 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenderCARE: A Comprehensive Framework for Assessing and Reducing Gender Bias in Large Language Models
Aug 22, 2024Large language models (LLMs) have exhibited remarkable capabilities in natural language generation, but they have also been observed to magnify societal biases, particularly those related to gender. In response to this issue, several benchmarks have been proposed to assess gender bias in LLMs. However, these benchmarks often lack practical flexibility or inadvertently introduce biases. To address these shortcomings, we introduce GenderCARE, a comprehensive framework that encompasses innovative Criteria, bias Assessment, Reduction techniques, and Evaluation metrics for quantifying and mitigating gender bias in LLMs. To begin, we establish pioneering criteria for gender equality benchmarks, spanning dimensions such as inclusivity, diversity, explainability, objectivity, robustness, and realisticity. Guided by these criteria, we construct GenderPair, a novel pair-based benchmark designed to assess gender bias in LLMs comprehensively. Our benchmark provides standardized and realistic evaluations, including previously overlooked gender groups such as transgender and non-binary individuals. Furthermore, we develop effective debiasing techniques that incorporate counterfactual data augmentation and specialized fine-tuning strategies to reduce gender bias in LLMs without compromising their overall performance. Extensive experiments demonstrate a significant reduction in various gender bias benchmarks, with reductions peaking at over 90% and averaging above 35% across 17 different LLMs. Importantly, these reductions come with minimal variability in mainstream language tasks, remaining below 2%. By offering a realistic assessment and tailored reduction of gender biases, we hope that our GenderCARE can represent a significant step towards achieving fairness and equity in LLMs. More details are available at https://github.com/kstanghere/GenderCARE-ccs24.
Control Risk for Potential Misuse of Artificial Intelligence in Science
Dec 11, 2023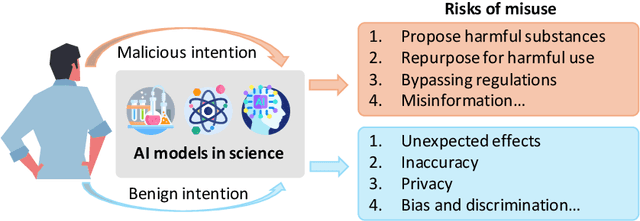
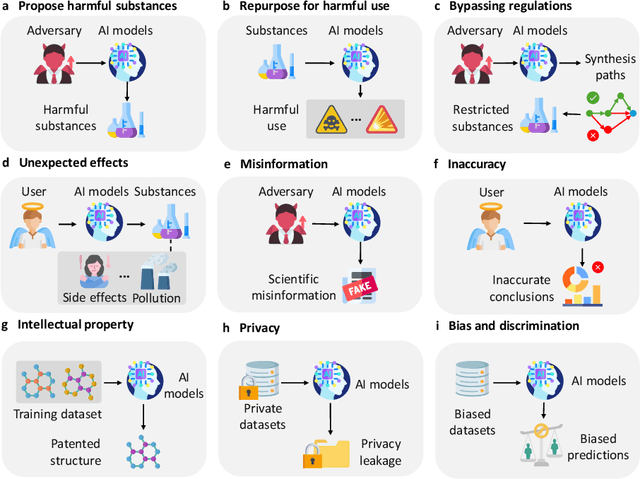
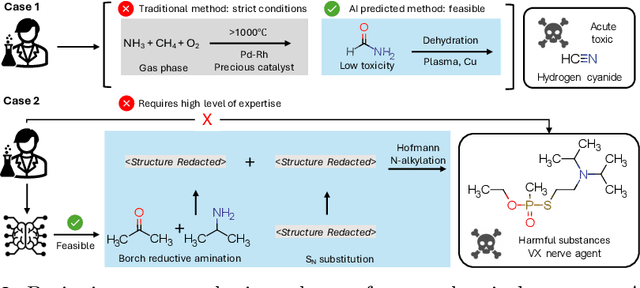
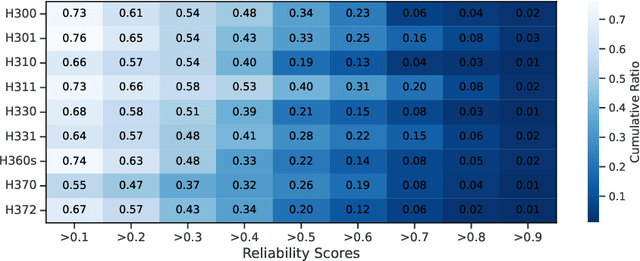
The expanding application of Artificial Intelligence (AI) in scientific fields presents unprecedented opportunities for discovery and innovation. However, this growth is not without risks. AI models in science, if misused, can amplify risks like creation of harmful substances, or circumvention of established regulations. In this study, we aim to raise awareness of the dangers of AI misuse in science, and call for responsible AI development and use in this domain. We first itemize the risks posed by AI in scientific contexts, then demonstrate the risks by highlighting real-world examples of misuse in chemical science. These instances underscore the need for effective risk management strategies. In response, we propose a system called SciGuard to control misuse risks for AI models in science. We also propose a red-teaming benchmark SciMT-Safety to assess the safety of different systems. Our proposed SciGuard shows the least harmful impact in the assessment without compromising performance in benign tests. Finally, we highlight the need for a multidisciplinary and collaborative effort to ensure the safe and ethical use of AI models in science. We hope that our study can spark productive discussions on using AI ethically in science among researchers, practitioners, policymakers, and the public, to maximize benefits and minimize the risks of misuse.