 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnatomy-Aware Unsupervised Detection and Localization of Retinal Abnormalities in Optical Coherence Tomography
Apr 24, 2026Reliable automated analysis of Optical Coherence Tomography (OCT) imaging is crucial for diagnosing retinal disorders but faces a critical barrier: the need for expensive, labor-intensive expert annotations. Supervised deep learning models struggle to generalize across diverse pathologies, imaging devices, and patient populations due to their restricted vocabulary of annotated abnormalities. We propose an unsupervised anomaly detection framework that learns the normative distribution of healthy retinal anatomy without lesion annotations, directly addressing annotation efficiency challenges in clinical deployment. Our approach leverages a discrete latent model trained on normal B-scans to capture OCT-specific structural patterns. To enhance clinical robustness, we incorporate retinal layer-aware supervision and structured triplet learning to separate healthy from pathological representations, improving model reliability across varied imaging conditions. During inference, anomalies are detected and localized via reconstruction discrepancies, enabling both image and pixel-level identification without requiring disease-specific labels. On the Kermany dataset (AUROC: 0.799), our method substantially outperforms VAE, VQVAE, VQGAN, and f-AnoGAN baselines. Critically, cross-dataset evaluation on Srinivasan achieves AUROC 0.884 with superior generalization, demonstrating robust domain adaptation. On the external RETOUCH benchmark, unsupervised anomaly segmentation achieves competitive Dice (0.200) and mIoU (0.117) scores, validating reproducibility across institutions.
Community-Led AI Integration for Wildfire Risk Assessment: A Participatory AI Literacy and Explainability Integration (PALEI) Framework in Los Angeles, CA
Apr 20, 2026Climate-driven wildfires are intensifying, particularly in urban regions such as Southern California. Yet, traditional fire risk communication tools often fail to gain public trust due to inaccessible design, non-transparent outputs, and limited contextual relevance. These challenges are especially critical in high-risk communities, where trust depends on how clearly and locally information is presented. Neighborhoods such as Pacific Palisades, Pasadena, and Altadena in Los Angeles exemplify these conditions. This study introduces a community-led approach for integrating AI into wildfire risk assessment using the Participatory AI Literacy and Explainability Integration (PALEI) framework. PALEI emphasizes early literacy building, value alignment, and participatory evaluation before deploying predictive models, prioritizing clarity, accessibility, and mutual learning between developers and residents. Early engagement findings show strong acceptance of visual, context-specific risk communication, positive fairness perceptions, and clear adoption interest, alongside privacy and data security concerns that influence trust. Participants emphasized localized imagery, accessible explanations, neighborhood-specific mitigation guidance, and transparent communication of uncertainty. The outcome is a mobile application co-designed with users and stakeholders, enabling residents to scan visible property features and receive interpretable fire risk scores with tailored recommendations. By embedding local context into design, the tool becomes an everyday resource for risk awareness and preparedness. This study argues that user experience is central to ethical and effective AI deployment and provides a replicable, literacy-first pathway for applying the PALEI framework to climate-related hazards.
From Frames to Events: Rethinking Evaluation in Human-Centric Video Anomaly Detection
Apr 10, 2026Pose-based Video Anomaly Detection (VAD) has gained significant attention for its privacy-preserving nature and robustness to environmental variations. However, traditional frame-level evaluations treat video as a collection of isolated frames, fundamentally misaligned with how anomalies manifest and are acted upon in the real world. In operational surveillance systems, what matters is not the flagging of individual frames, but the reliable detection, localization, and reporting of a coherent anomalous event, a contiguous temporal episode with an identifiable onset and duration. Frame-level metrics are blind to this distinction, and as a result, they systematically overestimate model performance for any deployment that requires actionable, event-level alerts. In this work, we propose a shift toward an event-centric perspective in VAD. We first audit widely used VAD benchmarks, including SHT[19], CHAD[6], NWPUC[4], and HuVAD[25], to characterize their event structure. We then introduce two strategies for temporal event localization: a score-refinement pipeline with hierarchical Gaussian smoothing and adaptive binarization, and an end-to-end Dual-Branch Model that directly generates event-level detections. Finally, we establish the first event-based evaluation standard for VAD by adapting Temporal Action Localization metrics, including tIoU-based event matching and multi-threshold F1 evaluation. Our results quantify a substantial performance gap: while all SoTA models achieve frame-level AUC-ROC exceeding 52% on the NWPUC[4], their event-level localization precision falls below 10% even at a minimal tIoU=0.2, with an average event-level F1 of only 0.11 across all thresholds. The code base for this work is available at https://github.com/TeCSAR-UNCC/EventCentric-VAD.
