 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-OCT-SelfNet: Integrating Self-Supervised Learning with Multi-Source Data Fusion for Enhanced Multi-Class Retinal Disease Classification
Sep 17, 2024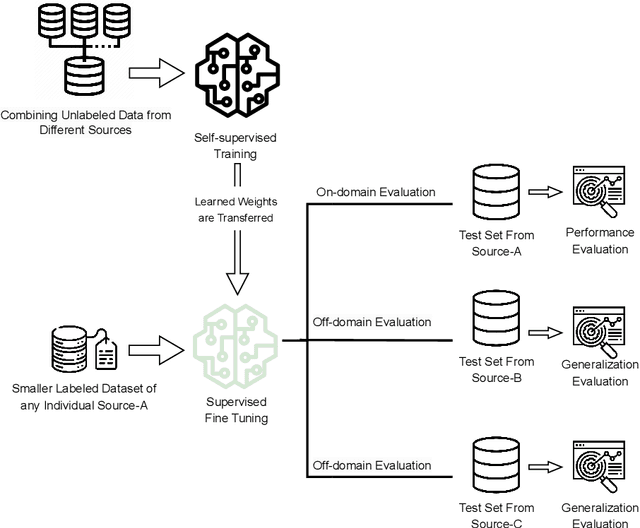
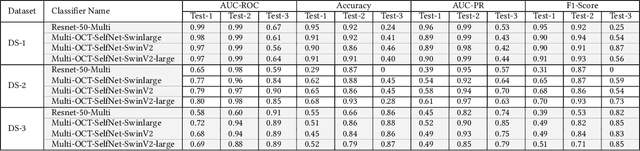
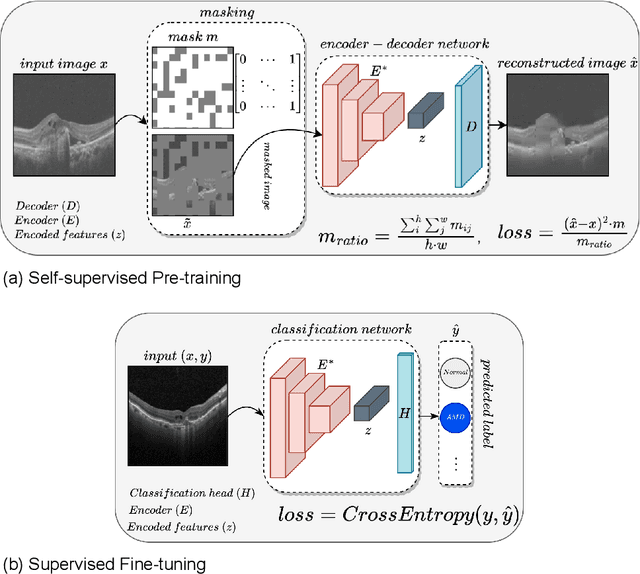
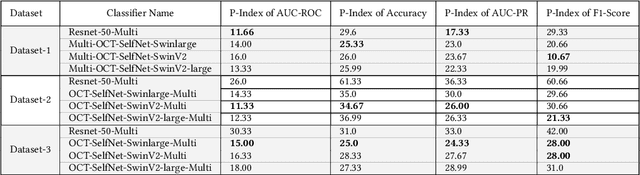
In the medical domain, acquiring large datasets poses significant challenges due to privacy concerns. Nonetheless, the development of a robust deep-learning model for retinal disease diagnosis necessitates a substantial dataset for training. The capacity to generalize effectively on smaller datasets remains a persistent challenge. The scarcity of data presents a significant barrier to the practical implementation of scalable medical AI solutions. To address this issue, we've combined a wide range of data sources to improve performance and generalization to new data by giving it a deeper understanding of the data representation from multi-modal datasets and developed a self-supervised framework based on large language models (LLMs), SwinV2 to gain a deeper understanding of multi-modal dataset representations, enhancing the model's ability to extrapolate to new data for the detection of eye diseases using optical coherence tomography (OCT) images. We adopt a two-phase training methodology, self-supervised pre-training, and fine-tuning on a downstream supervised classifier. An ablation study conducted across three datasets employing various encoder backbones, without data fusion, with low data availability setting, and without self-supervised pre-training scenarios, highlights the robustness of our method. Our findings demonstrate consistent performance across these diverse conditions, showcasing superior generalization capabilities compared to the baseline model, ResNet-50.
