 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure Detection for Contextual Reinforcement Learning
Jan 13, 2026Contextual Reinforcement Learning (CRL) tackles the problem of solving a set of related Contextual Markov Decision Processes (CMDPs) that vary across different context variables. Traditional approaches--independent training and multi-task learning--struggle with either excessive computational costs or negative transfer. A recently proposed multi-policy approach, Model-Based Transfer Learning (MBTL), has demonstrated effectiveness by strategically selecting a few tasks to train and zero-shot transfer. However, CMDPs encompass a wide range of problems, exhibiting structural properties that vary from problem to problem. As such, different task selection strategies are suitable for different CMDPs. In this work, we introduce Structure Detection MBTL (SD-MBTL), a generic framework that dynamically identifies the underlying generalization structure of CMDP and selects an appropriate MBTL algorithm. For instance, we observe Mountain structure in which generalization performance degrades from the training performance of the target task as the context difference increases. We thus propose M/GP-MBTL, which detects the structure and adaptively switches between a Gaussian Process-based approach and a clustering-based approach. Extensive experiments on synthetic data and CRL benchmarks--covering continuous control, traffic control, and agricultural management--show that M/GP-MBTL surpasses the strongest prior method by 12.49% on the aggregated metric. These results highlight the promise of online structure detection for guiding source task selection in complex CRL environments.
A Roadmap for Climate-Relevant Robotics Research
Jul 15, 2025



Climate change is one of the defining challenges of the 21st century, and many in the robotics community are looking for ways to contribute. This paper presents a roadmap for climate-relevant robotics research, identifying high-impact opportunities for collaboration between roboticists and experts across climate domains such as energy, the built environment, transportation, industry, land use, and Earth sciences. These applications include problems such as energy systems optimization, construction, precision agriculture, building envelope retrofits, autonomous trucking, and large-scale environmental monitoring. Critically, we include opportunities to apply not only physical robots but also the broader robotics toolkit - including planning, perception, control, and estimation algorithms - to climate-relevant problems. A central goal of this roadmap is to inspire new research directions and collaboration by highlighting specific, actionable problems at the intersection of robotics and climate. This work represents a collaboration between robotics researchers and domain experts in various climate disciplines, and it serves as an invitation to the robotics community to bring their expertise to bear on urgent climate priorities.
The Nah Bandit: Modeling User Non-compliance in Recommendation Systems
Aug 15, 2024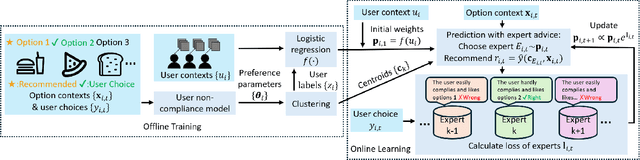
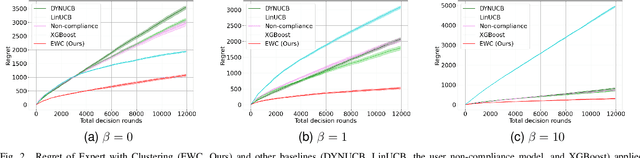
Recommendation systems now pervade the digital world, ranging from advertising to entertainment. However, it remains challenging to implement effective recommendation systems in the physical world, such as in mobility or health. This work focuses on a key challenge: in the physical world, it is often easy for the user to opt out of taking any recommendation if they are not to her liking, and to fall back to her baseline behavior. It is thus crucial in cyber-physical recommendation systems to operate with an interaction model that is aware of such user behavior, lest the user abandon the recommendations altogether. This paper thus introduces the Nah Bandit, a tongue-in-cheek reference to describe a Bandit problem where users can say `nah' to the recommendation and opt for their preferred option instead. As such, this problem lies in between a typical bandit setup and supervised learning. We model the user non-compliance by parameterizing an anchoring effect of recommendations on users. We then propose the Expert with Clustering (EWC) algorithm, a hierarchical approach that incorporates feedback from both recommended and non-recommended options to accelerate user preference learning. In a recommendation scenario with $N$ users, $T$ rounds per user, and $K$ clusters, EWC achieves a regret bound of $O(N\sqrt{T\log K} + NT)$, achieving superior theoretical performance in the short term compared to LinUCB algorithm. Experimental results also highlight that EWC outperforms both supervised learning and traditional contextual bandit approaches. This advancement reveals that effective use of non-compliance feedback can accelerate preference learning and improve recommendation accuracy. This work lays the foundation for future research in Nah Bandit, providing a robust framework for more effective recommendation systems.
