 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDALI: Domain Adaptive LiDAR Object Detection via Distribution-level and Instance-level Pseudo Label Denoising
Dec 11, 2024



Object detection using LiDAR point clouds relies on a large amount of human-annotated samples when training the underlying detectors' deep neural networks. However, generating 3D bounding box annotation for a large-scale dataset could be costly and time-consuming. Alternatively, unsupervised domain adaptation (UDA) enables a given object detector to operate on a novel new data, with unlabeled training dataset, by transferring the knowledge learned from training labeled \textit{source domain} data to the new unlabeled \textit{target domain}. Pseudo label strategies, which involve training the 3D object detector using target-domain predicted bounding boxes from a pre-trained model, are commonly used in UDA. However, these pseudo labels often introduce noise, impacting performance. In this paper, we introduce the Domain Adaptive LIdar (DALI) object detection framework to address noise at both distribution and instance levels. Firstly, a post-training size normalization (PTSN) strategy is developed to mitigate bias in pseudo label size distribution by identifying an unbiased scale after network training. To address instance-level noise between pseudo labels and corresponding point clouds, two pseudo point clouds generation (PPCG) strategies, ray-constrained and constraint-free, are developed to generate pseudo point clouds for each instance, ensuring the consistency between pseudo labels and pseudo points during training. We demonstrate the effectiveness of our method on the publicly available and popular datasets KITTI, Waymo, and nuScenes. We show that the proposed DALI framework achieves state-of-the-art results and outperforms leading approaches on most of the domain adaptation tasks. Our code is available at \href{https://github.com/xiaohulugo/T-RO2024-DALI}{https://github.com/xiaohulugo/T-RO2024-DALI}.
ScAR: Scaling Adversarial Robustness for LiDAR Object Detection
Dec 05, 2023The adversarial robustness of a model is its ability to resist adversarial attacks in the form of small perturbations to input data. Universal adversarial attack methods such as Fast Sign Gradient Method (FSGM) and Projected Gradient Descend (PGD) are popular for LiDAR object detection, but they are often deficient compared to task-specific adversarial attacks. Additionally, these universal methods typically require unrestricted access to the model's information, which is difficult to obtain in real-world applications. To address these limitations, we present a black-box Scaling Adversarial Robustness (ScAR) method for LiDAR object detection. By analyzing the statistical characteristics of 3D object detection datasets such as KITTI, Waymo, and nuScenes, we have found that the model's prediction is sensitive to scaling of 3D instances. We propose three black-box scaling adversarial attack methods based on the available information: model-aware attack, distribution-aware attack, and blind attack. We also introduce a strategy for generating scaling adversarial examples to improve the model's robustness against these three scaling adversarial attacks. Comparison with other methods on public datasets under different 3D object detection architectures demonstrates the effectiveness of our proposed method.
Strong-Weak Integrated Semi-supervision for Unsupervised Single and Multi Target Domain Adaptation
Sep 12, 2023



