 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Evolutionary Large Language Models through Uncertainty-Enhanced Preference Optimization
Paper and Code
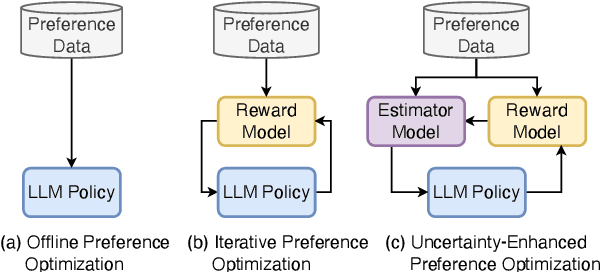
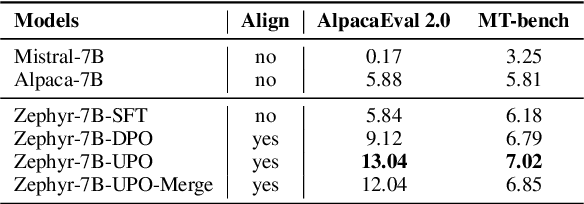
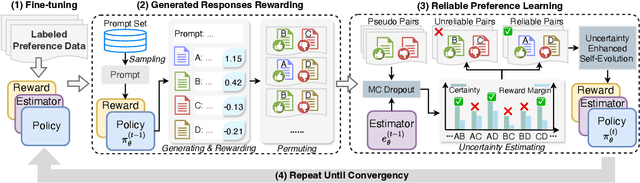
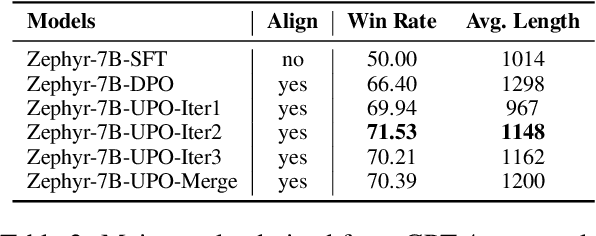
Iterative preference optimization has recently become one of the de-facto training paradigms for large language models (LLMs), but the performance is still underwhelming due to too much noisy preference data yielded in the loop. To combat this issue, we present an \textbf{U}ncertainty-enhanced \textbf{P}reference \textbf{O}ptimization (UPO) framework to make the LLM self-evolve with reliable feedback. The key idea is mitigating the noisy preference data derived from the current policy and reward models by performing pair-wise uncertainty estimation and judiciously reliable feedback sampling. To reach this goal, we thus introduce an estimator model, which incorporates Monte Carlo (MC) dropout in Bayesian neural network (BNN) to perform uncertainty estimation for the preference data derived from the LLM policy. Compared to the existing methods that directly filter generated responses based on the reward score, the estimator focuses on the model uncertainty in a pair-wise manner and effectively bypasses the confirmation bias problem of the reward model. Additionally, we also propose an uncertainty-enhanced self-evolution algorithm to improve the robustness of preference optimization and encourage the LLM to generate responses with both high reward and certainty. Extensive experiments over multiple benchmarks demonstrate that our framework substantially alleviates the noisy problem and improves the performance of iterative preference optimization.