and pre-trained models) are ubiquitous, and easier to label for any novel task. In this paper, we introduce a method to adapt still image segmentation models to video in an unsupervised manner, by using an optical flow-based consistency measure. To ensure that the inferred segmented videos appear more stable in practice, we verify that the consistency measure is well correlated with human judgement via a user study. Training a new multi-input multi-output decoder using this measure as a loss, together with a technique for refining current image segmentation datasets and a temporal weighted-guided filter, we observe stability improvements in the generated segmented videos with minimal loss of accuracy.