Unsupervised domain adaptation (UDA) focuses on transferring knowledge learned in the labeled source domain to the unlabeled target domain. Despite significant progress that has been achieved in single-target domain adaptation for image classification in recent years, the extension from single-target to multi-target domain adaptation is still a largely unexplored problem area. In general, unsupervised domain adaptation faces a major challenge when attempting to learn reliable information from a single unlabeled target domain. Increasing the number of unlabeled target domains further exacerbate the problem rather significantly. In this paper, we propose a novel strong-weak integrated semi-supervision (SWISS) learning strategy for image classification using unsupervised domain adaptation that works well for both single-target and multi-target scenarios. Under the proposed SWISS-UDA framework, a strong representative set with high confidence but low diversity target domain samples and a weak representative set with low confidence but high diversity target domain samples are updated constantly during the training process. Both sets are fused to generate an augmented strong-weak training batch with pseudo-labels to train the network during every iteration. The extension from single-target to multi-target domain adaptation is accomplished by exploring the class-wise distance relationship between domains and replacing the strong representative set with much stronger samples from peer domains via peer scaffolding. Moreover, a novel adversarial logit loss is proposed to reduce the intra-class divergence between source and target domains, which is back-propagated adversarially with a gradient reverse layer between the classifier and the rest of the network. Experimental results based on three benchmarks, Office-31, Office-Home, and DomainNet, show the effectiveness of the proposed SWISS framework.
3D Iterative Spatiotemporal Filtering for Classification of Multitemporal Satellite Data Sets
Jul 01, 2021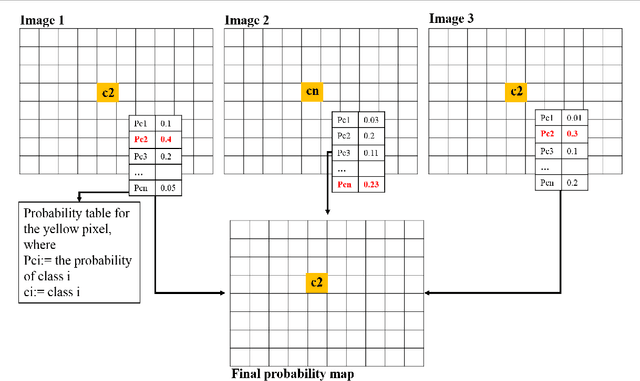

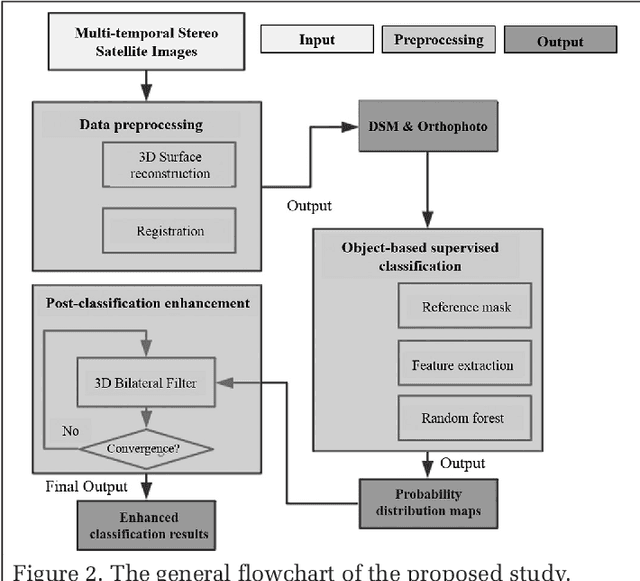
The current practice in land cover/land use change analysis relies heavily on the individually classified maps of the multitemporal data set. Due to varying acquisition conditions (e.g., illumination, sensors, seasonal differences), the classification maps yielded are often inconsistent through time for robust statistical analysis. 3D geometric features have been shown to be stable for assessing differences across the temporal data set. Therefore, in this article we investigate he use of a multitemporal orthophoto and digital surface model derived from satellite data for spatiotemporal classification. Our approach consists of two major steps: generating per-class probability distribution maps using the random-forest classifier with limited training samples, and making spatiotemporal inferences using an iterative 3D spatiotemporal filter operating on per-class probability maps. Our experimental results demonstrate that the proposed methods can consistently improve the individual classification results by 2%-6% and thus can be an important postclassification refinement approach.
Using Orthophoto for Building Boundary Sharpening in the Digital Surface Model
May 22, 2019