Model-Based Transfer Learning for Contextual Reinforcement Learning
Aug 08, 2024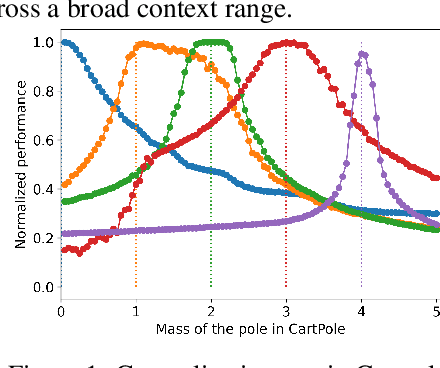
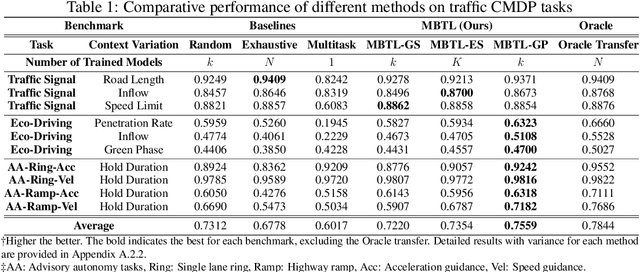
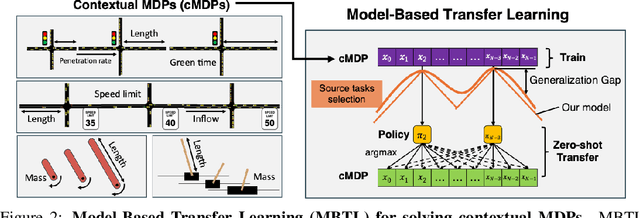
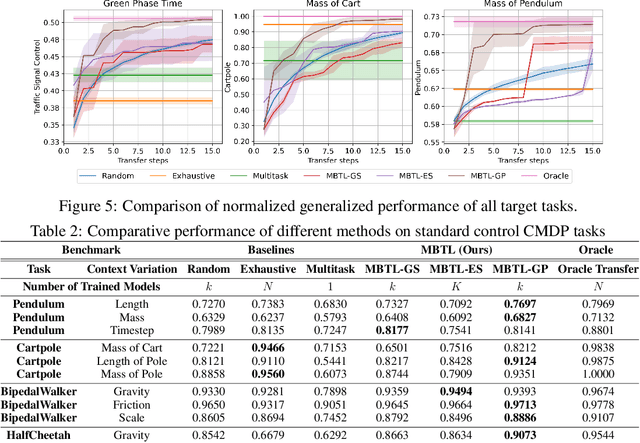
Deep reinforcement learning is a powerful approach to complex decision making. However, one issue that limits its practical application is its brittleness, sometimes failing to train in the presence of small changes in the environment. This work is motivated by the empirical observation that directly applying an already trained model to a related task often works remarkably well, also called zero-shot transfer. We take this practical trick one step further to consider how to systematically select good tasks to train, maximizing overall performance across a range of tasks. Given the high cost of training, it is critical to choose a small set of training tasks. The key idea behind our approach is to explicitly model the performance loss (generalization gap) incurred by transferring a trained model. We hence introduce Model-Based Transfer Learning (MBTL) for solving contextual RL problems. In this work, we model the performance loss as a simple linear function of task context similarity. Furthermore, we leverage Bayesian optimization techniques to efficiently model and estimate the unknown training performance of the task space. We theoretically show that the method exhibits regret that is sublinear in the number of training tasks and discuss conditions to further tighten regret bounds. We experimentally validate our methods using urban traffic and standard control benchmarks. Despite the conceptual simplicity, the experimental results suggest that MBTL can achieve greater performance than strong baselines, including exhaustive training on all tasks, multi-task training, and random selection of training tasks. This work lays the foundations for investigating explicit modeling of generalization, thereby enabling principled yet effective methods for contextual RL.
