 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Approximate Adaptive Kernel Convolution on Graphs
Jan 22, 2024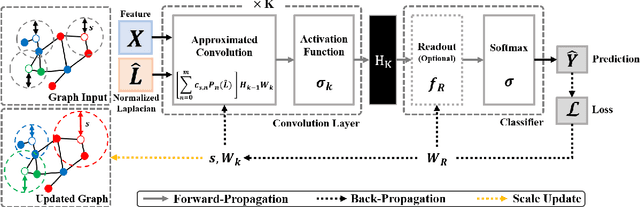
Various Graph Neural Networks (GNNs) have been successful in analyzing data in non-Euclidean spaces, however, they have limitations such as oversmoothing, i.e., information becomes excessively averaged as the number of hidden layers increases. The issue stems from the intrinsic formulation of conventional graph convolution where the nodal features are aggregated from a direct neighborhood per layer across the entire nodes in the graph. As setting different number of hidden layers per node is infeasible, recent works leverage a diffusion kernel to redefine the graph structure and incorporate information from farther nodes. Unfortunately, such approaches suffer from heavy diagonalization of a graph Laplacian or learning a large transform matrix. In this regards, we propose a diffusion learning framework, where the range of feature aggregation is controlled by the scale of a diffusion kernel. For efficient computation, we derive closed-form derivatives of approximations of the graph convolution with respect to the scale, so that node-wise range can be adaptively learned. With a downstream classifier, the entire framework is made trainable in an end-to-end manner. Our model is tested on various standard datasets for node-wise classification for the state-of-the-art performance, and it is also validated on a real-world brain network data for graph classifications to demonstrate its practicality for Alzheimer classification.