Quantitative Characterization of Retinal Features in Translated OCTA
Apr 24, 2024
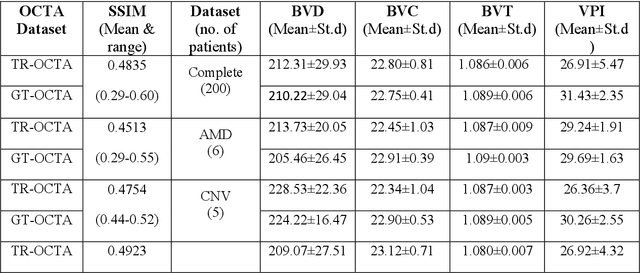

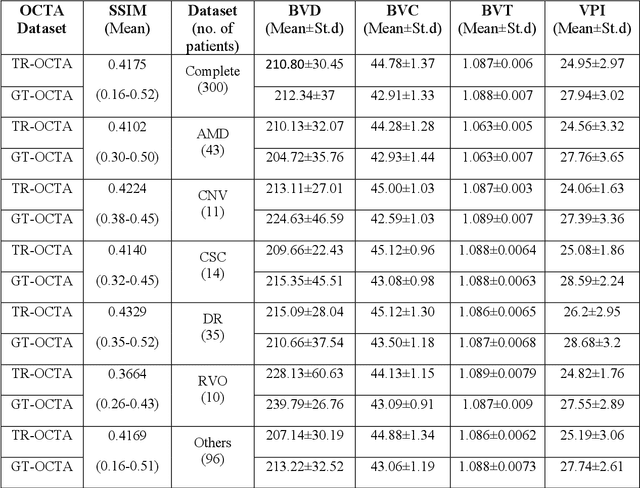
Purpose: This study explores the feasibility of using generative machine learning (ML) to translate Optical Coherence Tomography (OCT) images into Optical Coherence Tomography Angiography (OCTA) images, potentially bypassing the need for specialized OCTA hardware. Methods: The method involved implementing a generative adversarial network framework that includes a 2D vascular segmentation model and a 2D OCTA image translation model. The study utilizes a public dataset of 500 patients, divided into subsets based on resolution and disease status, to validate the quality of TR-OCTA images. The validation employs several quality and quantitative metrics to compare the translated images with ground truth OCTAs (GT-OCTA). We then quantitatively characterize vascular features generated in TR-OCTAs with GT-OCTAs to assess the feasibility of using TR-OCTA for objective disease diagnosis. Result: TR-OCTAs showed high image quality in both 3 and 6 mm datasets (high-resolution, moderate structural similarity and contrast quality compared to GT-OCTAs). There were slight discrepancies in vascular metrics, especially in diseased patients. Blood vessel features like tortuosity and vessel perimeter index showed a better trend compared to density features which are affected by local vascular distortions. Conclusion: This study presents a promising solution to the limitations of OCTA adoption in clinical practice by using vascular features from TR-OCTA for disease detection. Translation relevance: This study has the potential to significantly enhance the diagnostic process for retinal diseases by making detailed vascular imaging more widely available and reducing dependency on costly OCTA equipment.
