 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeONE-SHOT: Compositional Human-Environment Video Synthesis via Spatial-Decoupled Motion Injection and Hybrid Context Integration
Apr 01, 2026Recent advances in Video Foundation Models (VFMs) have revolutionized human-centric video synthesis, yet fine-grained and independent editing of subjects and scenes remains a critical challenge. Recent attempts to incorporate richer environment control through rigid 3D geometric compositions often encounter a stark trade-off between precise control and generative flexibility. Furthermore, the heavy 3D pre-processing still limits practical scalability. In this paper, we propose ONE-SHOT, a parameter-efficient framework for compositional human-environment video generation. Our key insight is to factorize the generative process into disentangled signals. Specifically, we introduce a canonical-space injection mechanism that decouples human dynamics from environmental cues via cross-attention. We also propose Dynamic-Grounded-RoPE, a novel positional embedding strategy that establishes spatial correspondences between disparate spatial domains without any heuristic 3D alignments. To support long-horizon synthesis, we introduce a Hybrid Context Integration mechanism to maintain subject and scene consistency across minute-level generations. Experiments demonstrate that our method significantly outperforms state-of-the-art methods, offering superior structural control and creative diversity for video synthesis. Our project has been available on: https://martayang.github.io/ONE-SHOT/.
CosmicMan: A Text-to-Image Foundation Model for Humans
Apr 01, 2024



We present CosmicMan, a text-to-image foundation model specialized for generating high-fidelity human images. Unlike current general-purpose foundation models that are stuck in the dilemma of inferior quality and text-image misalignment for humans, CosmicMan enables generating photo-realistic human images with meticulous appearance, reasonable structure, and precise text-image alignment with detailed dense descriptions. At the heart of CosmicMan's success are the new reflections and perspectives on data and models: (1) We found that data quality and a scalable data production flow are essential for the final results from trained models. Hence, we propose a new data production paradigm, Annotate Anyone, which serves as a perpetual data flywheel to produce high-quality data with accurate yet cost-effective annotations over time. Based on this, we constructed a large-scale dataset, CosmicMan-HQ 1.0, with 6 Million high-quality real-world human images in a mean resolution of 1488x1255, and attached with precise text annotations deriving from 115 Million attributes in diverse granularities. (2) We argue that a text-to-image foundation model specialized for humans must be pragmatic -- easy to integrate into down-streaming tasks while effective in producing high-quality human images. Hence, we propose to model the relationship between dense text descriptions and image pixels in a decomposed manner, and present Decomposed-Attention-Refocusing (Daring) training framework. It seamlessly decomposes the cross-attention features in existing text-to-image diffusion model, and enforces attention refocusing without adding extra modules. Through Daring, we show that explicitly discretizing continuous text space into several basic groups that align with human body structure is the key to tackling the misalignment problem in a breeze.
UnitedHuman: Harnessing Multi-Source Data for High-Resolution Human Generation
Sep 25, 2023
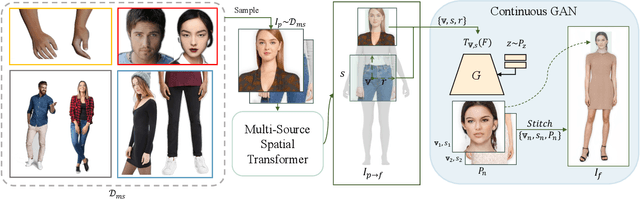

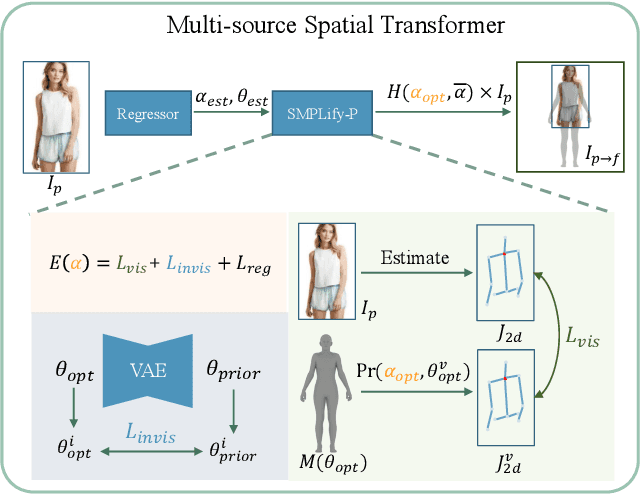
Human generation has achieved significant progress. Nonetheless, existing methods still struggle to synthesize specific regions such as faces and hands. We argue that the main reason is rooted in the training data. A holistic human dataset inevitably has insufficient and low-resolution information on local parts. Therefore, we propose to use multi-source datasets with various resolution images to jointly learn a high-resolution human generative model. However, multi-source data inherently a) contains different parts that do not spatially align into a coherent human, and b) comes with different scales. To tackle these challenges, we propose an end-to-end framework, UnitedHuman, that empowers continuous GAN with the ability to effectively utilize multi-source data for high-resolution human generation. Specifically, 1) we design a Multi-Source Spatial Transformer that spatially aligns multi-source images to full-body space with a human parametric model. 2) Next, a continuous GAN is proposed with global-structural guidance and CutMix consistency. Patches from different datasets are then sampled and transformed to supervise the training of this scale-invariant generative model. Extensive experiments demonstrate that our model jointly learned from multi-source data achieves superior quality than those learned from a holistic dataset.
StyleGAN-Human: A Data-Centric Odyssey of Human Generation
Apr 25, 2022