Nowadays dense stereo matching has become one of the dominant tools in 3D reconstruction of urban regions for its low cost and high flexibility in generating dense 3D points. However, state-of-the-art stereo matching algorithms usually apply a semi-global matching (SGM) strategy. This strategy normally assumes the surface geometry pieceswise planar, where a smooth penalty is imposed to deal with non-texture or repeating-texture areas. This on one hand, generates much smooth surface models, while on the other hand, may partially leads to smoothing on depth discontinuities, particularly for fence-shaped regions or densely built areas with narrow streets. To solve this problem, in this work, we propose to use the line segment information extracted from the corresponding orthophoto as a pose-processing tool to sharpen the building boundary of the Digital Surface Model (DSM) generated by SGM. Two methods which are based on graph-cut and plane fitting are proposed and compared. Experimental results on several satellite datasets with ground truth show the robustness and effectiveness of the proposed DSM sharpening method.
A Comparison of Stereo-Matching Cost between Convolutional Neural Network and Census for Satellite Images
May 22, 2019
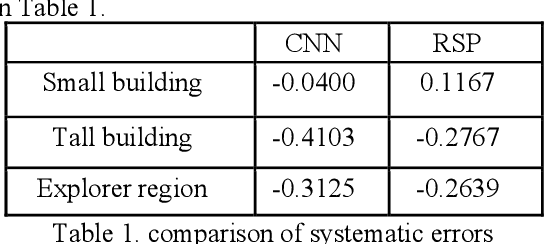
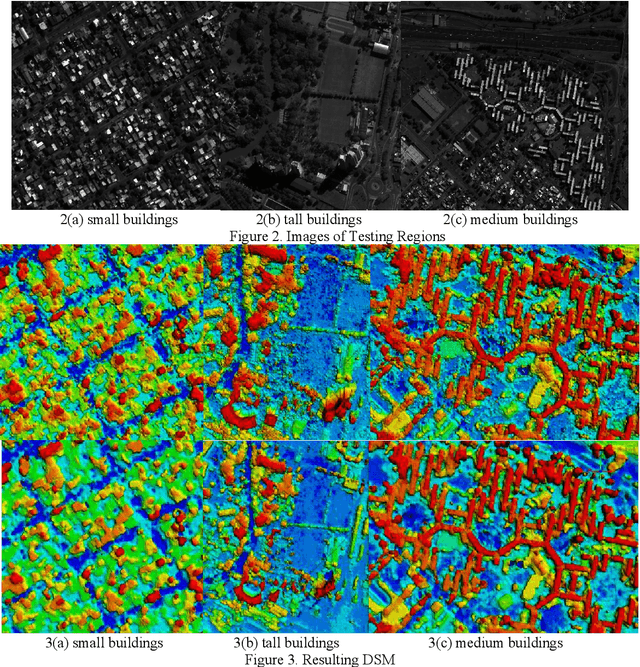
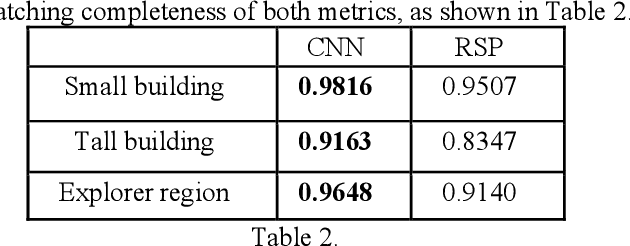
Stereo dense image matching can be categorized to low-level feature based matching and deep feature based matching according to their matching cost metrics. Census has been proofed to be one of the most efficient low-level feature based matching methods, while fast Convolutional Neural Network (fst-CNN), as a deep feature based method, has small computing time and is robust for satellite images. Thus, a comparison between fst-CNN and census is critical for further studies in stereo dense image matching. This paper used cost function of fst-CNN and census to do stereo matching, then utilized semi-global matching method to obtain optimized disparity images. Those images are used to produce digital surface model to compare with ground truth points. It addresses that fstCNN performs better than census in the aspect of absolute matching accuracy, histogram of error distribution and matching completeness, but these two algorithms still performs in the same order of magnitude.
Fast 3D Line Segment Detection From Unorganized Point Cloud
Jan 08, 2019