Contrastive learning-based pretraining improves representation and transferability of diabetic retinopathy classification models
Aug 24, 2022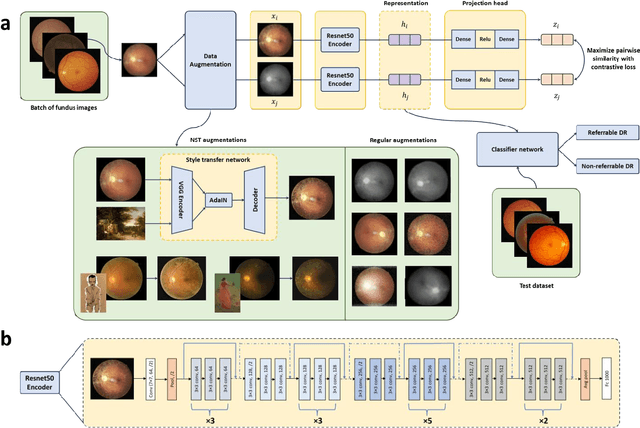

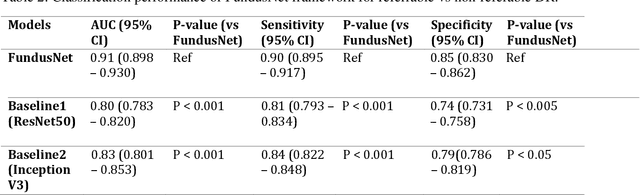
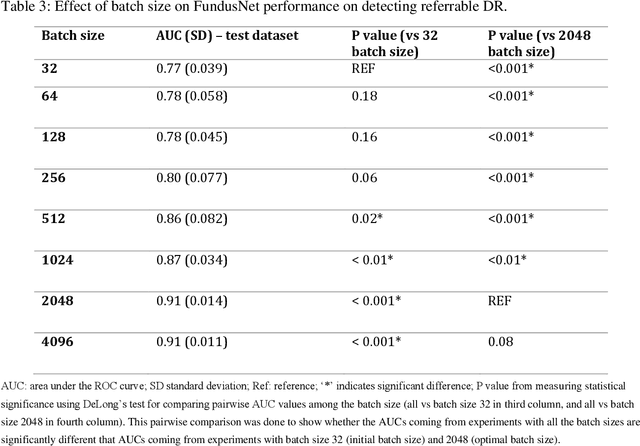
Self supervised contrastive learning based pretraining allows development of robust and generalized deep learning models with small, labeled datasets, reducing the burden of label generation. This paper aims to evaluate the effect of CL based pretraining on the performance of referrable vs non referrable diabetic retinopathy (DR) classification. We have developed a CL based framework with neural style transfer (NST) augmentation to produce models with better representations and initializations for the detection of DR in color fundus images. We compare our CL pretrained model performance with two state of the art baseline models pretrained with Imagenet weights. We further investigate the model performance with reduced labeled training data (down to 10 percent) to test the robustness of the model when trained with small, labeled datasets. The model is trained and validated on the EyePACS dataset and tested independently on clinical data from the University of Illinois, Chicago (UIC). Compared to baseline models, our CL pretrained FundusNet model had higher AUC (CI) values (0.91 (0.898 to 0.930) vs 0.80 (0.783 to 0.820) and 0.83 (0.801 to 0.853) on UIC data). At 10 percent labeled training data, the FundusNet AUC was 0.81 (0.78 to 0.84) vs 0.58 (0.56 to 0.64) and 0.63 (0.60 to 0.66) in baseline models, when tested on the UIC dataset. CL based pretraining with NST significantly improves DL classification performance, helps the model generalize well (transferable from EyePACS to UIC data), and allows training with small, annotated datasets, therefore reducing ground truth annotation burden of the clinicians.
