 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Features and Coordinates for Few-shot RGB Relocalization
Paper and Code
Nov 26, 2019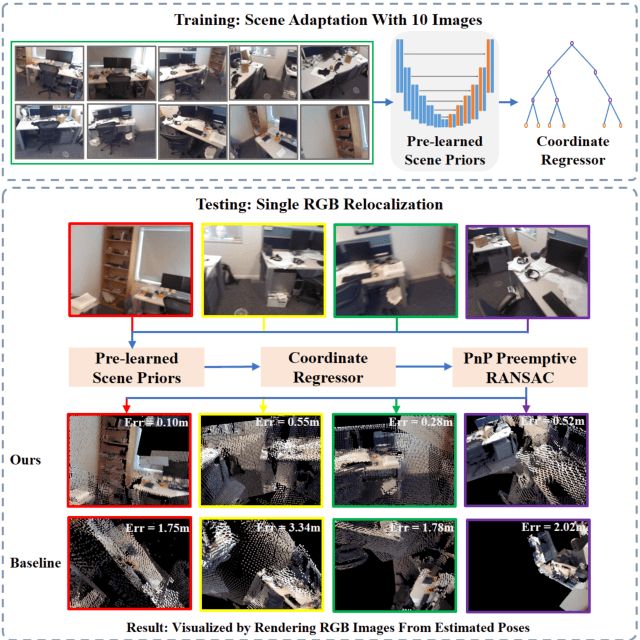
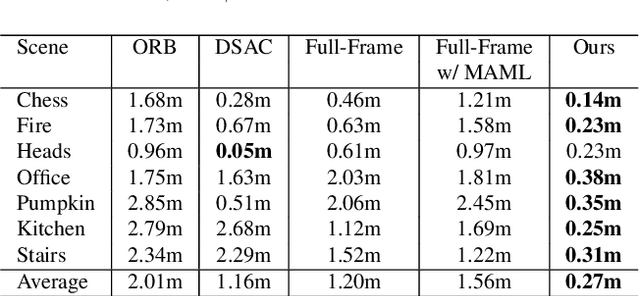
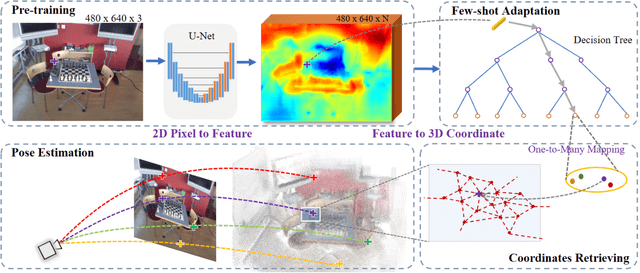
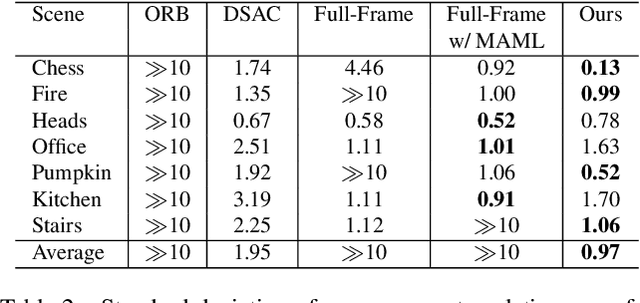
Cross-scene model adaption is a crucial feature for camera relocalization applied in real scenarios. It is preferable that a pre-learned model can be quickly deployed in a novel scene with as little training as possible. The existing state-of-the-art approaches, however, can hardly support few-shot scene adaption due to the entangling of image feature extraction and 3D coordinate regression, which requires a large-scale of training data. To address this issue, inspired by how humans relocalize, we approach camera relocalization with a decoupled solution where feature extraction, coordinate regression and pose estimation are performed separately. Our key insight is that robust and discriminative image features used for coordinate regression should be learned by removing the distracting factor of camera views, because coordinates in the world reference frame are obviously independent of local views. In particular, we employ a deep neural network to learn view-factorized pixel-wise features using several training scenes. Given a new scene, we train a view-dependent per-pixel 3D coordinate regressor while keeping the feature extractor fixed. Such a decoupled design allows us to adapt the entire model to novel scene and achieve accurate camera pose estimation with only few-shot training samples and two orders of magnitude less training time than the state-of-the-arts.