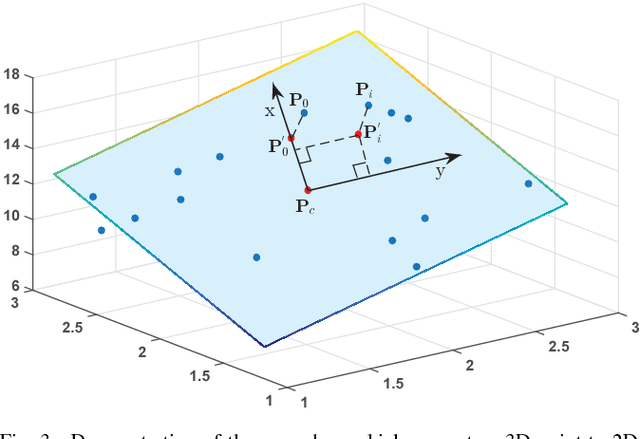

This paper presents a very simple but efficient algorithm for 3D line segment detection from large scale unorganized point cloud. Unlike traditional methods which usually extract 3D edge points first and then link them to fit for 3D line segments, we propose a very simple 3D line segment detection algorithm based on point cloud segmentation and 2D line detection. Given the input unorganized point cloud, three steps are performed to detect 3D line segments. Firstly, the point cloud is segmented into 3D planes via region growing and region merging. Secondly, for each 3D plane, all the points belonging to it are projected onto the plane itself to form a 2D image, which is followed by 2D contour extraction and Least Square Fitting to get the 2D line segments. Those 2D line segments are then re-projected onto the 3D plane to get the corresponding 3D line segments. Finally, a post-processing procedure is proposed to eliminate outliers and merge adjacent 3D line segments. Experiments on several public datasets demonstrate the efficiency and robustness of our method. More results and the C++ source code of the proposed algorithm are publicly available at https://github.com/xiaohulugo/3DLineDetection.
Learning to Refine Object Contours with a Top-Down Fully Convolutional Encoder-Decoder Network
May 12, 2017
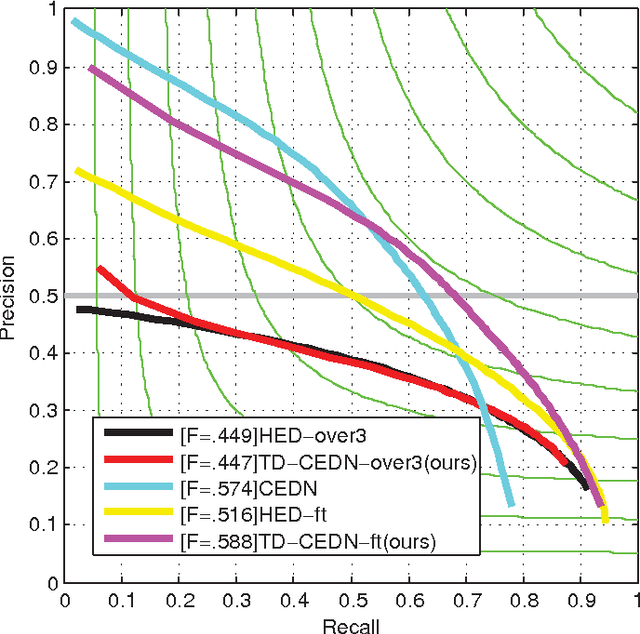


We develop a novel deep contour detection algorithm with a top-down fully convolutional encoder-decoder network. Our proposed method, named TD-CEDN, solves two important issues in this low-level vision problem: (1) learning multi-scale and multi-level features; and (2) applying an effective top-down refined approach in the networks. TD-CEDN performs the pixel-wise prediction by means of leveraging features at all layers of the net. Unlike skip connections and previous encoder-decoder methods, we first learn a coarse feature map after the encoder stage in a feedforward pass, and then refine this feature map in a top-down strategy during the decoder stage utilizing features at successively lower layers. Therefore, the deconvolutional process is conducted stepwise, which is guided by Deeply-Supervision Net providing the integrated direct supervision. The above proposed technologies lead to a more precise and clearer prediction. Our proposed algorithm achieved the state-of-the-art on the BSDS500 dataset (ODS F-score of 0.788), the PASCAL VOC2012 dataset (ODS F-score of 0.588), and and the NYU Depth dataset (ODS F-score of 0.735).