A Deep-learning Approach for Prognosis of Age-Related Macular Degeneration Disease using SD-OCT Imaging Biomarkers
Feb 27, 2019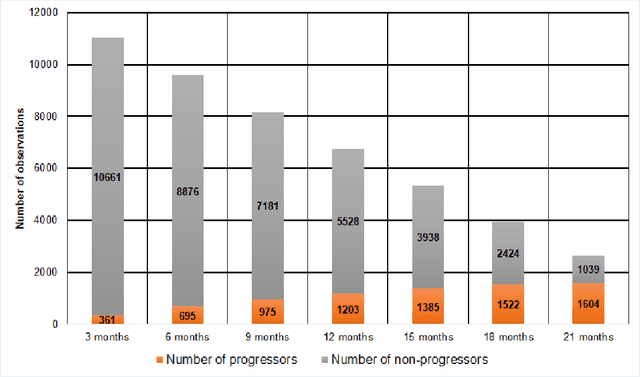
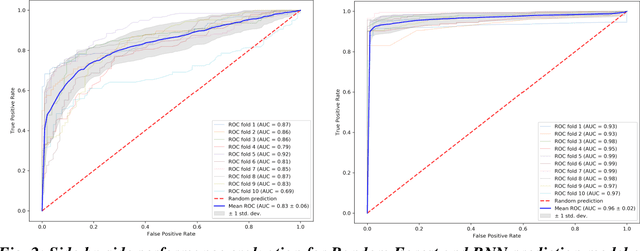
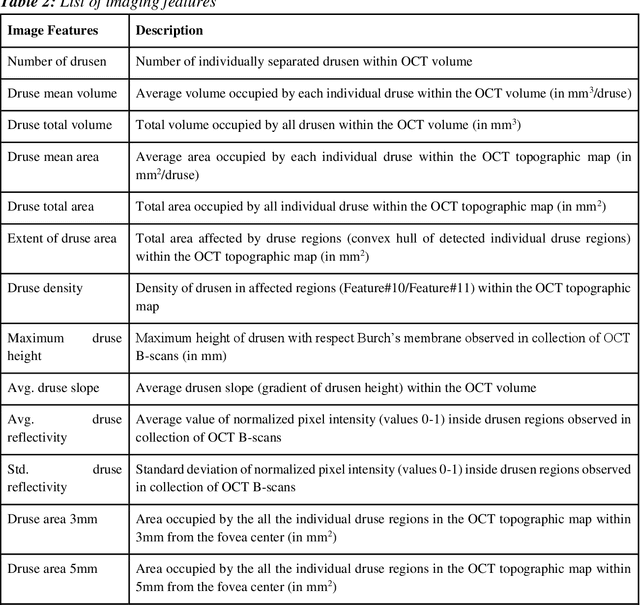
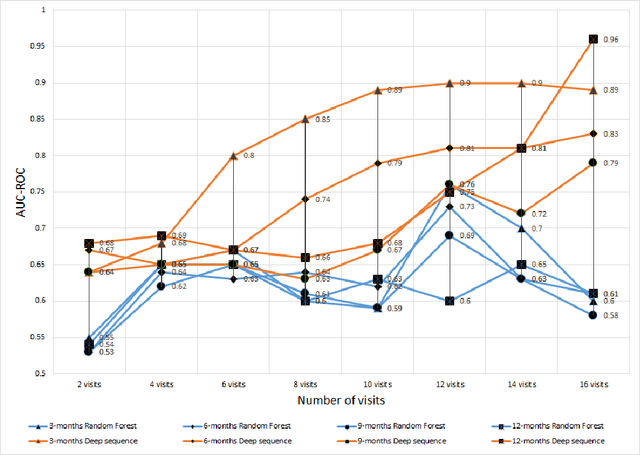
We propose a hybrid sequential deep learning model to predict the risk of AMD progression in non-exudative AMD eyes at multiple timepoints, starting from short-term progression (3-months) up to long-term progression (21-months). Proposed model combines radiomics and deep learning to handle challenges related to imperfect ratio of OCT scan dimension and training cohort size. We considered a retrospective clinical trial dataset that includes 671 fellow eyes with 13,954 dry AMD observations for training and validating the machine learning models on a 10-fold cross validation setting. The proposed RNN model achieved high accuracy (0.96 AUCROC) for the prediction of both short term and long-term AMD progression, and outperformed the traditional random forest model trained. High accuracy achieved by the RNN establishes the ability to identify AMD patients at risk of progressing to advanced AMD at an early stage which could have a high clinical impact as it allows for optimal clinical follow-up, with more frequent screening and potential earlier treatment for those patients at high risk.