Cooperative Advisory Residual Policies for Congestion Mitigation
Jun 30, 2024



Fleets of autonomous vehicles can mitigate traffic congestion through simple actions, thus improving many socioeconomic factors such as commute time and gas costs. However, these approaches are limited in practice as they assume precise control over autonomous vehicle fleets, incur extensive installation costs for a centralized sensor ecosystem, and also fail to account for uncertainty in driver behavior. To this end, we develop a class of learned residual policies that can be used in cooperative advisory systems and only require the use of a single vehicle with a human driver. Our policies advise drivers to behave in ways that mitigate traffic congestion while accounting for diverse driver behaviors, particularly drivers' reactions to instructions, to provide an improved user experience. To realize such policies, we introduce an improved reward function that explicitly addresses congestion mitigation and driver attitudes to advice. We show that our residual policies can be personalized by conditioning them on an inferred driver trait that is learned in an unsupervised manner with a variational autoencoder. Our policies are trained in simulation with our novel instruction adherence driver model, and evaluated in simulation and through a user study (N=16) to capture the sentiments of human drivers. Our results show that our approaches successfully mitigate congestion while adapting to different driver behaviors, with up to 20% and 40% improvement as measured by a combination metric of speed and deviations in speed across time over baselines in our simulation tests and user study, respectively. Our user study further shows that our policies are human-compatible and personalize to drivers.
Expert with Clustering: Hierarchical Online Preference Learning Framework
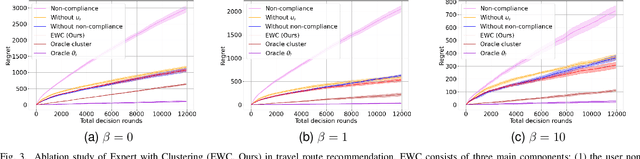
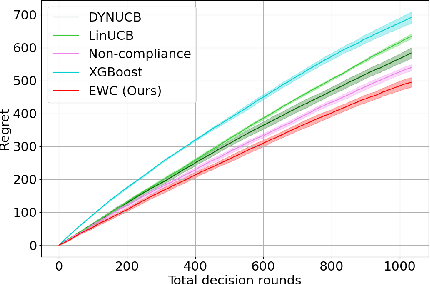
Jan 26, 2024Emerging mobility systems are increasingly capable of recommending options to mobility users, to guide them towards personalized yet sustainable system outcomes. Even more so than the typical recommendation system, it is crucial to minimize regret, because 1) the mobility options directly affect the lives of the users, and 2) the system sustainability relies on sufficient user participation. In this study, we consider accelerating user preference learning by exploiting a low-dimensional latent space that captures the mobility preferences of users. We introduce a hierarchical contextual bandit framework named Expert with Clustering (EWC), which integrates clustering techniques and prediction with expert advice. EWC efficiently utilizes hierarchical user information and incorporates a novel Loss-guided Distance metric. This metric is instrumental in generating more representative cluster centroids. In a recommendation scenario with $N$ users, $T$ rounds per user, and $K$ options, our algorithm achieves a regret bound of $O(N\sqrt{T\log K} + NT)$. This bound consists of two parts: the first term is the regret from the Hedge algorithm, and the second term depends on the average loss from clustering. The algorithm performs with low regret, especially when a latent hierarchical structure exists among users. This regret bound underscores the theoretical and experimental efficacy of EWC, particularly in scenarios that demand rapid learning and adaptation. Experimental results highlight that EWC can substantially reduce regret by 27.57% compared to the LinUCB baseline. Our work offers a data-efficient approach to capturing both individual and collective behaviors, making it highly applicable to contexts with hierarchical structures. We expect the algorithm to be applicable to other settings with layered nuances of user preferences and information.
PeRP: Personalized Residual Policies For Congestion Mitigation Through Co-operative Advisory Systems
Aug 15, 2023



Intelligent driving systems can be used to mitigate congestion through simple actions, thus improving many socioeconomic factors such as commute time and gas costs. However, these systems assume precise control over autonomous vehicle fleets, and are hence limited in practice as they fail to account for uncertainty in human behavior. Piecewise Constant (PC) Policies address these issues by structurally modeling the likeness of human driving to reduce traffic congestion in dense scenarios to provide action advice to be followed by human drivers. However, PC policies assume that all drivers behave similarly. To this end, we develop a co-operative advisory system based on PC policies with a novel driver trait conditioned Personalized Residual Policy, PeRP. PeRP advises drivers to behave in ways that mitigate traffic congestion. We first infer the driver's intrinsic traits on how they follow instructions in an unsupervised manner with a variational autoencoder. Then, a policy conditioned on the inferred trait adapts the action of the PC policy to provide the driver with a personalized recommendation. Our system is trained in simulation with novel driver modeling of instruction adherence. We show that our approach successfully mitigates congestion while adapting to different driver behaviors, with 4 to 22% improvement in average speed over baselines.