 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQ*: Improving Multi-step Reasoning for LLMs with Deliberative Planning
Jun 20, 2024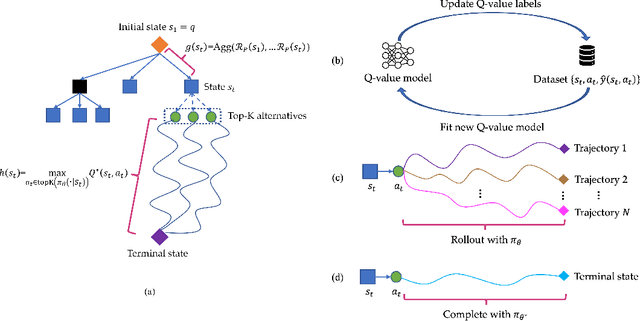
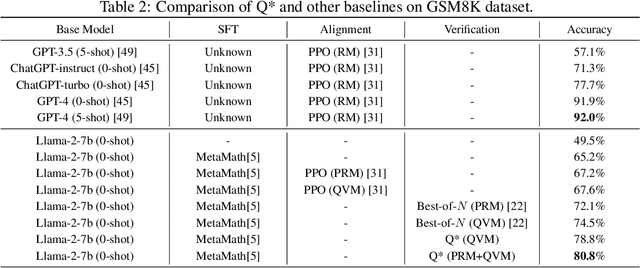
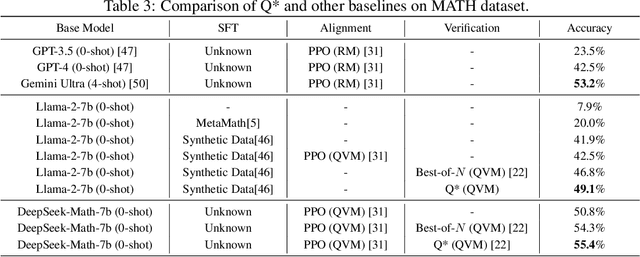
Large Language Models (LLMs) have demonstrated impressive capability in many nature language tasks. However, the auto-regressive generation process makes LLMs prone to produce errors, hallucinations and inconsistent statements when performing multi-step reasoning. In this paper, we aim to alleviate the pathology by introducing Q*, a general, versatile and agile framework for guiding LLMs decoding process with deliberative planning. By learning a plug-and-play Q-value model as heuristic function, our Q* can effectively guide LLMs to select the most promising next step without fine-tuning LLMs for each task, which avoids the significant computational overhead and potential risk of performance degeneration on other tasks. Extensive experiments on GSM8K, MATH and MBPP confirm the superiority of our method.