 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Improving for Zero-Shot Named Entity Recognition with Large Language Models
Paper and Code
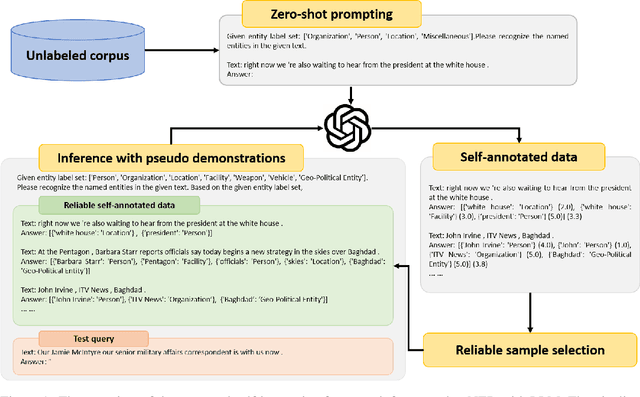
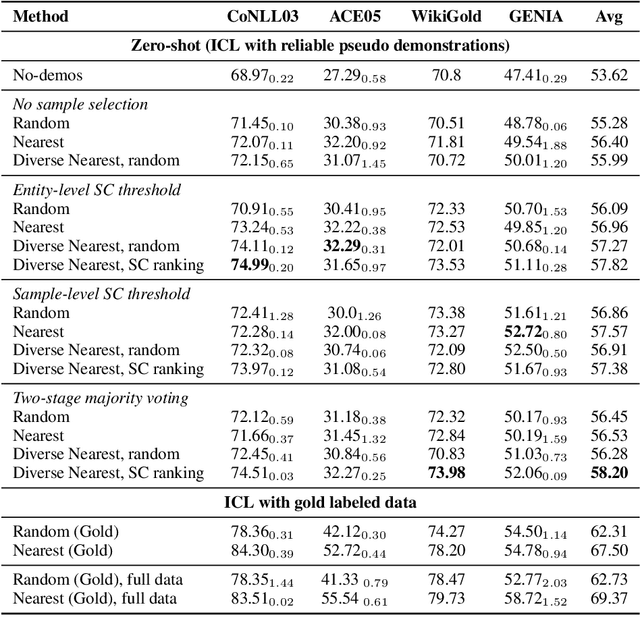
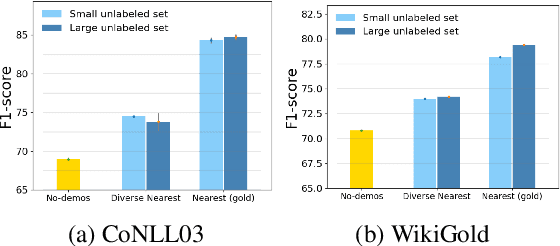
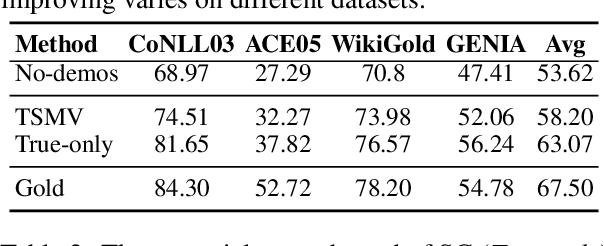
Exploring the application of powerful large language models (LLMs) on the fundamental named entity recognition (NER) task has drawn much attention recently. This work aims to investigate the possibilities of pushing the boundary of zero-shot NER with LLM via a training-free self-improving strategy. We propose a self-improving framework, which utilize an unlabeled corpus to stimulate the self-learning ability of LLMs on NER. First, we use LLM to make predictions on the unlabeled corpus and obtain the self-annotated data. Second, we explore various strategies to select reliable samples from the self-annotated dataset as demonstrations, considering the similarity, diversity and reliability of demonstrations. Finally, we conduct inference for the test query via in-context learning with the selected self-annotated demonstrations. Through comprehensive experimental analysis, our study yielded the following findings: (1) The self-improving framework further pushes the boundary of zero-shot NER with LLMs, and achieves an obvious performance improvement; (2) Iterative self-improving or naively increasing the size of unlabeled corpus does not guarantee improvements; (3) There might still be space for improvement via more advanced strategy for reliable entity selection.