From Offline to Periodic Adaptation for Pose-Based Shoplifting Detection in Real-world Retail Security
Mar 05, 2026Shoplifting is a growing operational and economic challenge for retailers, with incidents rising and losses increasing despite extensive video surveillance. Continuous human monitoring is infeasible, motivating automated, privacy-preserving, and resource-aware detection solutions. In this paper, we cast shoplifting detection as a pose-based, unsupervised video anomaly detection problem and introduce a periodic adaptation framework designed for on-site Internet of Things (IoT) deployment. Our approach enables edge devices in smart retail environments to adapt from streaming, unlabeled data, supporting scalable and low-latency anomaly detection across distributed camera networks. To support reproducibility, we introduce RetailS, a new large-scale real-world shoplifting dataset collected from a retail store under multi-day, multi-camera conditions, capturing unbiased shoplifting behavior in realistic IoT settings. For deployable operation, thresholds are selected using both F1 and H_PRS scores, the harmonic mean of precision, recall, and specificity, during data filtering and training. In periodic adaptation experiments, our framework consistently outperformed offline baselines on AUC-ROC and AUC-PR in 91.6% of evaluations, with each training update completing in under 30 minutes on edge-grade hardware, demonstrating the feasibility and reliability of our solution for IoT-enabled smart retail deployment.
Are Multimodal LLMs Ready for Surveillance? A Reality Check on Zero-Shot Anomaly Detection in the Wild
Mar 05, 2026Multimodal large language models (MLLMs) have demonstrated impressive general competence in video understanding, yet their reliability for real-world Video Anomaly Detection (VAD) remains largely unexplored. Unlike conventional pipelines relying on reconstruction or pose-based cues, MLLMs enable a paradigm shift: treating anomaly detection as a language-guided reasoning task. In this work, we systematically evaluate state-of-the-art MLLMs on the ShanghaiTech and CHAD benchmarks by reformulating VAD as a binary classification task under weak temporal supervision. We investigate how prompt specificity and temporal window lengths (1s--3s) influence performance, focusing on the precision--recall trade-off. Our findings reveal a pronounced conservative bias in zero-shot settings; while models exhibit high confidence, they disproportionately favor the 'normal' class, resulting in high precision but a recall collapse that limits practical utility. We demonstrate that class-specific instructions can significantly shift this decision boundary, improving the peak F1-score on ShanghaiTech from 0.09 to 0.64, yet recall remains a critical bottleneck. These results highlight a significant performance gap for MLLMs in noisy environments and provide a foundation for future work in recall-oriented prompting and model calibration for open-world surveillance, which demands complex video understanding and reasoning.
A Survey on Video Anomaly Detection via Deep Learning: Human, Vehicle, and Environment
Aug 19, 2025


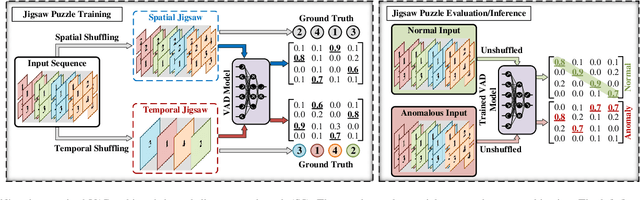
Video Anomaly Detection (VAD) has emerged as a pivotal task in computer vision, with broad relevance across multiple fields. Recent advances in deep learning have driven significant progress in this area, yet the field remains fragmented across domains and learning paradigms. This survey offers a comprehensive perspective on VAD, systematically organizing the literature across various supervision levels, as well as adaptive learning methods such as online, active, and continual learning. We examine the state of VAD across three major application categories: human-centric, vehicle-centric, and environment-centric scenarios, each with distinct challenges and design considerations. In doing so, we identify fundamental contributions and limitations of current methodologies. By consolidating insights from subfields, we aim to provide the community with a structured foundation for advancing both theoretical understanding and real-world applicability of VAD systems. This survey aims to support researchers by providing a useful reference, while also drawing attention to the broader set of open challenges in anomaly detection, including both fundamental research questions and practical obstacles to real-world deployment.
