 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Relaxations Go Bad: "Differentially-Private" Machine Learning
Paper and Code

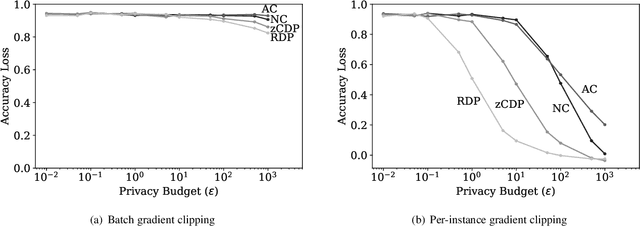
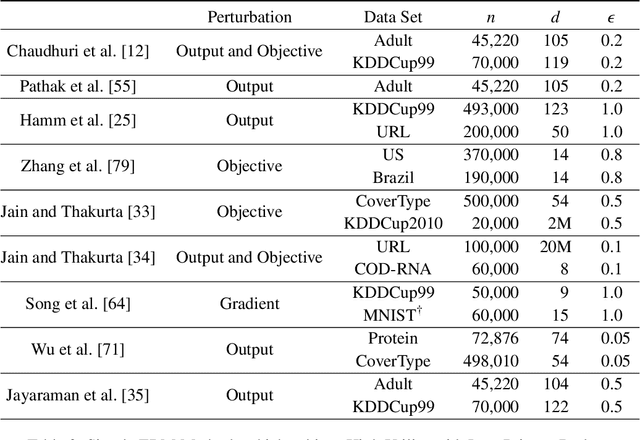
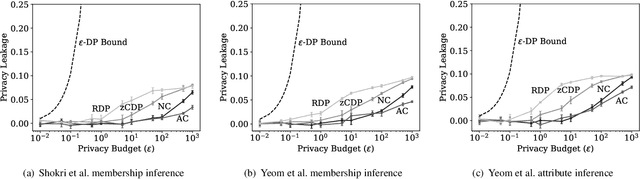
Differential privacy is becoming a standard notion for performing privacy-preserving machine learning over sensitive data. It provides formal guarantees, in terms of the privacy budget, $\epsilon$, on how much information about individual training records is leaked by the model. While the privacy budget is directly correlated to the privacy leakage, the calibration of the privacy budget is not well understood. As a result, many existing works on privacy-preserving machine learning select large values of $\epsilon$ in order to get acceptable utility of the model, with little understanding of the concrete impact of such choices on meaningful privacy. Moreover, in scenarios where iterative learning procedures are used which require privacy guarantees for each iteration, relaxed definitions of differential privacy are often used which further tradeoff privacy for better utility. In this paper, we evaluate the impacts of these choices on privacy in experiments with logistic regression and neural network models. We quantify the privacy leakage in terms of advantage of the adversary performing inference attacks and by analyzing the number of members at risk for exposure. Our main findings are that current mechanisms for differential privacy for machine learning rarely offer acceptable utility-privacy tradeoffs: settings that provide limited accuracy loss provide little effective privacy, and settings that provide strong privacy result in useless models. Open source code is available at https://github.com/bargavj/EvaluatingDPML.