 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-OCT-SelfNet: Integrating Self-Supervised Learning with Multi-Source Data Fusion for Enhanced Multi-Class Retinal Disease Classification
Paper and Code
Sep 17, 2024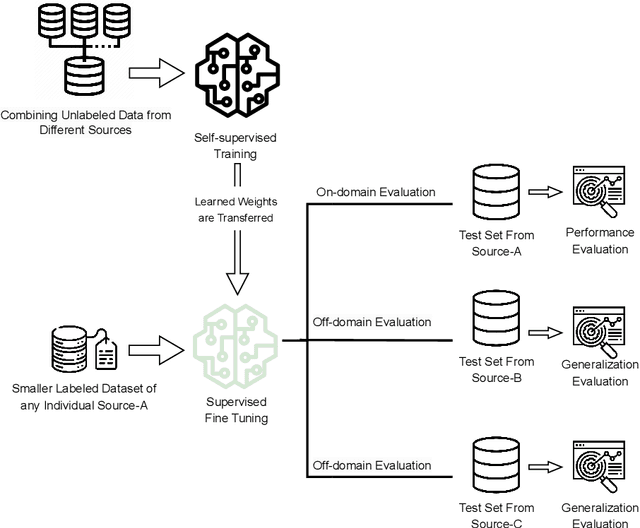
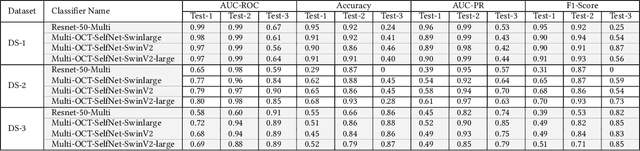
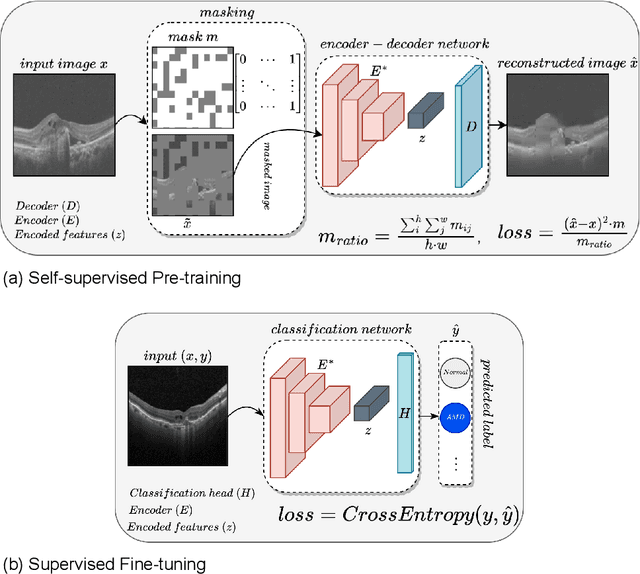
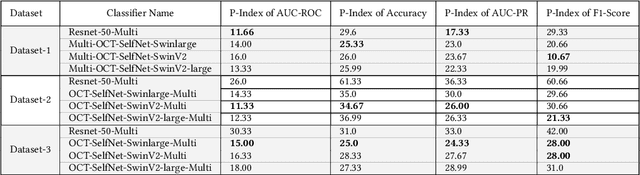
In the medical domain, acquiring large datasets poses significant challenges due to privacy concerns. Nonetheless, the development of a robust deep-learning model for retinal disease diagnosis necessitates a substantial dataset for training. The capacity to generalize effectively on smaller datasets remains a persistent challenge. The scarcity of data presents a significant barrier to the practical implementation of scalable medical AI solutions. To address this issue, we've combined a wide range of data sources to improve performance and generalization to new data by giving it a deeper understanding of the data representation from multi-modal datasets and developed a self-supervised framework based on large language models (LLMs), SwinV2 to gain a deeper understanding of multi-modal dataset representations, enhancing the model's ability to extrapolate to new data for the detection of eye diseases using optical coherence tomography (OCT) images. We adopt a two-phase training methodology, self-supervised pre-training, and fine-tuning on a downstream supervised classifier. An ablation study conducted across three datasets employing various encoder backbones, without data fusion, with low data availability setting, and without self-supervised pre-training scenarios, highlights the robustness of our method. Our findings demonstrate consistent performance across these diverse conditions, showcasing superior generalization capabilities compared to the baseline model, ResNet-50.