 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporally stable video segmentation without video annotations
Oct 17, 2021
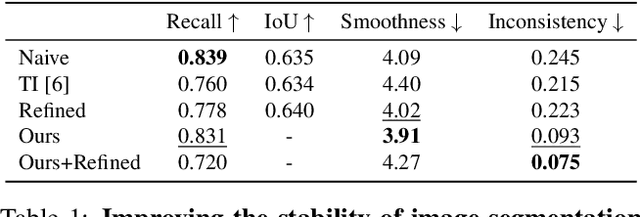
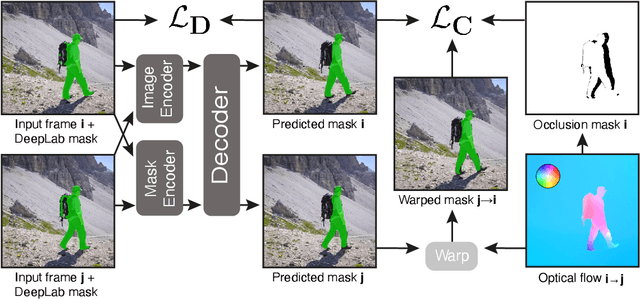
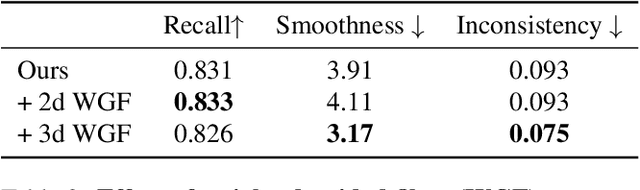
Temporally consistent dense video annotations are scarce and hard to collect. In contrast, image segmentation datasets (and pre-trained models) are ubiquitous, and easier to label for any novel task. In this paper, we introduce a method to adapt still image segmentation models to video in an unsupervised manner, by using an optical flow-based consistency measure. To ensure that the inferred segmented videos appear more stable in practice, we verify that the consistency measure is well correlated with human judgement via a user study. Training a new multi-input multi-output decoder using this measure as a loss, together with a technique for refining current image segmentation datasets and a temporal weighted-guided filter, we observe stability improvements in the generated segmented videos with minimal loss of accuracy.
Endless Loops: Detecting and Animating Periodic Patterns in Still Images
May 19, 2021
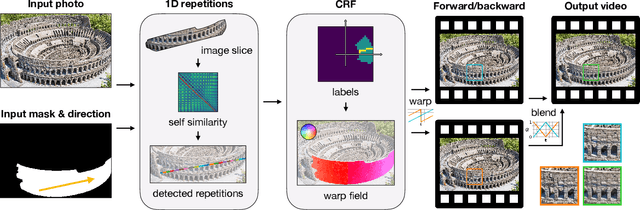

We present an algorithm for producing a seamless animated loop from a single image. The algorithm detects periodic structures, such as the windows of a building or the steps of a staircase, and generates a non-trivial displacement vector field that maps each segment of the structure onto a neighboring segment along a user- or auto-selected main direction of motion. This displacement field is used, together with suitable temporal and spatial smoothing, to warp the image and produce the frames of a continuous animation loop. Our cinemagraphs are created in under a second on a mobile device. Over 140,000 users downloaded our app and exported over 350,000 cinemagraphs. Moreover, we conducted two user studies that show that users prefer our method for creating surreal and structured cinemagraphs compared to more manual approaches and compared to previous methods.
* SIGGRAPH 2021. Project page: https://pub.res.lightricks.com/endless-loops/ . Video: https://youtu.be/8ZYUvxWuD2Y
Training Deep Networks with Structured Layers by Matrix Backpropagation
Apr 14, 2016
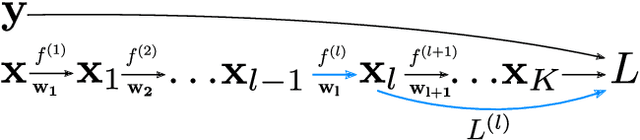


Deep neural network architectures have recently produced excellent results in a variety of areas in artificial intelligence and visual recognition, well surpassing traditional shallow architectures trained using hand-designed features. The power of deep networks stems both from their ability to perform local computations followed by pointwise non-linearities over increasingly larger receptive fields, and from the simplicity and scalability of the gradient-descent training procedure based on backpropagation. An open problem is the inclusion of layers that perform global, structured matrix computations like segmentation (e.g. normalized cuts) or higher-order pooling (e.g. log-tangent space metrics defined over the manifold of symmetric positive definite matrices) while preserving the validity and efficiency of an end-to-end deep training framework. In this paper we propose a sound mathematical apparatus to formally integrate global structured computation into deep computation architectures. At the heart of our methodology is the development of the theory and practice of backpropagation that generalizes to the calculus of adjoint matrix variations. The proposed matrix backpropagation methodology applies broadly to a variety of problems in machine learning or computational perception. Here we illustrate it by performing visual segmentation experiments using the BSDS and MSCOCO benchmarks, where we show that deep networks relying on second-order pooling and normalized cuts layers, trained end-to-end using matrix backpropagation, outperform counterparts that do not take advantage of such global layers.