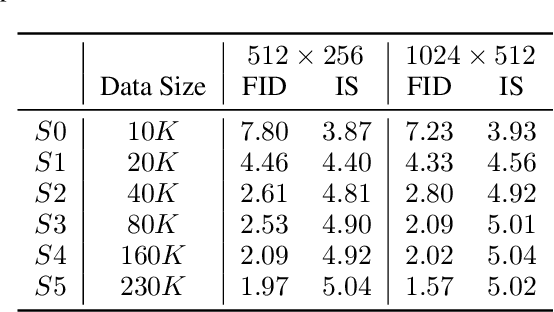
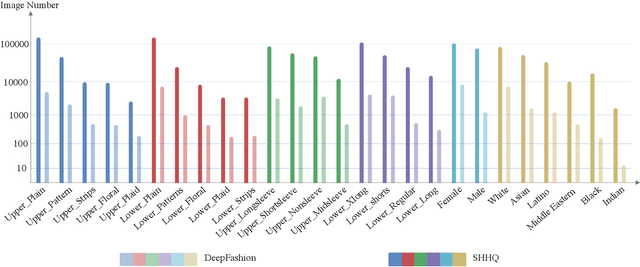
Unconditional human image generation is an important task in vision and graphics, which enables various applications in the creative industry. Existing studies in this field mainly focus on "network engineering" such as designing new components and objective functions. This work takes a data-centric perspective and investigates multiple critical aspects in "data engineering", which we believe would complement the current practice. To facilitate a comprehensive study, we collect and annotate a large-scale human image dataset with over 230K samples capturing diverse poses and textures. Equipped with this large dataset, we rigorously investigate three essential factors in data engineering for StyleGAN-based human generation, namely data size, data distribution, and data alignment. Extensive experiments reveal several valuable observations w.r.t. these aspects: 1) Large-scale data, more than 40K images, are needed to train a high-fidelity unconditional human generation model with vanilla StyleGAN. 2) A balanced training set helps improve the generation quality with rare face poses compared to the long-tailed counterpart, whereas simply balancing the clothing texture distribution does not effectively bring an improvement. 3) Human GAN models with body centers for alignment outperform models trained using face centers or pelvis points as alignment anchors. In addition, a model zoo and human editing applications are demonstrated to facilitate future research in the community.
Datasets for Face and Object Detection in Fisheye Images
Jun 27, 2019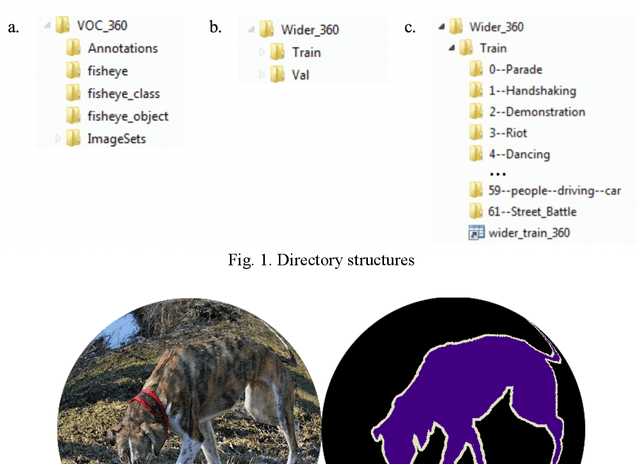



We present two new fisheye image datasets for training face and object detection models: VOC-360 and Wider-360. The fisheye images are created by post-processing regular images collected from two well-known datasets, VOC2012 and Wider Face, using a model for mapping regular to fisheye images implemented in Matlab. VOC-360 contains 39,575 fisheye images for object detection, segmentation, and classification. Wider-360 contains 63,897 fisheye images for face detection. These datasets will be useful for developing face and object detectors as well as segmentation modules for fisheye images while the efforts to collect and manually annotate true fisheye images are underway.
FDDB-360: Face Detection in 360-degree Fisheye Images
Feb 07, 2019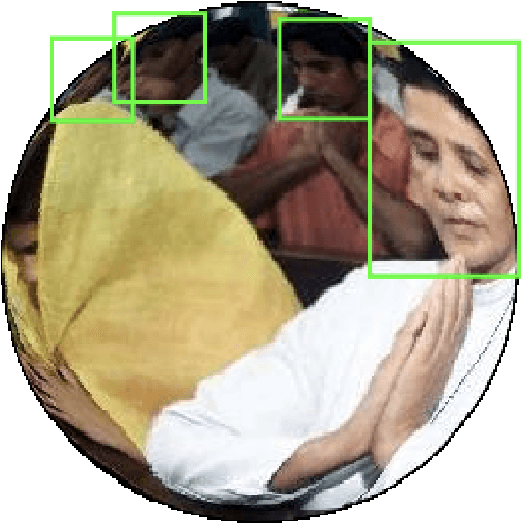

360-degree cameras offer the possibility to cover a large area, for example an entire room, without using multiple distributed vision sensors. However, geometric distortions introduced by their lenses make computer vision problems more challenging. In this paper we address face detection in 360-degree fisheye images. We show how a face detector trained on regular images can be re-trained for this purpose, and we also provide a 360-degree fisheye-like version of the popular FDDB face detection dataset, which we call FDDB-360.