ALFred: An Active Learning Framework for Real-world Semi-supervised Anomaly Detection with Adaptive Thresholds
Aug 12, 2025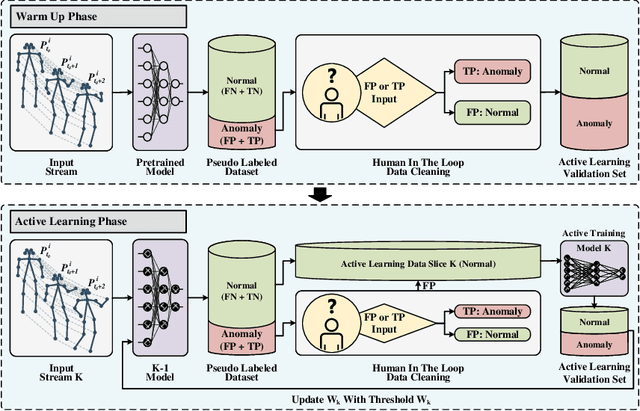
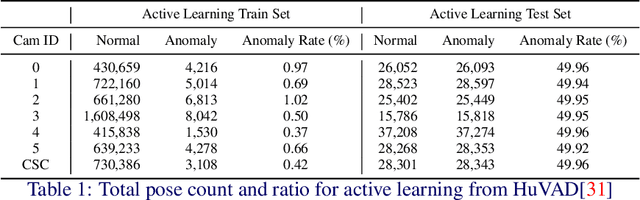
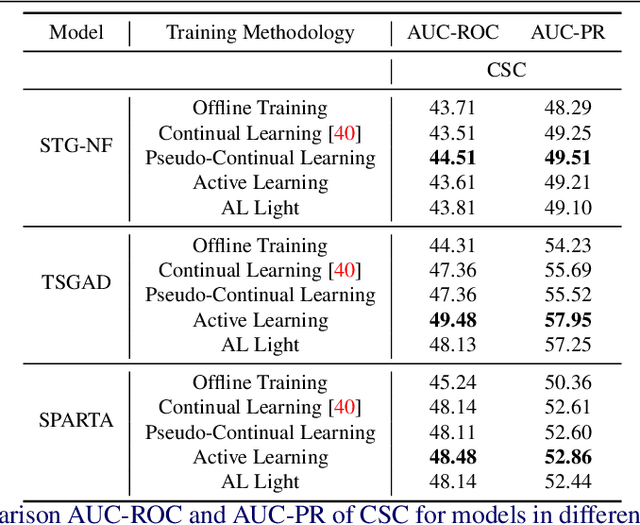
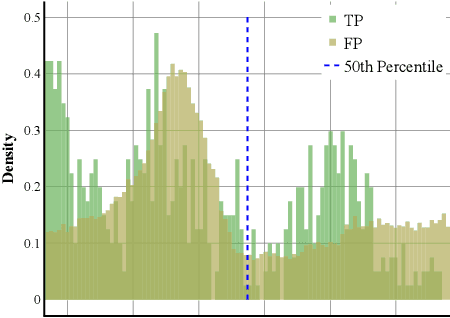
Video Anomaly Detection (VAD) can play a key role in spotting unusual activities in video footage. VAD is difficult to use in real-world settings due to the dynamic nature of human actions, environmental variations, and domain shifts. Traditional evaluation metrics often prove inadequate for such scenarios, as they rely on static assumptions and fall short of identifying a threshold that distinguishes normal from anomalous behavior in dynamic settings. To address this, we introduce an active learning framework tailored for VAD, designed for adapting to the ever-changing real-world conditions. Our approach leverages active learning to continuously select the most informative data points for labeling, thereby enhancing model adaptability. A critical innovation is the incorporation of a human-in-the-loop mechanism, which enables the identification of actual normal and anomalous instances from pseudo-labeling results generated by AI. This collected data allows the framework to define an adaptive threshold tailored to different environments, ensuring that the system remains effective as the definition of 'normal' shifts across various settings. Implemented within a lab-based framework that simulates real-world conditions, our approach allows rigorous testing and refinement of VAD algorithms with a new metric. Experimental results show that our method achieves an EBI (Error Balance Index) of 68.91 for Q3 in real-world simulated scenarios, demonstrating its practical effectiveness and significantly enhancing the applicability of VAD in dynamic environments.
MoCLIP: Motion-Aware Fine-Tuning and Distillation of CLIP for Human Motion Generation
May 16, 2025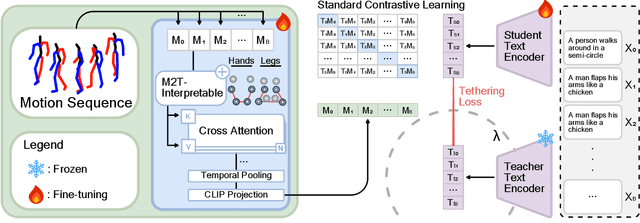

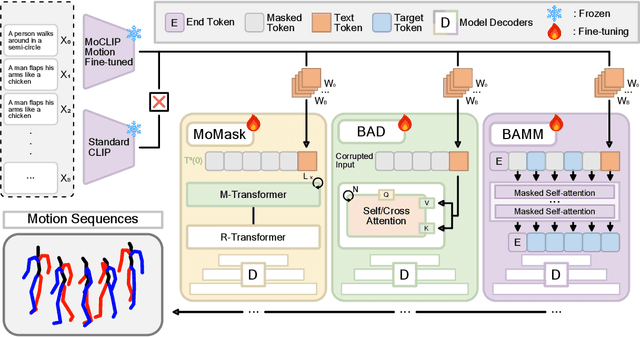
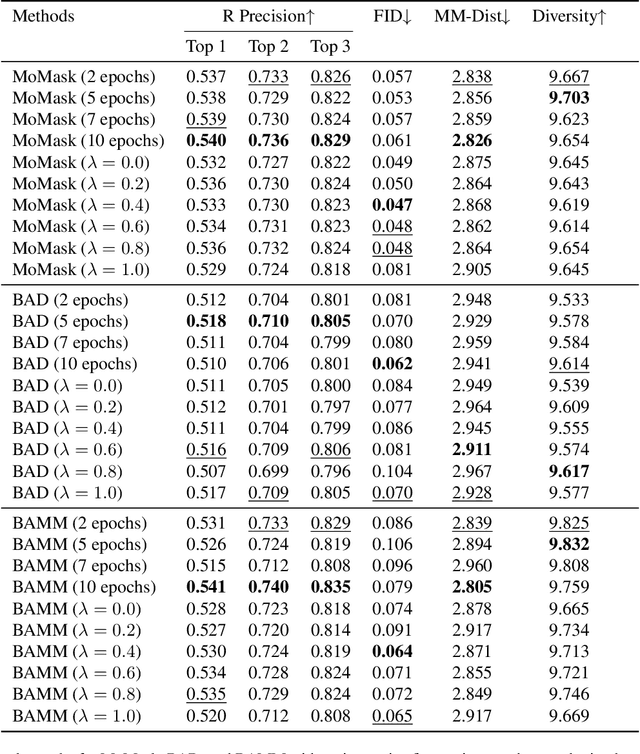
Human motion generation is essential for fields such as animation, robotics, and virtual reality, requiring models that effectively capture motion dynamics from text descriptions. Existing approaches often rely on Contrastive Language-Image Pretraining (CLIP)-based text encoders, but their training on text-image pairs constrains their ability to understand temporal and kinematic structures inherent in motion and motion generation. This work introduces MoCLIP, a fine-tuned CLIP model with an additional motion encoding head, trained on motion sequences using contrastive learning and tethering loss. By explicitly incorporating motion-aware representations, MoCLIP enhances motion fidelity while remaining compatible with existing CLIP-based pipelines and seamlessly integrating into various CLIP-based methods. Experiments demonstrate that MoCLIP improves Top-1, Top-2, and Top-3 accuracy while maintaining competitive FID, leading to improved text-to-motion alignment results. These results highlight MoCLIP's versatility and effectiveness, establishing it as a robust framework for enhancing motion generation.
Shopformer: Transformer-Based Framework for Detecting Shoplifting via Human Pose
Apr 28, 2025Shoplifting remains a costly issue for the retail sector, but traditional surveillance systems, which are mostly based on human monitoring, are still largely ineffective, with only about 2% of shoplifters being arrested. Existing AI-based approaches rely on pixel-level video analysis which raises privacy concerns, is sensitive to environmental variations, and demands significant computational resources. To address these limitations, we introduce Shopformer, a novel transformer-based model that detects shoplifting by analyzing pose sequences rather than raw video. We propose a custom tokenization strategy that converts pose sequences into compact embeddings for efficient transformer processing. To the best of our knowledge, this is the first pose-sequence-based transformer model for shoplifting detection. Evaluated on real-world pose data, our method outperforms state-of-the-art anomaly detection models, offering a privacy-preserving, and scalable solution for real-time retail surveillance. The code base for this work is available at https://github.com/TeCSAR-UNCC/Shopformer.
MoFM: A Large-Scale Human Motion Foundation Model
Feb 08, 2025



AFoundation Models (FM) have increasingly drawn the attention of researchers due to their scalability and generalization across diverse tasks. Inspired by the success of FMs and the principles that have driven advancements in Large Language Models (LLMs), we introduce MoFM as a novel Motion Foundation Model. MoFM is designed for the semantic understanding of complex human motions in both time and space. To facilitate large-scale training, MotionBook, a comprehensive human motion dictionary of discretized motions is designed and employed. MotionBook utilizes Thermal Cubes to capture spatio-temporal motion heatmaps, applying principles from discrete variational models to encode human movements into discrete units for a more efficient and scalable representation. MoFM, trained on a large corpus of motion data, provides a foundational backbone adaptable to diverse downstream tasks, supporting paradigms such as one-shot, unsupervised, and supervised tasks. This versatility makes MoFM well-suited for a wide range of motion-based applications.